基于蚁群的模糊c均值算法实现关键词优化的制作方法
本发明涉及语义网络技术领域,具体涉及一种基于蚁群的模糊c均值算法实现关键词优化。
背景技术:
随着互联网技术不断发展,网络信息量迅速增长,搜索引擎逐渐成为用户快速准确查找信息的主要工具。很多企业尤其是中小型企业为了使自己的网站排名靠前,选择了成本低,操作容易,符合用户搜索偏好的搜索引擎优化方式。目前关于搜索引擎优化方法的理论研究已较为丰富,但借助实证去分析搜索引擎优化方法带来的效果的却很少。如何获得较好的搜索引擎自然排名,增加网站的曝光率与转化率,最终实现直接销售,是中小企业普遍关注的焦点问题。搜索引擎优化(SEO)是指在搜索引擎许可的优化原则下,通过对网站中代码链接和文字描述的重组优化,以及后期对网站进行合理的反向链接操作,最终实现被优化的网站在搜索引擎的检索结果中得到排名提升。而搜索引擎优化中,关键词优化策略尤为重要,关键词始终贯穿于搜索引擎优化的整个过程。关键词的使用是否得当,直接关系到网站在搜索引擎的搜索结果中的位置。基于上述需求,本发明提供了基于蚁群的模糊c均值算法实现关键词优化。
技术实现要素:
针对于关键词优化实现搜索引擎优化的技术问题,本发明提供了一种基于蚁群的模糊c均值算法实现关键词优化。
为了解决上述问题,本发明是通过以下技术方案实现的:
步骤1:根据企业业务确定核心关键词,利用搜索引擎搜集相关关键字,这些关键字在搜索引擎中有相应数据项,如本国每月搜索量、竞争程度和估算每次点击费用(CPC)等
步骤2:结合企业产品和市场分析,筛选降维上述搜索到的相关关键字集合;
步骤3:针对筛选降维后的关键词集合,通过搜索引擎搜索关键词对应的页面,这里记录首页网页数和总搜索页面数,即每个关键词就是一个五维向量;
步骤4:基于蚁群的模糊c均值算法,对上述关键词进行聚类处理,其具体子步骤如下:
步骤4.1:初始化迭代次数nc=0,根据k-means中心聚类算法初始化各个关键词信息量为Iijstart,初始化为c类。
步骤4.2:用值[0,1]间的随机数初始化隶属矩阵J,使其满足隶属的整个约束条件。
步骤4.3:初始化每一个领域目标函数构建c类总目标函数综合隶属约束条件,构建m个方程组,对其进行求解,即可求出使总目标函数最大的必要条件cj、wij。
步骤4.4:根据判定函数Δ(f)的大小来确定。
步骤4.5:根据最佳聚类的结果,找到信息量最大的那一类,即为通过优化后需要的关键词;
步骤5:根据企业具体情况,综合关键词效能优化和价值率优化,选择合适的关键词优化策略达到网站优化目标。
本发明有益效果是:
1,此算法易于并行实现,同时也避免其早熟性收敛。
2,此算法的运行时间复杂度低,处理速度更快。
3、此算法具有更大的利用价值。
5、在k-means算法的基础上,此算法分类的结果更加准确,更符合经验值。
6、能帮助网站在短时间内快速提升其关键词的排名。
7、为企业网站带来一定的流量和询盘,从而达到理想的网站优化目标。
8、结合蚁群活动规律与k-means聚类算法,数据结果更具有科学性。
9、根据信息量筛选出最佳的那一类,得到的结果更加直观。
附图说明
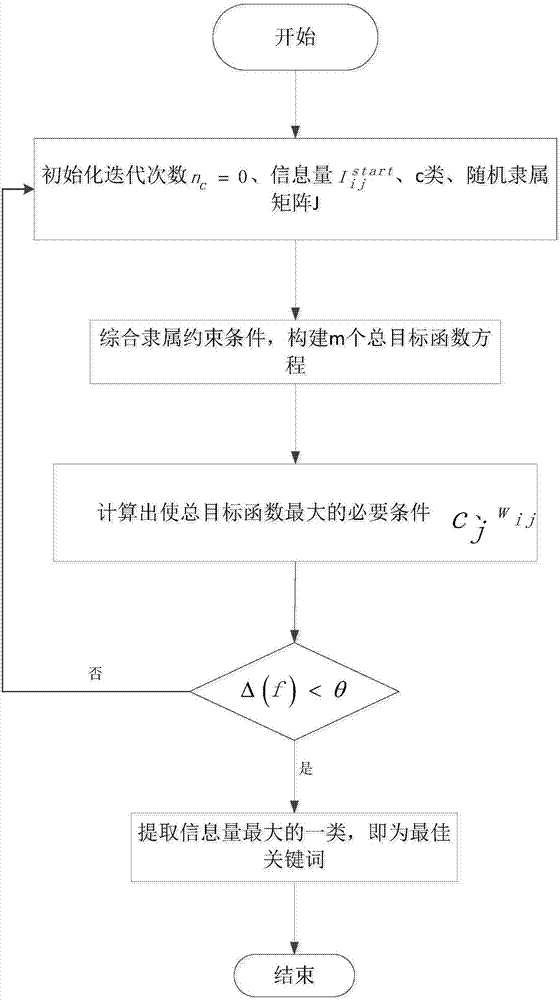
图1基于蚁群的模糊c均值算法实现关键词优化结构流程图
图2基于蚁群的模糊c均值算法在聚类分析中的应用流程图
具体实施方式
为了解决关键词优化实现搜索引擎优化的技术问题,结合图1对本发明进行了详细说明,其具体实施步骤如下:
步骤1:根据企业业务确定核心关键词,利用搜索引擎搜集相关关键字,这些关键字在搜索引擎中有相应数据项,如本国每月搜索量、竞争程度和估算每次点击费用(CPC)等。
步骤2:结合企业产品和市场分析,筛选降维上述搜索到的相关关键字集合;
步骤3:针对筛选降维后的关键词集合,通过搜索引擎搜索关键词对应的页面,这里记录首页网页数和总搜索页面数,即每个关键词由五维向量再降维为四维的,其具体描述如下:
这里相关关键词个数为m,既有下列m×5矩阵:
Ni、Ldi、CPCi、NiS、NiY依次为第i个关键词对应的本国每月搜索量、竞争程度、估算每次点击费用(CPC)、首页网页数、总搜索页面数。
再降维为四维,即
Xi∈(1,2,…,m)为搜索效能,Zi∈(1,2,…,m)为价值率,即为下式:
步骤4:基于蚁群的模糊c均值算法,对上述关键词进行聚类处理,其具体子步骤如下:
步骤4.1:初始化迭代次数nc=0,根据k-means中心聚类算法初始化各个关键词信息量为Iijstart,初始化为c类。
步骤4.2:用值[0,1]间的随机数初始化隶属矩阵J,使其满足隶属的整个约束条件,其具体计算过程如下:
初始化隶属矩阵J为m×c:
wij为关键词i属于j类的程度系数,即j∈(1,2,…,c)、i∈(1,2,…,m)。
隶属的整个约束条件为:
步骤4.3:初始化每一个领域目标函数构建c类总目标函数综合隶属约束条件,构建m个方程组,对其进行求解,即可求出使总目标函数最大的必要条件cj、wij,其具体计算过程如下:
c类总目标函数
上式A为平滑处理系数。
新的关键词信息量IijNEW:
上式IijNEW为聚类为j类的信息量,c为聚类种类的个数,α、β为权重系数,一般关键词的搜索效能与价值率的影响比首页页面数和总页面数的影响要大,即α>β,这个可以根据经验数据测试得出,ρ为挥发系数。
则随着迭代次数的增加,c类总目标函数也在跟着变化:即f∑∑ij在变化;
综合隶属约束条件,构建m个方程组:
λi(i=1,…,m)是m个约束式的拉格朗日算子,对上述式子进行求导,对所有输入参量求导,即可求得使f∑∑ij达到最大的必要条件cj、wij:
步骤4.4:根据判定函数Δ(f)的大小来确定,其具体计算过程如下:
上式为当前迭代的总目标函数值,为上一次迭代的总目标函数值,θ为一个足够小的数。
如果迭代的结果满足上式判定式,则找到了最佳聚类结果;
如果不满足上式,则转到步骤4.2,重新计算隶属矩阵J;
步骤4.5:根据最佳聚类的结果,找到信息量最大的那一类,即为通过优化后需要的关键词,其具体计算过程如下:
上式nk为k类中数据对象的个数,f∑i∈k为k类的总信息量;
信息量最大类为:
maxf∑i∈k=max(f∑i∈1,…,f∑i∈j)
基于蚁群的模糊c均值算法的具体结构流程如图2。
步骤5:根据企业具体情况,综合关键词效能优化和价值率优化,选择合适的关键词优化策略达到网站优化目标。
基于蚁群的模糊c均值算法实现关键词优化,其伪代码过程
输入:网站提取的核心关键词,初始化为c类,初始化随机隶属矩阵J
输出:一系列优化后的高质量关键词。
- 还没有人留言评论。精彩留言会获得点赞!