一种基于亚音频特征判断的啸叫消除方法与流程
本发明涉及语音增强领域,尤其是涉及自适应回声消除领域的技术
背景技术:
在一些使用通信设备的场景,例如中央控制室,多个用户在一个封闭的空间里使用不同的设备在同一个频道上免提通话。如果环境噪声大的话,用户可能会把音量调的很大,这最终会导致一个设备里播放出来的声音最终会被另外一个设备的麦克风采集到并且传播出去。如果这两个设备的距离足够近的话,那么这个声音回路会形成一个正反馈,声音会被持续放大,最后形成啸叫。如图1所示,假设这里有三个增益g1,g2,g3。g1代表接受设备本身对音频的增益,g2代表音频空气传输的增益,g3代表发射设备本身对音频的增益。如果g1*g2*g3>1,那么啸叫就会产生。啸叫在实际应用中会严重影响声音的辨识度和可懂度。设备靠的越近,啸叫就会越容易产生,也更会影响语音质量。
本文的下一节会描述本文提出的发明是如何有效的检测啸叫并有效的压制啸叫。
技术实现要素:
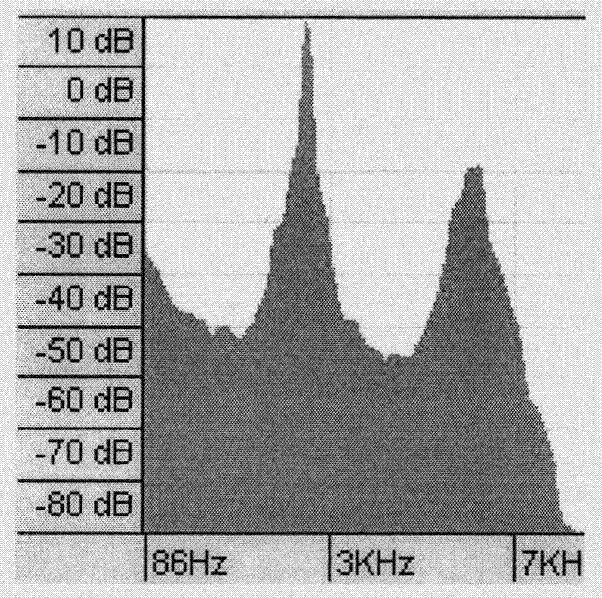
无论模拟电台还是数字电台,音频在到达喇叭播放之前,都会经过一个300hz的高通滤波器,该滤波器会滤除掉300hz的频率。这样做是因为,300hz以下的频带用以传输低速信令。而区别于电台喇叭播放的声音,自然界里的声音,其300hz以下或多或少存在这能量。下图图2表示了喇叭播放出来的能量谱,图3为自然界音频的能量谱。
在下面的发明描述里,我们考虑到了实际上发送设备麦克风采集到的音频会混合了喇叭出来的音频和自然界的音频能量,因为这会影响亚音频里的能量特征。
如果我们把音频能量谱分为两个部分,亚音频能量e1,剩余音频能量e2,那么总能量可以表示为:
e=e1+e2
现在我们来考虑两种场景:第一,发送设备麦克风捕捉到的音频能量全部来自于喇叭播放的音频,第二,发送设备麦克风捕捉到的音频能量全部来自于自然界音频。
如果用亚音频的能量去除以总音频能量,就可以得到一个比值r=e1/(e1+e2)。
假设第一个场景里得到的比值为r1,第二个场景得到的比值为r2。通过大量实验,我们发现。
r1<<r2。如图4和图5所示
考虑到发送设备麦克风里收到的音频常常混合了喇叭播放的音频以及自然界音频能量。如果用rm来表示这种状况下的亚音频与非亚音频能量的比值,该值的大小将会介于r1与r2大小之间。
r1<rm<r2。
本发明通过大量实验,找到门限值0.076294来区分是否是自然语音。
图6标明了本发明在一个音频通路中所处的位置。图7里标明了啸叫抑制算法的模块组成部分。
啸叫抑制完整的计算步骤如图8所示。
1.音频输入的采样率为8khz,每一个输入音频数据模块为160个采样点;
2.输入音频经过300hz的低通滤波器;
3.计算300hz低通滤波器输出的能量;
4.计算信号的总输出能量;
5.计算亚音频能量与总能量输出的比率;
6.平滑比率;
7.每16个数据块比较一次门限,这里检查是否到了16个数据块;
8.将平滑后的比率值与门限0.0762939453125进行比较,如果大于门限,就计算子频带上的增益值,bandi为一个16个值的数组,这里给出具体数值为{1,1,1,1,1,0.9,0.8,0.88,0.89,0.9,0.9,0.9,0.9,0.8,0.8,0.8,0.8},如果比率小于门限,子带上的增益统一为1;
9.将信号做fft变换到频域,然后从300hz到3300hz等间隔划分16个子带;
10.在频域上对音频的各个频带采用不同的增益值进行衰减;
11.做ifft变换回时域;
12.重置数据块计数变量;
附图说明
图1为声音传播增益;
图2为喇叭播放出声音能量谱;
图3为自然界声音能量谱;
图4为喇叭里播放的音频时域图以及其r比值变化;
图5为喇叭里播放的音频时域图以及其r比值变化;
图6为啸叫抑制在音频处理模块中所处位置;
图7为啸叫抑制组成模块;
图8为啸叫抑制完整步骤。
技术特征:
技术总结
本文提出了一种基于亚音频特征判断的啸叫消除方法。在模拟或者数字音频处理系统里,在声音被播放出来之前,通常会加上一个300Hz截至的高通滤波器来滤除掉亚音频。这导致最终从喇叭里播放出来的声音里,300Hz的音频能量会非常低,这个特征明显不同于自然界里的声音。本文提出了使用这种特征来快速检测啸叫,并且抑制的方法。
技术研发人员:韩建
受保护的技术使用者:成都易慧通科技有限公司
技术研发日:2017.02.17
技术公布日:2017.07.25
- 还没有人留言评论。精彩留言会获得点赞!