一种基于多模态数据的面向手写中文的性格识别方法
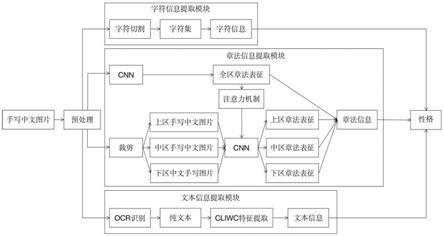
1.本发明涉及图像处理和自然语言处理领域,具体来说,涉及一种基于多模态数据的面向手写中文的性格识别方法。
背景技术:
2.性格被定义为个体对现实的态度以及其相应行为方式的综合表现,是个体最重要的属性之一。在教育领域,由于学生的学习动机、对教学风格的偏好等会受到他们性格的影响,因此性格识别能够帮助老师了解学生对学习的潜在个性需求,从而因材施教、为学生提供更合适的学习方法,提高学生的学习表现和学习满意度;在电商领域,由于性格会影响用户的决策行为,并且性格揭露了用户的偏好信息,因此性格识别能够帮助商家为用户提供合适的商品,从而提高用户的购买率、增加商家的收益;在职场领域,性格识别能够帮助公司分析求职者的抗压能力等,从而筛选出优秀的求职者;在借贷领域,性格识别能够帮助公司分析借贷者是否说谎,从而过滤掉不合格的借贷者。
3.笔迹心理学家表示,笔迹(即,手写文字)是对个体心理无意识的暴露,可以全面反映个体的心理特征。例如,偏向于写正方形字体的人,通常是遵守规则、原则性强的,而偏向于写长方形字体的人,则做事灵活,喜欢追求新奇。偏向于写大字的人,一般富有冒险精神、善于表现自我。而偏向于写小字的人,更加周密严谨、有钻研精神。
4.目前的研究中,研究者们通常基于手写英文进行个体的自动性格识别。例如,分析个体手写的大写字母和小写字母、分析个体手写的特殊字母(“d”、“i”、“t”、“y”)。但是研究者们忽视了对手写中文的使用。有别于英文,中文作为中国人的母语,是特殊的方块字,字体结构对于反应中国人性格具有天然优势。
技术实现要素:
5.本发明的目的在于利用手写中文的结构特点,提供了一种基于多模态数据的面向手写中文的性格识别方法,从手写中文中抽取字符信息、章法信息和文本信息,并将这些多模态数据融合用于分析写作者的性格。
6.实现本发明目的的具体技术方案是:
7.一种基于多模态数据的面向手写中文的性格识别方法,特点是根据手写中文的结构特点识别写作者的性格。该方法包括以下具体步骤:
8.步骤1:预处理
9.将手写中文图片进行缩放、裁剪,达至规定尺寸(长不小于640,宽不小于480);再将手写中文图片转换成二值化图像,记为img
‑
0;
10.步骤2:获取字符信息
11.将img
‑
0进行字符切割,获取字符集h={h1,h2,......,h
k
};k表示字符总数;
12.对于每个字符h
i
(1≤i≤k):
13.(1)判断h
i
的四方轮廓类别o
i
,是正方形即高度等于宽度、长方形即高度大于宽度、
还是扁方形即高度小于宽度;
14.(2)计算h
i
的字体大小s
i
;
15.(3)计算h
i
的字体倾斜角度a
i
;
16.对o={o1,o2,......,o
k
},计算其中正方形字体的占比、长方形字体的占比以及扁方形字体的占比,作为字符集的四方轮廓信息o;
17.以5mm*5mm为标准大小,对s={s1,s2,......,s
k
},计算其中字体大于标准大小的占比、字体小于标准大小的占比,作为字符集的大小程度信息s;
18.以90
°
为标准角度,字体倾斜角度大于90
°
记为字体向左倾斜,字体倾斜角度小于90
°
记为字体向右倾斜。对a={a1,a2,......,a
k
},计算其中字体向左倾斜的占比、字体向右倾斜的占比,作为字符集的倾斜程度信息a;
19.对于每个字符h
i
(2≤i≤k),计算h
i
相对于h
i
‑1的水平距离d
i,i
‑1。对d={d
1,0
,d
2,1
,......,d
k,k
‑1}计算算术平均数,作为字符集的字间距信息d;
20.将字符集的四方轮廓信息o、大小程度信息s、倾斜程度信息a和字间距信息d组合为向量c,作为img
‑
0的字符信息;
21.步骤2:获取章法信息
22.将img
‑
0送入卷积神经网络(convolutional neural networks,cnn),得到全区章法表征i0;
23.将img
‑
0按长度裁剪为三等份,分别为上区手写中文图片img
‑
1、中区手写中文图片img
‑
2和下区手写中文图片img
‑
3;
24.将img
‑
1送入cnn,并使用i0作为注意力机制,得到上区章法表征i1;
25.将img
‑
2送入cnn,并使用i0作为注意力机制,得到中区章法表征i2;
26.将img
‑
3送入cnn,并使用i0作为注意力机制,得到下区章法表征i3;
27.将i0、i1、i2和i3拼接得到i,作为img
‑
0的章法信息;
28.步骤3:获取文本信息
29.通过光学字符识别(optical character recognition,ocr),将img
‑
0中的手写中文转换成纯文本z;
30.从纯文本z中抽取cliwc(chineselinguistic inquiry and word count)特征,记为t,作为手写中文的文本信息;
31.步骤4:性格预测
32.将字符信息c、章法信息i、文本信息t拼接,经过线性计算得到结果f。f是n维向量,每一维表示写作者在对应性格特质上的得分,n表示性格特质总数。具体公式如公式(1)所示:
33.f=w
f
[c;i;t]+b
f
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0034]
其中w
f
是权重矩阵,b
f
是偏置项。
[0035]
本发明的有益效果在于:
[0036]
本发明相比现有技术,具有更高的准确率和更强的可解释性。本发明充分使用了手写中文的字符信息、章法信息和文本信息,从而能够更好地理解写作者的性格,并对预测结果给出更加合理的解释。本发明适用于任何手写中文的场景。
附图说明
[0037]
图1是本发明的流程图。
具体实施方式
[0038]
结合以下具体实施例和附图,对本发明作进一步的详细说明。实施本发明的过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公识常识,本发明没有特别限制内容。
[0039]
参阅图1,本发明从手写中文中抽取字符信息、章法信息和文本信息,再融合这些多模态数据进行写作者的性格识别,提高了性格识别的准确率和预测结果的可解释性。
[0040]
实施例
[0041]
本实施例为某高校学生(以下简称u)的真实手写中文图片。通过tipi性格问卷衡量u的大五性格,其中u在开放性上的得分为6.0、在尽责性上的得分为4.5、在外向性上的得分为3.5、在宜人性上的得分为3.5、在神经质性上的得分为5.0。对u进行性格特征总数为5的的性格识别任务,其具体操作按下述步骤进行:
[0042]
步骤1:预处理
[0043]
将u的手写中文图片进行缩放、裁剪,达至规定尺寸(1024*768);再将手写中文图片转换成二值化图像,记为img
‑
0;
[0044]
步骤2:获取字符信息
[0045]
将img
‑
0进行字符切割,获取字符集h={h1,h2,......,h
k
},其中k=344,表示字符总数;
[0046]
对于每个字符h
i
(1≤i≤k):
[0047]
(1)判断h
i
的四方轮廓类别o
i
;
[0048]
(2)计算h
i
的字体大小s
i
;
[0049]
(3)计算h
i
的字体右倾角度a
i
;
[0050]
对o={正方形,长方形,正方形,正方形,......,正方形},计算其中正方形的占比(62.64%)、长方形的占比(33.25%)以及扁方形的占比(4.11%),作为字符集的四方轮廓信息o=[62.64%,33.25%,4.11%];
[0051]
对s={21.16mm2,23.92mm2,20.25mm2,21.16mm2,......,20.25mm2},以5mm*5mm为标准大小,计算其中字体大于标准大小的占比(10.28%)、字体小于标准大小的占比(89.72%),作为字符集的大小程度信息s=[10.28%,89.72%];
[0052]
以90
°
为标准角度,字体右倾角度大于90
°
记为字体向左倾斜,字体右倾角度小于90
°
记为字体向右倾斜。对a={89
°
,88
°
,89
°
,89
°
,......,91
°
},计算其中字体向左倾斜的占比(2.65%)、字体向右倾斜的占比(97.35%),作为字符集的倾斜程度信息a=[2.65%,97.35%];
[0053]
对于每个字符h
i
(2≤i≤k),计算h
i
相对于h
i
‑1的水平距离d
i,i
‑1;对d={1.74mm,1.43mm,2.02mm,1.32mm,......,1.22mm}计算算术平均数(1.63mm),作为字符集的字间距信息d=1.63;
[0054]
将字符集的四方轮廓信息o、大小程度信息s、倾斜程度信息a和字间距信息d组合为向量c=[62.64%,33.25%,4.11%,10.28%,89.72%,2.65%,97.35%,1.63],作为
img
‑
0的字符信息;
[0055]
步骤2:获取章法信息
[0056]
将img
‑
0送入卷积神经网络(convolutional neural networks,cnn),得到章法表征i0;
[0057]
将img
‑
0按长度裁剪为三等份,分别为上区手写中文图片img
‑
1、中区手写中文图片img
‑
2和下区手写中文图片img
‑
3;
[0058]
将img
‑
1送入cnn,并使用i0作为注意力机制,得到章法表征i1;
[0059]
将img
‑
2送入cnn,并使用i0作为注意力机制,得到章法表征i2;
[0060]
将img
‑
3送入cnn,并使用i0作为注意力机制,得到章法表征i3;
[0061]
将i0、i1、i2和i3拼接得到i,作为img
‑
0的章法信息;
[0062]
步骤3:获取文本信息
[0063]
通过光学字符识别(optical character recognition,ocr),将img
‑
0中的手写中文转换成纯文本z;
[0064]
从纯文本z中抽取cliwc(chineselinguistic inquiry and word count)特征,记为t,作为手写中文的文本信息;
[0065]
步骤4:性格预测
[0066]
将字符信息c、章法信息i、文本信息t拼接,经过线性计算得到结果f;f=[6.0,4.5,3.5,3.5,5.0],表示预测u在开放性上的得分为6.0、在尽责性上的得分为4.5、在外向性上的得分为3.5、在宜人性上的得分为3.5、在神经质性上的得分为5.0。具体公式如公式(1)所示:
[0067]
f=w
f
[c;i;t]+b
f
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0068]
以上实施例只是对本发明做进一步说明,并非用以限制本发明,凡为本发明的等效实施,均应包含于本发明的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1