基于卷积神经网络的监控视频中人车目标分类方法与流程
本发明涉及一种基于卷积神经网络的监控视频中人车目标分类方法,属于模式识别技术领域。
背景技术:
随着社会的不断发展,公共安全防范已经成为城市现代化的重要基础,视频监控系统作为安全防范系统的重要组成部分,发挥着重要的作用,在城市道路交通领域,广泛使用视频监控系统实时记录人、车的交通行为,利用卷积神经网络识别监控视频中的人、车等目标,能够极大的提高各类交通案件的处置效率。现有的监控视频中人车分类方法,分类精度不高,且实时性不够强。
技术实现要素:
鉴于上述原因,本发明的目的在于提供一种基于卷积神经网络的监控视频中人车目标分类方法,利用多角度的样本图片对卷积神经网络进行有针对性的训练、调整,能够达到较高的人车分类准确率。
为实现上述目的,本发明采用以下技术方案:
一种基于卷积神经网络的监控视频中人车目标分类方法,包括:
s1:获取多角度性的样本集,并将样本集划分为训练样本集、验证样本集和测试样本集;
s2:建立卷积神经网络;
s3:将训练样本集中的样本图片先减去每个像素点对应的均值,然后作为训练数据输入该卷积神经网络,进行有监督的学习,得到训练后的卷积神经网络的各层的参数;
s4:利用训练后的卷积神经网络的各层的参数,初始化与步骤s2中所述卷积神经网络结构相同的卷积神经网络,得到具有监控视频中人车目标分类功能的图像识别网络。
所述步骤s1中,所述多角度性的样本集的获取方法是:
采集大量的监控视频中的人、车、非人非车的图片,将所有图片缩放到同等像素大小的图片,在所有图片中添加用于区别人、车、非人非车图片的标签,对所有图片进行镜像、旋转处理。
所述步骤s2中的卷积神经网络包括两个卷积层、两个下采样层,一个全 连接层,及softmax分类器,第一卷积层滤波器的大小为5×5像素,特征图为6个,第一下采样层滤波器的大小为2×2像素,特征图为6个,第二卷积层滤波器的大小为5×5像素,特征图为16个,第二下采样层滤波器的大小为2×2像素,特征图为16个,全连接层的特征图为120个,softmax分类器输出三种类型的目标:人、车、其他。
对所有图片进行水平镜像处理,然后沿水平方向旋转10度。
本发明的优点是:
1、采集大量的监控视频中的图片,并对图片进行预处理,增加了不同样本图片之间的差异性,在此基础上对卷积神经网络进行有针对性的训练、调整,能够达到较高的分类准确率,保证了分类过程的实时性;
2、采用机器自学习的方法,减少了人为干预,使卷积神经网络能够学习到全面的人车特征,网络的泛化能力强。
附图说明
图1是本发明的卷积神经网络的结构示意图。
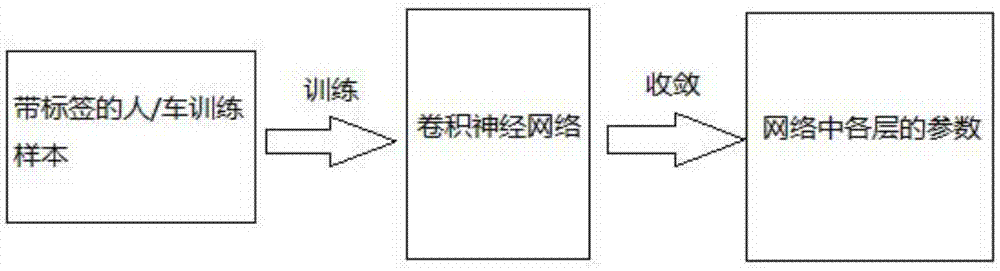
图2是本发明的卷积神经网络的训练过程图。
图3是利用本发明的卷积神经网络进行分类的过程图。
具体实施方式
如图1至3所示,本发明公开的基于卷积神经网络的监控视频中人车目标分类方法,包括以下步骤:
s1:获取样本集,并将样本集划分为训练样本集、验证样本集和测试样本集;
采集大量的监控视频中的人、车、非人非车的图片,将所有图片缩放到32×32像素大小,对所有图片于每个像素点进行平均值计算,并在所有图片中添加标签,例如,在有人的图片中添加0,在有车的图片中添加1,在非人非车的图片中添加2;
之后,对所有图片进行预处理后作为样本图片,预处理包括图片的镜像、旋转处理,镜像方式为水平镜像,旋转角度为沿水平方向旋转10度;预处理后得到的样本图片具有全面、丰富的多角度特征,且增大了不同样本图片(人、车、其他)之间的差异性。
将所有样本图片分成训练样本集(占总样本的85%)、验证样本集(占总样本的10%)和测试样本集(占总样本的5%)。
s2:建立卷积神经网络;
如图1所示,本发明建立的卷积神经网络包括两个卷积层、两个下采样层,一个全连接层,及softmax分类器。第一卷积层滤波器的大小为5×5像素,特征图为6个,第一下采样层滤波器的大小为2×2像素,特征图为6个,第二卷积层滤波器的大小为5×5像素,特征图为16个,第二下采样层滤波器的大小为2×2像素,特征图为16个,全连接层的特征图为120个,softmax分类器输出三种类型的目标:人、车、其他。
s3:将训练样本集中的样本图片先减去每个像素点对应的均值,然后作为训练数据输入卷积神经网络,进行带标签的有监督的学习,得到训练后的卷积神经网络的各层的参数;
训练过程中,采用随机梯度下降法调整卷积神经网络中各层的参数,观察卷积神经网络在验证样本集上的准确率变化,并调整卷积神经网络的学习率,确保卷积神经网络在训练样本集上收敛并在验证样本集上达到较高的分类准确率,当卷积神经网络收敛后(准确率达到设定的阈值),保存卷积神经网络中各层的参数。
s4:利用训练后的卷积神经网络的各层的参数,初始化同样结构的卷积神经网络,得到具有监控视频中人车目标分类功能的图像识别网络。
后续即可利用该图像识别网络对测试样本集进行测试、分类。
于一具体实施例中,使用的训练样本集大小为24000张身份证照片,验证样本集的大小为2823张身份证照片,测试样本集的大小为1411张监控视频中的人、车、非人非车的图片,测试前,先将测试样本集的样本图片减去每个像素对应的均值,然后输入图像识别网络,最终该图像识别网络在测试样本集上的分类准确率达到了86%,由于样本图片具有多角度性,因而分类准确率较高。
以上所述是本发明的较佳实施例及其所运用的技术原理,对于本领域的技术人员来说,在不背离本发明的精神和范围的情况下,任何基于本发明技术方案基础上的等效变换、简单替换等显而易见的改变,均属于本发明保护范围之内。
技术特征:
技术总结
本发明公开一种基于卷积神经网络的监控视频中人车目标分类方法,包括:获取多角度性的样本集,并将样本集划分为训练样本集、验证样本集和测试样本集;建立卷积神经网络;将训练样本集中的样本图片先减去每个像素点对应的均值,然后作为训练数据输入该卷积神经网络,进行有监督的学习,得到训练后的卷积神经网络的各层的参数;利用训练后的卷积神经网络的各层的参数,初始化相同结构的卷积神经网络,得到具有监控视频中人车目标分类功能的图像识别网络。本发明利用多角度的样本图片对卷积神经网络进行有针对性的训练、调整,能够达到较高的人车分类准确率。
技术研发人员:付景林;孟汉峰;侯玉成;张新中;王芊;丁明锋;鞠秀芳;柳炯;李永丰;王允升;杨永强;姜晓伟
受保护的技术使用者:北京大唐高鸿软件技术有限公司
技术研发日:2015.12.29
技术公布日:2017.07.07
- 还没有人留言评论。精彩留言会获得点赞!