一种基于机器学习的催化剂抽取方法与流程
本发明涉及化学研究技术领域,尤其涉及一种基于机器学习的催化剂抽取方法。
背景技术:
随着统计分析在化学研究中越来越多的应用,化学科研数据的采集整理愈加重要,其中从细分领域来讲,涉及到化学反应以及众多应用场景中,有关催化剂实体识别在整个化学领域的文本发掘中有着不可或缺的重要角色。
技术实现要素:
基于背景技术存在的技术问题,本发明提出了一种基于机器学习的催化剂抽取方法。
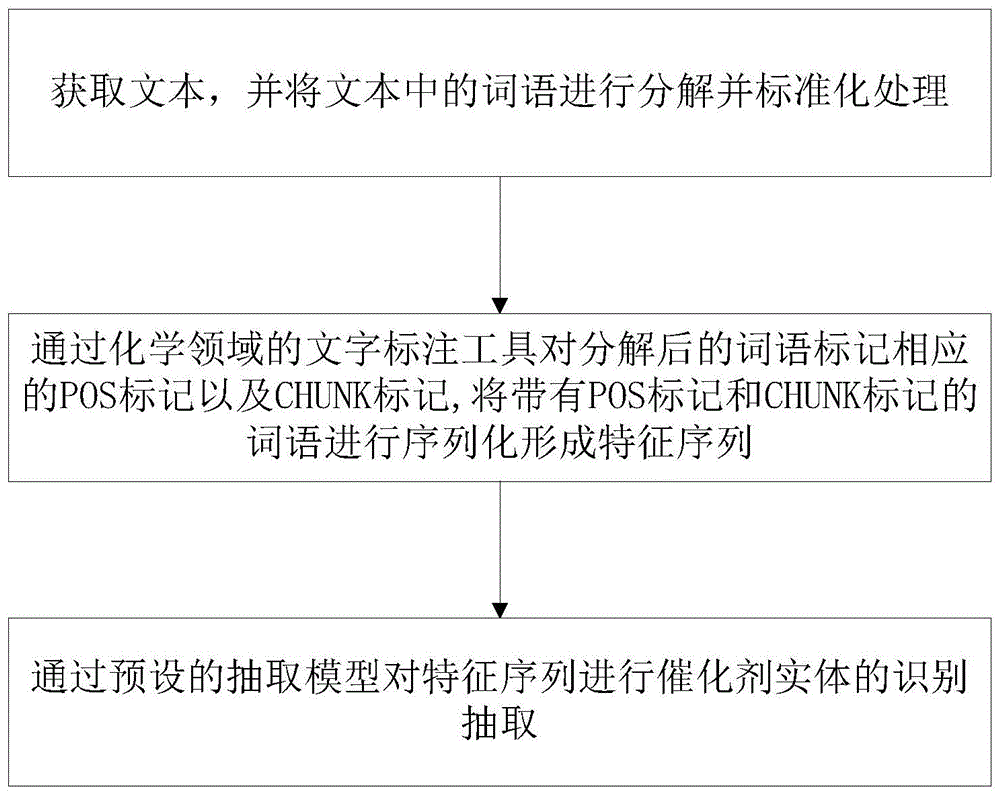
本发明提出的一种基于机器学习的催化剂抽取方法,包括以下步骤:
s1、获取文本,并将文本中的词语进行分解并标准化处理;
s2、通过化学领域的文字标注工具对分解后的词语标记相应的pos标记以及chunk标记,将带有pos标记和chunk标记的词语进行序列化形成特征序列;
s3、通过预设的抽取模型对特征序列进行催化剂实体的识别抽取。
优选的,步骤s1具体为:获取文本,以句子为单位进行初步分词;然后根据预设的特殊类型模板将初步分词词语分类为特殊词语和普通词语,并对普通词语进一步分词作为二次分解词语,然后对特殊词语和二次分解词语进行标准化处理。
优选的,步骤s2中,对分解后的词语标记相应的pos标记以及chunk标记的方法为:首先通过预先加载的预测模型分别对词语进行pos标记以及chunk标记,然后综合两种标记结构对词语进行最终标记。
优选的,预测模型为crf机器学习模型。
优选的,步骤s3具体为:特征序列输入抽取模型后,通过抽取模型根据标记抽取词语中与催化剂相关的化学名词并组合成催化剂实体后输出。
优选的,抽取模型为crf模型。
本发明提出的一种基于机器学习的催化剂抽取方法,首先根据分词结果从文本中抽取特征序列,然后基于特征训练通过训练后的抽取模型抽取文本中的催化剂实体。如此,首先通过词语分解,实现了文本的特征提取,并实现了对文本冗余信息的清洗,降低了后续处理的工作量,提高了工作效率;同时,通过特征提取,也实现了对文本的精炼,从而提高了信息抽取精确程度。且,本实施方式中,通过机器学习模型抽取催化剂,智能化程度高,并且可靠。
附图说明
图1为本发明提出的一种基于机器学习的催化剂抽取方法流程图。
具体实施方式
参照图1,本发明提出的一种基于机器学习的催化剂抽取方法,包括以下步骤。
s1、获取文本,并将文本中的词语进行分解并标准化处理。
具体的,本步骤中,获取文本后,以句子为单位进行初步分词;然后根据预设的特殊类型模板将初步分词词语分类为特殊词语和普通词语,并对普通词语进一步分词作为二次分解词语,然后对特殊词语和二次分解词语进行标准化处理。
如此,本实施方式中,将词语分解分化为两步,通过一次分词后对分词词语的识别判断,挑选出普通词语进行二次分词,保证了对文本语句的充分分解,保证了文本信息提取的精炼。同时,也避免了对特殊词语尤其是包含化雪特征的词语的过度分解,保证了特征信息的完整。
s2、通过化学领域的文字标注工具对分解后的词语标记相应的pos标记以及chunk标记,将带有pos标记和chunk标记的词语进行序列化形成特征序列。
具体的,本实施方式中,对分解后的词语标记相应的pos标记以及chunk标记的方法为:首先通过预先加载的预测模型分别对词语进行pos标记以及chunk标记,然后综合两种标记结构对词语进行最终标记。具体的,预测模型为crf机器学习模型。
本实施方式中,对pos标记以及chunk标记进行分开标记,保证了标记信息的完整。
s3、通过预设的抽取模型对特征序列进行催化剂实体的识别抽取。具体的,本步骤中,特征序列输入抽取模型后,通过抽取模型根据标记抽取词语中与催化剂相关的化学名词并组合成催化剂实体后输出。抽取模型为crf模型。
本实施方式中,首先根据分词结果从文本中抽取特征序列,然后基于特征训练通过训练后的抽取模型抽取文本中的催化剂实体。如此,首先通过词语分解,实现了文本的特征提取,并实现了对文本冗余信息的清洗,降低了后续处理的工作量,提高了工作效率;同时,通过特征提取,也实现了对文本的精炼,从而提高了信息抽取精确程度。且,本实施方式中,通过机器学习模型抽取催化剂,智能化程度高,并且可靠。
以上所述,仅为本发明涉及的较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
技术特征:
1.一种基于机器学习的催化剂抽取方法,其特征在于,包括以下步骤:
s1、获取文本,并将文本中的词语进行分解并标准化处理;
s2、通过化学领域的文字标注工具对分解后的词语标记相应的pos标记以及chunk标记,将带有pos标记和chunk标记的词语进行序列化形成特征序列;
s3、通过预设的抽取模型对特征序列进行催化剂实体的识别抽取。
2.如权利要求1所述的基于机器学习的催化剂抽取方法,其特征在于,步骤s1具体为:获取文本,以句子为单位进行初步分词;然后根据预设的特殊类型模板将初步分词词语分类为特殊词语和普通词语,并对普通词语进一步分词作为二次分解词语,然后对特殊词语和二次分解词语进行标准化处理。
3.如权利要求1所述的基于机器学习的催化剂抽取方法,其特征在于,步骤s2中,对分解后的词语标记相应的pos标记以及chunk标记的方法为:首先通过预先加载的预测模型分别对词语进行pos标记以及chunk标记,然后综合两种标记结构对词语进行最终标记。
4.如权利要求3所述的基于机器学习的催化剂抽取方法,其特征在于,预测模型为crf机器学习模型。
5.如权利要求1所述的基于机器学习的催化剂抽取方法,其特征在于,步骤s3具体为:特征序列输入抽取模型后,通过抽取模型根据标记抽取词语中与催化剂相关的化学名词并组合成催化剂实体后输出。
6.如权利要求5所述的基于机器学习的催化剂抽取方法,其特征在于,抽取模型为crf模型。
技术总结
本发明提出的一种基于机器学习的催化剂抽取方法,包括以下步骤:获取文本,并将文本中的词语进行分解并标准化处理;通过化学领域的文字标注工具对分解后的词语标记相应的POS标记以及CHUNK标记,将带有POS标记和CHUNK标记的词语进行序列化形成特征序列;通过预设的抽取模型对特征序列进行催化剂实体的识别抽取。本发明首先通过词语分解,实现了文本的特征提取,并实现了对文本冗余信息的清洗,降低了后续处理的工作量,提高了工作效率;同时,通过特征提取,也实现了对文本的精炼,从而提高了信息抽取精确程度。且,本实施方式中,通过机器学习模型抽取催化剂,智能化程度高,并且可靠。
技术研发人员:李鑫;沈伟;鲍琦
受保护的技术使用者:苏州机数芯微科技有限公司
技术研发日:2020.03.25
技术公布日:2020.07.10
- 还没有人留言评论。精彩留言会获得点赞!