象形字母汉字编码方法及其计算机键盘输入与流程
本发明涉及汉字信息处理技术,是一种象形字母汉字编码方法及其计算机键盘输入。
背景技术:
计算机作为日常使用工具,输入法是其必不可少的信息交互应用,然而使用非字母的象形单体汉字结构复杂,一直以来未找到与字母输入完美融合的汉字输入法,而当前普遍使用的有拼音、注音、仓颉、五笔输入法,虽然解决了汉字信息交互问题,但缺点也很突出,例如重码多,字根难记等。
技术实现要素:
本发明的目的就是为了解决现有汉字输入法的缺点,而提出的一种字母与汉字输入完美融合的,且重码少、字根易记、易于识字的象形字母汉字编码方法。
本发明是将字母象形化,称之为象形字母,字母象形化按abc依次为:
然后衍生象根字根,使其看来是汉字象形结构中的一部分,所以编码自然而易记,使得汉字与字母完美融合。
本发明的字母,象形字母和象根以及字根的对应表为:
象根包括象形汉字的几乎所有结构,所以识古字者可以快速上手,而不识者,亦可因其象形逼真而趣味的学习汉字,对于普及纯正汉字和汉语,以及重识博大的先秦华夏文化很有帮助。
附图说明
说明书附图1,是a~z的象形字母。
说明书附图2,是字母字根的对应表。
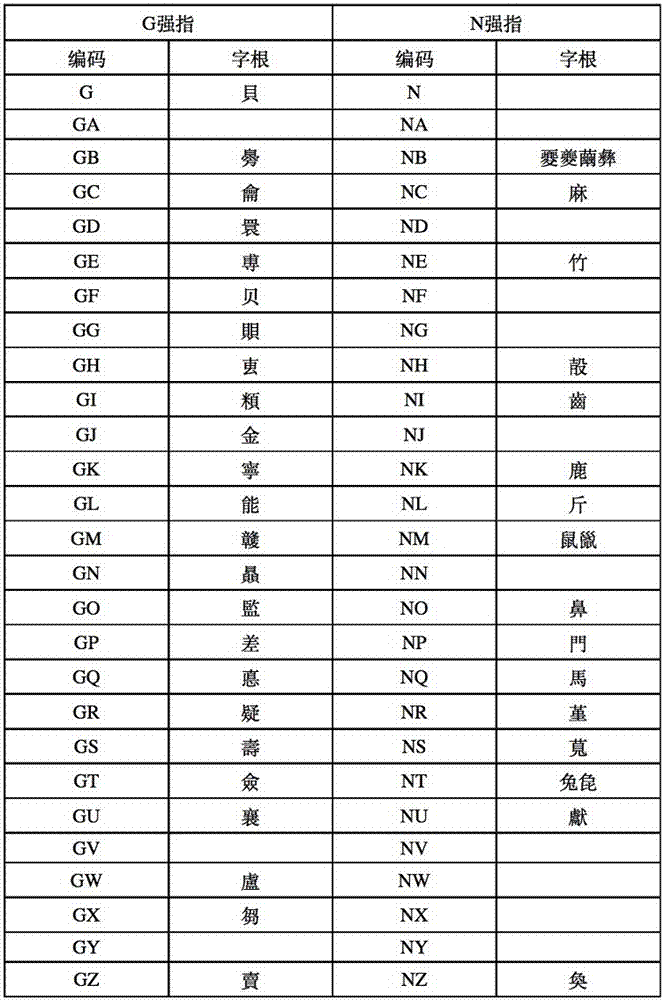
说明书附图3,是g和n的强指表。
具体实施方式
本发明编码顺序按照当今汉字结构的顺序编码。
象形字母具有可以描粗的特点,如h的舟丹凡,m的山火,p的户,d的夕月,o的日等。
象形字母到象根的点演绎法原理如y:
右侧一点向右延伸一条直线,则成为(旗左)象形结构,即(旗左)的编码为y;
左点或右点向两方向延伸,则为干的象形结构,即干的编码亦为y;
左点右点均向上外延伸,则为屰的象形结构,即屰的编码亦为y;
y倒,左点向斜下延伸,右点向右上延伸,则为夭的象形结构,即夭的编码亦为y;
y倒,左点和右点均向外延伸,则为大的象形结构,即大的编码亦为y。
同双字根的省码法,编码加编码的尾字母:
如誩,言的编码为da,则誩的编码da+a,即誩的编码为daa;
如斦,斤的编码为nl,则斦的编码为nl+l,即斦的编码为nll;
如戔,戈的编码为k,则戔的编码为k+k,即戔的编码为kk。
同三四字根的省码法,编码加n:
如磊,石的编码为lo,则磊的编码为lo+n,即磊的编码为lon;
如驫,馬的编码为nq,则驫的编码为nq+n,即驫的编码为nqn;
如燚,火的编码为m,则燚的编码为m+n,即燚的编码为mn。
对称字根省码法,若对称部位在下或右,则为上部或左部编码加对称部位的左码加中码首字母,若对称部位在上,则为对称部位的左码加中码首字母加下部编码:
如學,上部对称非省编码为fxxf,省为左编码f+中编码首字母x,下部编码为uoe,则學的编码为fxuoe;
如朕,左部舟编码为h,右部对称非省编码为iff,则朕的编码为hif。
含攴殳省码法,前字根编码字母数大等于2,则省为e,否则不省:
如役,(役左)的编码为c(小于2),殳的编码为pe,则役的编码为cpe;
如放,方的编码为hf(等于2),攴的编码为te,则放的编码为hfe;
如殹,医的编码为uer(大于2),殳的编码为pe,则殹的编码为uere。
含寸省码法,除寸外,皆省为e:
如寸编码为ei;
如付的编码ze。
g、n强指,由于动物单体象形如马鹿等难按象根拼合,以及复杂字根字母数过多,故强以g,n代指:
竹门斤所以从n,是为了区别艸卯卵丩,以减少重码。
技术特征:
技术总结
本发明公开了一种汉字编码方法及其计算机键盘输入,因为汉字属于单体象形字,一直以来按照字母拼合强指的方式编码输入,以致拼音的重码多,五笔的字根难记等却点,而本编码方法将英文字母象形化并衍生象形汉字所具有的象根,使字母作为象形汉字结构中的一部分,因此编码方法自然而天成,且与字母输入完美融合,而且易于知根知底的学习汉字和正确普及汉字,可以说是汉字编码和输入法乃至汉字使用的一次革新。
技术研发人员:张新伟
受保护的技术使用者:张新伟
技术研发日:2017.09.04
技术公布日:2017.10.27
- 还没有人留言评论。精彩留言会获得点赞!