RPU阵列的噪声和信号管理的制作方法
rpu阵列的噪声和信号管理
技术领域
1.本发明涉及具有电阻处理单元(resistive processing unit,rpu)器件的模拟交叉点阵列的人工神经网络(artificial neural network,ann)的训练,更具体地,涉及在ann训练期间用于rpu阵列的高级噪声和信号管理技术。
背景技术:
2.人工神经网络(ann)可以体现在电阻器件的模拟交叉点阵列,例如在gokmen等人的美国专利申请公开号2017/0109628,题为“resistive processing unit”中描述的电阻处理单元(rpu)。如本文所描述,每个rpu包括第一端子、第二端子和有源区。有源区的导电状态识别rpu的权重值,该权重值可以通过向第一端子/第二端子施加信号来更新/调整。
3.基于ann的模型已经用于各种不同的基于认知的任务,例如对象和语音识别以及自然语言处理。例如,参见gokmen等人的“training deep convolutional neural networks with resistive cross
‑
point devices”,载于frontiers in neuroscience(《神经科学前沿》)第11卷538号文章(2017年10月)(13页)。当执行这些任务时,需要神经网络训练来提供高水平的精确度。
4.然而,在rpu阵列上执行的向量
‑
矩阵乘法运算本质上是模拟的,因此容易受到各种噪声源的影响。当rpu阵列的输入值很小时(例如对于反向循环传递(backward cycle pass)),输出信号y可能被噪声掩盖,因此产生不正确的结果(即,y=w.δ+noise,w.δ<<noise)。例如,参见gokmen等人的美国专利申请公开号2018/0293209,题为“noise and bound management for rpu array”。由于模拟噪声作为因素,使用这种模拟rpu阵列来精确ann训练是困难的。
5.因此,在ann训练期间使模拟噪声的影响最小化的技术将是合乎需要的。
技术实现要素:
6.本发明提供了在人工神经网络(ann)训练期间用于电阻处理单元(rpu)阵列的高级噪声和信号管理技术。在本发明的一个方面,提供了一种用于具有噪声和信号管理的ann训练的方法。该方法包括:提供rpu器件的阵列,该rpu器件的阵列具有被配置为处理到该阵列的输入向量x的n个元素的大小为g的集合组的预归一化器,以及具有被配置为处理来自该阵列的输出向量y的m个元素的大小为g的集合组的后归一化器,其中,阵列表示具有m行和n列的ann的权重矩阵w,其中,权重矩阵w的权重值w被存储为rpu器件的电阻值;跨n个向量计算属于每个预归一化器的集合组的输入向量x的所有元素的平均值μ和标准偏差σ,产生预归一化器的当前平均值μ和标准偏差值σ,其中,平均值μ和标准偏差σ是在n乘以g个输入值上计算的;用折扣因子α更新预归一化器的先前存储的平均值μ和标准偏差值σ,预归一化器的当前平均值μ和标准偏差值σ产生预归一化器的更新的存储的平均值μ和标准偏差值σ;使用预归一化器的更新的存储的平均值μ和标准偏差值σ将n乘以g个输入值预归一化,从所有预归一化器产生n个归一化的输入向量x
norm
,以通过阵列与前向循环传递中的模拟噪
声一起计算w*x
norm
;跨n个向量计算属于每个后归一化器的集合组的输出向量y的所有元素的平均值μ和标准偏差σ,产生后归一化器的当前平均值μ和标准偏差值σ,其中,平均值μ和标准偏差σ是在n乘以g个输入值上计算的;用折扣因子α更新后归一化器的先前存储的平均值μ和标准偏差值σ,后归一化器的当前平均值μ和标准偏差值σ产生后归一化器的更新的存储的平均值μ和标准偏差值σ;使用后归一化器的更新的存储的平均值μ和标准偏差值σ将n乘以g个输出值后归一化,从所有后归一化器产生n个归一化的输出向量y
norm
;使用先前的标准偏差σ变换n个输入向量d,产生n个变换的输入向量d
norm
,以通过阵列与反向循环传递中的模拟噪声一起计算w
t
*d
norm
;以及使用预归一化器的先前的标准偏差σ变换n个输出向量d’,以产生n个变换的输出向量d
′
norm
。
7.通过参考以下详细描述和附图,将获得对本发明的更完整理解以及本发明的进一步特征和优点。
附图说明
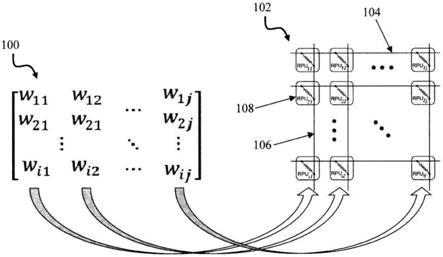
8.图1是示出根据本发明的实施例的在电阻处理单元(rpu)器件的模拟交叉点阵列中体现的人工神经网络(ann)的图;
9.图2a是示出根据本发明的实施例的用于具有噪声和信号管理的ann训练的示例性方法200的初始化阶段以及训练阶段的前向循环传递的图;
10.图2b(从图2a继续)是示出根据本发明的实施例的示例性方法200的训练阶段的反向循环传递的图;
11.图2c(从图2b继续)是示出根据本发明的实施例的示例性方法200的训练阶段的反向循环传递和更新传递的接续的图;
12.图3是示出根据本发明的实施例的具有可以实施方法200的预归一化器和后归一化器的示例性rpu阵列的图;以及
13.图4是示出根据本发明的实施例的可以在执行本技术中的一个或多个时采用的示例性装置的图。
具体实施方式
14.如上文所述,由于模拟噪声,利用模拟电阻交叉阵列(例如,模拟电阻处理单元(resistive processing unit,rpu)阵列)的人工神经网络(ann)训练是困难的。此外,训练过程受到阵列采用的模
‑
数转换器(analog
‑
to
‑
digital converter,adc)和数
‑
模转换器(digital
‑
to
‑
analog converter,dac)的有界范围的限制。即,如将在下文详细描述的,dac和adc分别用于将到rpu的数字输入转换为模拟信号,以及将来自rpu的输出转换回数字信号。
15.有利地,本文提供了相应的对输入和输出进行归一化的技术,以克服这些噪声和信号边界限制。例如,如将在下文详细描述的,通过计算和存储多个输入值和/或输入值集合的均值和方差,并以运行平均方式更新均值和方差,来执行对rpu阵列的输入的归一化(即,归零均值和方差)。
16.如上文所述,ann可以体现在rpu器件的模拟交叉点阵列中。例如,参见图1。如图1所示出,算法(抽象)权重矩阵100的每个参数(权重w
ij
)被映射到硬件上的单个rpu器件
(rpu
ij
),即rpu器件的物理交叉点阵列102。交叉点阵列102具有一系列导电行线104和一系列导电列线106,导电列线106与导电行线104正交并相交。导电行线104和导电列线106的交叉点由rpu器件108分隔,形成rpu器件108的交叉点阵列102。如美国专利申请公开号2017/0109628中所述,每个rpu器件108可以包括第一端子、第二端子和有源区。有源区的导电状态识别rpu器件108的权重值,该权重值可以通过向第一端子/第二端子施加信号来更新/调整。此外,三端(或甚至更多端)器件可以通过控制额外端子而有效地用作二端电阻式存储器件。例如,关于三端rpu器件的描述,参见kim等人的“analog cmos
‑
based resistive processing unit for deep neural network training”,载于2017年ieee第60期internatinal midwest symposium on circuits and systems(mwscas),(2017年8月)(4页)。
17.每个rpu器件108(rpu
ij
)基于其在交叉点阵列102中的位置(即,第i行和第j列)被唯一地识别。例如,从交叉点阵列102的顶部到底部,以及从左到右,在第一导电行线104和第一导电列线106的交叉点处的rpu器件108被指定为rpu
11
,在第一导电行线104和第二导电列线106的交叉点处的rpu器件108被指定为rpu
12
,等等。权重矩阵100中的权重参数到交叉点阵列102中的rpu器件108的映射遵循相同的惯例。例如,权重矩阵100的权重w
i1
被映射到交叉点阵列102的rpu
i1
,权重矩阵100的权重w
i2
被映射到交叉点阵列102的rpu
i2
,等等。
18.交叉点阵列102的rpu器件108用作ann中的神经元之间的加权连接。rpu器件108的电阻可以通过控制施加在单个导电行线104和导电列线106之间的电压来改变。改变电阻是基于例如高电阻状态或低电阻状态来将数据存储在rpu器件108中。通过施加电压并测量通过目标rpu器件108的电流来读取rpu器件108的电阻状态。所有涉及权重的操作由rpu器件108并行地完全执行。
19.在机器学习和认知科学中,基于ann的模型是一系列统计学习模型,其灵感来自动物的生物神经网络,尤其是大脑。这些模型可以用于估计或近似估计依赖于通常未知的大量输入和连接权重的系统和认知功能。ann通常体现为互连处理器元件的所谓“神经形态”系统,该互连处理器元件充当以电子信号的形式在彼此之间交换“信息”的模拟“神经元”。在ann中,在模拟神经元之间传递电子信息的连接具有与给定连接的强或弱相对应的数字权重。这些数字权重可以基于经验来调整和调谐,使得ann适应于输入并且能够学习。例如,用于手写识别的ann由输入神经元的集合定义,该输入神经元的集合可以由输入图像的像素激活。在由网络设计者确定的函数进行加权和变换之后,然后,这些输入神经元的激活被传递到其他下游神经元。该过程被重复直到激活输出神经元。激活的输出神经元确定读取哪个字符。
20.如下文将进一步详细描述的,可以利用增量或随机梯度下降(stochastic gradient descent,sgd)过程来训练ann,其中使用反向传播来计算每个参数(权重w
ij
)的误差梯度。例如,参见rumelhart等人的“learning representations by back
‑
propagating errors”,载于nature(《自然》)第323期第533
‑
536页(1986年10月)。反向传播在三个循环中执行,即前向循环、反向循环和权重更新循环,这些循环被重复多次直到满足收敛标准。
21.基于ann的模型由多个处理层组成,这些处理层学习具有多个抽象等级的数据表示。例如,参见lecun等人的“deep learning”,载于nature(《自然》)第521期第436
‑
444页(2015年5月)。对于n个输入神经元连接到m个输出神经元的单个处理层,前向循环涉及计算
向量
‑
矩阵乘法(y=wx),其中长度为n的向量x表示输入神经元的活动,大小为m
×
n的矩阵w存储每对输入和输出神经元之间的权重值。通过对每个电阻存储元件执行非线性激活将得到的长度为m的向量y进行进一步处理,然后将其传递到下一层。
22.一旦信息到达最终输出层,反向循环涉及计算误差信号并通过ann反向传播误差信号。单层上的反向循环还涉及对权重矩阵(z=w
t
δ)的转置(互换每行和对应列)的向量
‑
矩阵乘法,其中长度为m的向量δ表示由输出神经元计算的误差,并且使用神经元非线性的导数对长度为n的向量z进行进一步处理,然后向下传递到先前层。
23.最后,在权重更新循环中,通过执行在前向循环和反向循环中使用的两个向量的外积来更新权重矩阵w。这两个向量的外积通常被表示为w
←
w+η(δx
t
),其中η是全局学习率。
24.在该反向传播过程中,所有在加权矩阵w上执行的操作都可以用具有相应数量m行和n列的rpu器件108的交叉点阵列102来实施,其中在交叉点阵列102中存储的电导值形成了矩阵w。在前向循环中,输入向量x作为电压脉冲通过每个导电列线106传输,并且得到的向量y被读取作为从导电行线104输出的电流。类似地,当从导电行线104提供电压脉冲作为反向循环的输入时,对权重矩阵的转置w
t
计算向量
‑
矩阵积。最后,在更新循环中,从导电列线106和导电行线104同时提供表示向量x和δ的电压脉冲。因此,每个rpu器件108通过处理来自对应的导电列线106和导电行线104的电压脉冲来执行局部乘法和加法运算,从而实现增量权重更新。
25.如上文所述,在rpu阵列上执行的操作本质上是模拟的,因此易于产生各种噪声源。例如,参见gokmen等人的美国专利申请公开号2018/0293209,题为“noise and bound management for rpu array”。
26.使用例如美国专利申请公开号2018/0293209中描述的噪声管理方法,输出噪声幅度是在σmax(|(x
i
)|)的数量级上,其中σ(sigma)是rpu阵列的模拟噪声的标准偏差。关于rpu阵列的其他细节,参见例如授予gokmen的美国专利9,646,243,题为“convolutional neural networks using resistive processing unit array”。
27.rpu阵列的信噪比(signal
‑
to
‑
noise ratio,snr)近似计算为:
[0028][0029]
因为‖y‖
∝
‖w‖‖x‖。因此,通过随机梯度下降过程来改善snr的一种方式是在ann学习期间增加权重(直到达到输出边界或权重边界)。
[0030]
然而,以这种方式增加重量具有几个显著的缺点。例如,rpu器件本身具有有限的可以用于ann训练的权重范围。即,rpu器件的权重范围(电阻值)被限制在具有受限的(limited)和有限的(finite)状态分辨率的有界范围内。rpu器件还具有有限数量的状态(仅用于编码增益)。此外,许多更新可能是必要的,这样做可能加速漂移,这是所不期望的。还存在与维持大权重相关联的高成本(就需要更新的数量而言),尤其是在权重衰减/漂移为零时。
[0031]
此外,利用卷积神经网络,多行权重矩阵码为不同的输出特征(信道)和包括多个输入信道的一行(输入)编码。每个输出信道i的snr是:
[0032][0033]
因此,如果输出信号是较小的|y
i
|(例如对于反向循环传递),则噪声管理(其仅除以所有输入上的绝对最大值)可以偏向高幅度输入通道,而大多数低振幅输入被抑制并掩盖于噪声基底中。
[0034]
有利地,本技术通过计算和存储多个输入值和/或输入值集合上的平均值和方差,并以运行平均方式更新均值和方差以将rpu阵列的输入归一化(例如,归零均值和方差),来克服这些噪声和信号边界限制。例如,参见图2a
‑
图2c用于具有噪声和信号管理的ann训练的方法200。
[0035]
如图2a
‑
图2c所示,方法200具有初始化阶段,之后是具有前向循环传递、反向循环传递和权重更新传递的训练阶段。rpu阵列用于表示具有m行和n列的ann的权重矩阵w。例如,参见图3中的rpu阵列300。如结合上文图1的描述所描述的,权重矩阵w的权重值w被存储作为阵列300中的rpu器件(标记为“rpu”)的电阻值。如图3所示,为阵列300的每个输入提供归一化器(标记为“每个输入的归一化器”),本文也称为“预归一化器”,以及为阵列300的每个输出提供归一化器(标记为“每个输出的归一化器”),本文也称为“后归一化器”。根据示例性实施例,预归一化器和后归一化器由rpu阵列外部的硬件控制,例如,诸如结合下文图4的描述所描述的装置400,预归一化器和后归一化器可与其交换数据。
[0036]
一般而言,每个输入信号的预归一化可以表示为:
[0037][0038]
每个输出信号的后归一化可以表示为:
[0039][0040]
如上文所述,并且如下文将详细描述的,(前/后)归一化器i的平均值μ
i
(mu)和方差(即,标准偏差)σ
i
(sigma)的值将通过输入的一些(泄漏的)运行平均(t是当前迭代/批次)来估计,其中是:1)单电流输入:
[0041][0042]
其中整数a≤0,或者是2)来自单个输入的批值,但是包括先前的时间步骤:
[0043][0044]
其中整数a≤0,b≤a,和/或3)当μ
i
、σ
i
被输入组共享时,包括该共享输入组的所有输入批,例如,
[0045][0046]
如果输入1和2是分组的。在以上等式10
‑
等式12中,x用y
′
代替,用于后归一化器的μ和σ。
[0047]
每个参数μ
i
根据周期性地(例如,每a
‑
b时间步长一次)被更
新,其中表示的平均值。数量σ
i
也使用相同的数据集周期性地(例如,每a
‑
b时间步长一次)被更新,但是计算b时间步长一次)被更新,但是计算和其中∈≥0。α和β是在预归一化器和后归一化器侧的所有归一化器之间共享的参数,但对于预归一化器和后归一化器可以不同。如果没有另外指定,β由1
‑
α给出。
[0048]
参考方法200,如图2a所示出,初始化阶段在步骤202开始,通过初始化n
pre
(0和n个输入值之间的整数)个预归一化器(参见图3)以使它们各自存储的μ(mu)值全部被设置为0,它们各自存储的σ(sigma)值全部被设置为1,以及初始化m
post
(0和m个输出值之间的整数)个后归一化器(参见图3)以使它们各自存储的μ值全部被设置为0,它们各自存储的σ值全部被设置为1。
[0049]
可选地,在步骤204中,预归一化器被初始化以使它们各自存储的(运行平均值因子)ν(nu)值全部被设置为0,它们各自存储的(交叉
‑
相关因子)δ(delta)值全部被设置为1,以及后归一化器被初始化以使它们各自存储的ν值全部被设置为0,它们各自存储的δ值全部被设置为1。步骤204是可选的,因为它取决于选择了反向循环传递类型a)或b)中的哪一个(参见下文)。例如,只有选择了反向循环传递类型b),才需要对预归一化器和后归一化器中的ν和δ进行初始化。
[0050]
每个预归一化器被配置为处理到阵列300的输入向量的n个元素的组,且由每个预归一化器处理的n个元素的组在下文是固定的。同样,每个后归一化器被配置为处理来自阵列300的输出向量的m个元素的组,且由每个后归一化器处理的m个元素的组在下文是固定的。
[0051]
在步骤206中,折扣因子α(alpha)(参见上文)的值大于0且小于1。该值对于一侧(例如,预)的所有归一化器是相同的,但可以单独地选择用于预归一化器还是后归一化器。如果没有另外指定,β由1
‑
α给出。初始化阶段(在步骤202
‑
206中执行)现在完成。值得注意的是,根据示例性实施例,初始化阶段和/或训练阶段的一个或多个步骤在rpu阵列硬件的外部执行,例如,由诸如结合下文图4的描述所描述的装置400执行。
[0052]
如图2a所示,方法200的下一阶段是训练阶段。如上文所述,ann训练可以包括具有反向传播的sgd过程。通常,反向传播在三个循环中执行,前向循环、反向循环和权重更新循环,这些循环被重复多次(多次迭代)直到满足收敛标准。对于在反向传播期间使用的循环的一般描述,参见例如tayfun gokmen的美国专利申请序列号16/400,674,题为“dnn training with asymmetric rpu devices”。
[0053]
如图2所示,训练阶段以前向循环传递开始。根据本技术,在前向循环传递的每次迭代i中,n个输入向量x(例如,小批量)被存储在例如具有随机存取存储器的数字硬件中。每个输入向量x具有n个元素。在步骤208中,当前输入向量x被提供给预归一化器(参见图3的“当前输入x”,其中每个圆302表示到rpu阵列300的单独输入向量x)。如上文所述,执行该过程的多次迭代。在迭代的内循环中,当前输入向量x是该过程的第一输入(参见下文)。在迭代的外循环中(例如,在小批量上),以折扣方式更新先前存储的值(参见下文)。
[0054]
即,在步骤210中,每个预归一化器计算当前输入向量x的所有元素n的平均值μ和标准偏差σ的当前值,输入向量x属于跨所有n个向量的其集合组。如果其集合组的大小为g,则平均值μ和标准偏差σ因此是在n乘以g个输入值上计算。如果n和g为1,则使用先前存储的
平均值μ和标准偏差σ的值计算运行平均和标准偏差。
[0055]
然后,使用为已被折扣因子α折扣的预归一化器存储的平均值μ和标准偏差σ对n乘以g个输入值进行预归一化。例如,根据示例性实施例,在步骤212处,每个预归一化器以折扣因子α(alpha)的折扣方式通过新计算的值(来自步骤210)从最后(先前)迭代i来更新先前存储的μ和σ(如果有的话),即,以一减去alpha乘以旧(先前存储的)值ν
old
加上alpha乘以新值ν
new
,即,(1
‑
α)*ν
old
+α*ν
new
,并存储更新的结果。在步骤214处,每个预归一化器将所有n乘以g个输入值减去其存储的μ,并将结果除以其存储的σ。例如,参见上文等式8。预归一化器一起产生n个归一化的输入向量x
norm
。
[0056]
对于n个归一化输入向量x
norm
(参见图3的“归一化输入x
′”
)中的每一个,然后用阵列300执行矩阵
‑
向量乘法以用来计算具有模拟噪声的w*x
norm
。参见步骤216。根据示例性实施例,步骤216包括i)将n个归一化的输入向量x
norm
转换成模拟脉冲宽度(例如,使用数模转换器(dac)(未示出)),ii)经由阵列300计算具有模拟噪声的w*x
norm
(模拟计算总是有噪声的),以及iii)以数字形式(例如,使用模数转换器(adc)(未示出))表示来自阵列300的输出向量y。所有n个输出向量y现在以数字格式存储为向量y。对于以数字方式存储的向量,通常需要dac和adc。然而,如果n*g=1,有可能放弃模拟和数字转换。
[0057]
在步骤218中,每个后归一化器计算当前输出向量y的所有元素的平均值μ和标准偏差σ的当前值(例如,参见图3中的“当前输出y
′”
),输出向量y属于跨所有n个向量的其设置组。如果其设置组的大小为g,则平均值μ和标准偏差σ因此是在n乘以g个输出值上计算的。如果n和g为1,则使用先前存储的平均值μ和标准偏差σ的值计算运行平均和标准偏差。
[0058]
然后,使用为已被折扣因子α折扣的后归一化器存储的平均值μ和标准偏差σ对n乘以g个输出值进行后归一化。例如,根据示例性实施例,在步骤220处,每个后归一化器以折扣因子α(alpha)的折扣方式通过新计算的值(来自步骤218)从最后(先前)迭代i来更新先前存储的μ和σ(如果有的话),即,如上文,以一减去alpha乘以旧(先前存储的)值ν
old
加上alpha乘以新值ν
new
,即,(1
‑
α)*ν
old
+α*ν
new
,并存储更新的结果。在步骤222处,每个后归一化器将所有n乘以g个输出值减去其存储的μ,并将结果除以其存储的σ。例如,参见上文等式9。
[0059]
后归一化器一起产生n个归一化的输出向量y
norm
。这些归一化的输出向量y
norm
表示rpu阵列300硬件(对于一个ann层)的最终输出,并且可以接下来计算例如激活函数或另一层。
[0060]
如图2b所示(从图2a继续),训练阶段接下来包括反向循环传递。在反向循环传递的每次迭代i中,存储(例如,在硬件的数字部分中,从下一更高层传递回)n个输入向量d。每个输入向量d具有m个元素。
[0061]
一般而言,对于反向循环传递,如果x
′
是已经归一化的输入且d
′
是梯度输入,则反向循环传递的输出d是:
[0062][0063]
或者
[0064]
其中有序输入的集合和的组成如同上文所描述的(具有相同的顺序),
但是从归一化输入x
′
t
和梯度输入d
′
t
相反。α是与上文前向传递相同的折扣因子。参数v
i
被周期性地更新和计算为其中β*和α*是固定参数,例如,β*=0,α*=0,每个的默认值分别等于1
‑
α和α。数量γ
i
被周期性地更新和计算为其中乘积意味着仅沿着在两个有序集合中彼此对应的x
′
和d的对。类似地,对于后归一化步骤,取归一化的输出信号y和对应的梯度输入来代替x
′
和d
′
。
[0065]
如上文所述,根据本技术,设想了两种不同类型的反向循环传递,本文称为反向循环传递类型a)和类型b)。每种情况涉及使用来自最后的后归一化迭代的用于后归一化器的先前标准偏差σ,来变换反向循环传递的输入向量d,以产生n个变换后的输入向量d
norm
。即,在一个示例性实施例中,反向循环传递类型a)在步骤224处开始,其中每个后归一化器使用其对应的元素分组将d个向量元素中的所有n乘以d除以其先前存储的σ(来自最后的后归一化迭代和折扣),由此后归一化器一起产生n个变换后的输入向量d
norm
。
[0066]
可替代地,在另一示范性实施例中,反向循环传递类型b)开始于步骤226,其中每个后归一化器计算其对应的向量d的n乘以g个输出值的平均值μ并将μ存储为v(nu),从而使用折扣因子α折扣ν的旧值。如果n乘以g个输出值为1,则使用ν的先前值(来自最后的后归一化迭代和折扣)来计算运行平均值。在步骤228处,计算在前向循环传递期间向量d的n乘以g个输出值与输出向量y的对应值之间的互相关(cross
‑
correlation)。这被存储为δdelta,从而使用折扣因子α折扣δ的旧值。如果n乘以g个输出值为1,则使用δ的先前值(来自最后的后归一化迭代和折扣)来计算运行互相关。在步骤230处,向量d的n乘以g个输出值的每一个减去被计算为alpha乘以nu的第一项,然后减去被计算为alpha乘以delta乘以来自前向传递的向量y的对应元素值的第二项。最后,在步骤232处,每个后归一化器使用其对应的元素分组将d个向量元素中的所有n乘以d除以其先前存储的σ(来自最后的后归一化迭代和折扣),由此后归一化器一起产生n个变换后的输入向量d
norm
。
[0067]
对于反向循环传递类型a)或类型b),对于n个变换的输入向量d
norm
中的每一个,然后使用阵列300执行转置矩阵
‑
向量乘法,以计算具有模拟噪声的w
t
*d
norm
。参见步骤234。根据示例性实施例,步骤234包括i)将n个变换后的输入向量d
norm
转换成模拟脉冲宽度(例如,使用数模转换器(dac)(未示出)),ii)经由阵列300计算具有模拟噪声的w
t
*d
norm
,以及iii)以数字形式(例如,使用模数转换器(adc)(未示出))表示来自阵列300的输出向量d
′
。所有n个输出向量d
′
现在以数字格式存储。
[0068]
在转置矩阵
‑
向量乘法之后,预归一化器的运算再次取决于选择了反向循环传递类型a)或类型b)中的哪一个。如果在步骤224中选择了反向循环传递类型a),则该过程以使用类型a)反向循环传递的相同方式进行。相反,如果在步骤226
‑
232中选择了反向循环传递类型b),则该过程以使用类型b)反向循环传递的相同方式进行。每种情况包括使用来自最后的预归一化迭代的用于预归一化器的先前标准偏差σ,来变换反向循环传递的输出向量d
′
,以产生n个变换后的输出向量d
′
norm
。所有的预归一化器一起产生n个变换后的输出向量d
′
norm
,其表示在反向循环传递期间rpu硬件(对于一个ann层)的最终输出。参见图2c(从图2b继续)。即,在一个示例性实施例中,反向循环传递类型a)在步骤236处继续,其中每个预归一化器使用其对应的元素分组将d
′
个向量元素中的所有n乘以d除以其先前存储的σ(来
自最后的预归一化迭代和折扣),由此预归一化器一起产生n个变换后的输出向量d
′
norm
。
[0069]
可替代地,在另一示例性实施例中,反向循环传递类型b)在步骤238处继续,其中每个预归一化器计算其对应的向量d
′
的n乘以g个输出值的平均值μ并将μ存储为ν(nu),从而用折扣因子α折扣ν的旧值。如果n乘以g个输出值为1,则使用ν的先前值(来自最后的后归一化迭代和折扣)来计算运行平均值。在步骤240处,计算在前向循环传递期间向量d
′
的n乘以g个输出值与输入向量x的对应值之间的互相关。这被存储为δ,从而用折扣因子α折扣δ的旧值。如果n乘以g个输出值为1,则使用δ的先前值(来自最后的预归一化迭代和折扣)来计算运行互相关。在步骤242处,向量d
′
的n乘以g个输出值中的每一个减去被计算为alpha乘以nu的第一项,然后减去被计算为alpha乘以delta乘以来自前向传递的向量x的对应元素值的第二项。最后,在步骤244中,每个预归一化器使用其对应的元素分组将d
′
个向量元素的所有n乘以d除以其先前存储的σ(来自最后的预归一化迭代和折扣),由此后归一化器一起产生n个变换后的输入向量d
′
norm
。
[0070]
如图2c所示出,训练阶段接下来涉及权重更新循环传递。即,分别用在前向周期传递和反向周期传递期间计算的x
norm
和d
′
norm
向量来更新rpu阵列300。在训练阶段完成之后,系统也可以以推断模式运行。在这种模式下,不进行更新阶段或反向阶段。相反,仅计算如上文所述的正向传递,除了不再更新所有预归一化器或后归一化器的所有存储值,仅将来自先前训练阶段的预归一化器和后归一化器的存储值用于归一化步骤。
[0071]
本发明可以是任何可能的技术细节集成水平的系统、方法和/或计算机程序产品。计算机程序产品可以包括其上具有计算机可读程序指令的计算机可读存储介质(或多个介质),该计算机可读程序指令用于使处理器执行本发明的各方面。
[0072]
计算机可读存储介质可以是能够保留和存储指令以供指令执行设备使用的有形设备。计算机可读存储介质可以是,例如但不限于,电子存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或上述的任何合适的组合。计算机可读存储介质的更具体示例的非穷举列表包括以下:便携式计算机软盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式光盘只读存储器(cd
‑
rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码装置(例如,打孔卡或其上记录有指令的凹槽中的凸起结构),以及上述的任何合适的组合。如本文所使用的,计算机可读存储介质不应被解释为本身是瞬态信号,例如无线电波或其他自由传播的电磁波、通过波导或其他传输介质传播的电磁波(例如,通过光纤线缆的光脉冲),或通过导线传输的电信号。
[0073]
本文描述的计算机可读程序指令可以从计算机可读存储介质下载到相应的计算/处理设备,或经由网络(例如,互联网、局域网、广域网和/或无线网络)下载到外部计算机或外部存储设备。网络可以包括铜传输电缆、光传输光纤、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配卡或网络接口从网络接收计算机可读程序指令,并转发计算机可读程序指令以存储在相应计算/处理设备内的计算机可读存储介质中。
[0074]
用于执行本发明的操作的计算机可读程序指令可以是汇编指令、指令集架构(instruction
‑
set
‑
architecture,isa)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据,或者以一种或多种编程语言的任意组合编写的源代码或目标代码,该编程
语言包括面向对象的编程语言(例如smalltalk、c++等)以及传统的过程式编程语言(例如“c”编程语言或类似的编程语言)。计算机可读程序指令可以完全在用户的计算机上执行、部分在用户的计算机上执行、作为独立的软件包执行、部分在用户的计算机上并且部分在远程计算机上执行,或者完全在远程计算机或服务器上执行。在后一种情况下,远程计算机可以通过任何类型的网络连接到用户的计算机,包括局域网(lan)或广域网(wan),或者可以连接到外部计算机(例如,通过使用因特网服务提供商的因特网)。在一些实施例中,包括例如可编程逻辑电路、现场可编程门阵列(fpga)或可编程逻辑阵列(pla)的电子电路,可以通过利用计算机可读程序指令的状态信息来执行计算机可读程序指令以个性化电子电路,来执行本发明的方面。
[0075]
本文参考根据本发明实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图来描述本发明的各方面。应当理解,流程图和/或框图的每个块以及流程图和/或框图中的块的组合,可以由计算机可读程序指令来实施。
[0076]
这些计算机可读程序指令可以被提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器以生产机器,使得经由计算机或其他可编程数据处理装置的处理器执行的指令创建用于实施流程图和/或框图的一个或多个块中指定的功能/动作的组件。这些计算机可读程序指令还可以存储在计算机可读存储介质中,其可以引导计算机、可编程数据处理装置和/或其他设备以特定方式运行,使得其中存储有指令的计算机可读存储介质包括制品,该制品包括实施流程图和/或框图的一个或多个块中指定的功能/动作的方面的指令。
[0077]
计算机可读程序指令还可以被加载到计算机、其他可编程数据处理装置或其他设备上,以使得在计算机、其他可编程装置或其他设备上执行一系列操作步骤以产生计算机实施的过程,使得在计算机、其他可编程装置或其他设备上执行的指令实施流程图和/或框图的一个或多个块中指定的功能/动作。
[0078]
附图中的流程图和框图示出了根据本发明的各种实施例的系统、方法和计算机程序产品的可能实施方式的架构、功能和操作。在这点上,流程图或框图中的每个块可以表示指令的模块、段或部分,其包括用于实施指定的逻辑功能的一个或多个可执行指令。在一些替代实施方式中,块中所提及的功能可以不按图中所提及的顺序发生。例如,连续示出的两个块实际上可以基本上同时执行,或者这些块有时可以以相反的顺序执行,这取决于所涉及的功能。还将注意,框图和/或流程图的每个块以及框图和/或流程图中的块的组合,可以由专用的基于硬件的系统来实施,该系统执行指定功能或动作,或执行专用硬件和计算机指令的组合。
[0079]
现在转到图4,示出了用于实施本文所呈现的方法中的一个或多个的装置400的框图。仅作为示例,装置400可以被配置为执行图2a
‑
图2c的方法200的一个或多个步骤。
[0080]
装置400包括计算机系统410和可移动介质450。计算机系统410包括处理器设备420、网络接口425、存储器430、媒体接口435和可选的显示器440。网络接口425允许计算机系统410连接到网络,而媒体接口435允许计算机系统410与例如硬盘驱动器或可移动介质450等的媒体交互。
[0081]
处理器设备420可以被配置成实施本文公开的方法、步骤和功能。存储器430可以是分布式的或本地的,并且处理器设备420可以是分布式的或单独的。存储器430可以被实
施为电、磁或光存储器,或者这些或其他类型的存储设备的任何组合。此外,术语“存储器”应当被足够宽泛地解释为包含能够被由处理器设备420访问的可寻址空间中的地址读取或向其写入的任何信息。利用该定义,通过网络接口425可访问的网络上的信息仍然在存储器430内,因为处理器设备420可以从网络取得信息。应当注意,构成处理器设备420的每个分布式处理器通常包含其自己的可寻址存储器空间。还应当注意,计算机系统410的一些或全部可以被并入专用或通用集成电路中。
[0082]
可选显示器440是适合于与装置400的人类用户交互的任何类型的显示器。一般情况下,显示器440是计算机监视器或其它类似的显示器。
[0083]
尽管本文已经描述了本发明的说明性实施例,但是应当理解,本发明不限于这些精确的实施例,并且本领域技术人员可以在不脱离本发明范围的情况下进行各种其他改变和修改。
[0084]
在本发明的一个示例中,提供了一种用于具有噪声和信号管理的ann训练的方法,该方法包括以下步骤:提供rpu器件的阵列,该rpu器件的阵列具有被配置为处理到该阵列的输入向量x的n个元素的大小为g的集合组的预归一化器,以及具有被配置为处理来自该阵列的输出向量y的m个元素的大小为g的集合组的后归一化器,其中,阵列表示具有m行和n列的ann的权重矩阵,其中,权重矩阵的权重值被存储为rpu器件的电阻值;跨n个向量计算属于每个预归一化器的集合组的输入向量x的所有元素的平均值和标准偏差,产生预归一化器的当前平均值和标准偏差值,其中,平均值和标准偏差是在乘以输入值上计算的;用折扣因子更新预归一化器的先前存储的平均值和标准偏差值,预归一化器的当前平均值和标准偏差值产生预归一化器的更新的存储的平均值和标准偏差值;使用预归一化器的更新的存储的平均值和标准偏差值将乘以输入值预归一化,从所有预归一化器产生归一化的输入向量,以通过阵列与前向循环传递中的模拟噪声一起计算;跨n个向量计算属于每个后归一化器的集合组的输出向量y的所有元素的平均值和标准偏差,产生后归一化器的当前平均值和标准偏差值,其中,平均值和标准偏差是在乘以输入值上计算的;用折扣因子更新后归一化器的先前存储的平均值和标准偏差值,后归一化器的当前平均值和标准偏差值产生后归一化器的更新的存储的平均值和标准偏差值;使用后归一化器的更新的存储的平均值和标准偏差值将乘以输出值后归一化,从所有后归一化器产生归一化的输出向量;使用先前的标准偏差变换n个输入向量,产生变换的输入向量,通过将n个输入向量除以后归一化器的先前的标准偏差,以产生变换的输入向量,以通过阵列与反向循环传递中的模拟噪声一起计算;以及使用预归一化器的先前的标准偏差变换n个输出向量,以产生变换的输出向量,通过将n个输入向量除以后归一化器的先前的标准偏差,以产生变换的输入向量。
[0085]
优选地,该方法还包括以下步骤:将归一化的输入向量转换成模拟脉冲宽度;使用阵列与模拟噪声一起进行计算;并以数字形式表示来自阵列的输出向量y。
[0086]
优选地,该方法还包括以下步骤:将归一化的输入向量转换成模拟脉冲宽度;使用阵列与模拟噪声一起进行计算;并以数字形式表示来自阵列的n个输出向量。
[0087]
在本发明的一个示例中,提供了一种用于具有噪声和信号管理的ann训练的方法,该方法包括以下步骤:提供rpu器件的阵列,该rpu器件的阵列具有被配置为处理到该阵列的输入向量x的n个元素的大小为g的集合组的预归一化器,以及具有被配置为处理来自该阵列的输出向量y的m个元素的大小为g的集合组的后归一化器,其中,阵列表示具有m行和n
列的ann的权重矩阵,其中,权重矩阵的权重值被存储为rpu器件的电阻值;初始化预归一化器和后归一化器中的每一个以使存储值被设置为0,且存储值被设置为1;跨n个向量计算属于每个预归一化器的集合组的输入向量x的所有元素的平均值和标准偏差,产生预归一化器的当前平均值和标准偏差值,其中,平均值和标准偏差是在乘以输入值上计算的;用折扣因子更新预归一化器的先前存储的平均值和标准偏差值,预归一化器的当前平均值和标准偏差值产生预归一化器的更新的存储的平均值和标准偏差值;使用预归一化器的更新的存储的平均值和标准偏差值将乘以输入值预归一化,从所有预归一化器产生归一化的输入向量,以通过阵列与前向循环传递中的模拟噪声一起计算;跨n个向量计算属于每个后归一化器的集合组的输出向量y的所有元素的平均值和标准偏差,产生后归一化器的当前平均值和标准偏差值,其中,平均值和标准偏差是在乘以输入值上计算的;用折扣因子更新后归一化器的先前存储的平均值和标准偏差值,后归一化器的当前平均值和标准偏差值产生后归一化器的更新的存储的平均值和标准偏差值;使用后归一化器的更新的存储的平均值和标准偏差值将乘以输出值后归一化,从所有后归一化器产生归一化的输出向量;使用先前的标准偏差变换n个输入向量,产生变换后的输入向量,以通过阵列与反向循环传递中的模拟噪声一起计算,这通过以下步骤来进行:i)计算n个输入向量的输出值的平均值,计算n个输入向量的乘以输出值与来自前向循环传递的输出向量的值之间的互相关,将n个输入向量的乘以输出值中的每一个减去计算为乘的第一项,然后减去计算为来自前向循环传递的输出向量的值的第二项,并且将n个输入向量除以用于后归一化器的先前标准偏差,以产生变换的输入向量;以及通过计算n个输入向量的乘以输出值的平均值、计算n个输入向量的乘以输出值与前向循环传递的输出向量的值之间的互相关、将n个输入向量的乘以输出值中的每一个减去计算为乘的第一项、然后减去计算为乘以前向循环传递的输出向量的值的第二项、以及将n个输入向量除以用于后归一化器的先前标准偏差以产生变换的输入向量,来使用用于前归一化器的先前标准偏差变换n个输出向量以产生变换的输出向量。
[0088]
优选地,该方法还包括以下步骤:将归一化的输入向量转换成模拟脉冲宽度;使用阵列与模拟噪声一起进行计算;并以数字形式表示来自阵列的输出向量y。
[0089]
优选地,该方法还包括以下步骤:将归一化的输入向量转换成模拟脉冲宽度;使用阵列与模拟噪声一起进行计算;并以数字形式表示来自阵列的n个输出向量。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1