一种针对大规模Hadoop集群资源调度管理办法的制作方法
一种针对大规模hadoop集群资源调度管理办法
技术领域
1.本发明涉及集群资源调度技术领域,具体涉及一种针对大规模hadoop集群资源调度管理办法。
背景技术:
2.随着企业内hadoop集群持续使用,其节点规模不断扩张,不仅仅存储系统会有性能瓶颈问题,计算系统资源调度也存在性能瓶颈问题,比如resourcemanager服务,作为集群的资源管理器,基于应用程序对资源的需求进行调度。当resourcemanager下面管理着上千甚至上万个nodemanager节点时,会面临着许多性能问题,大量同时在跑的应用所触发的待处理的event数等待问题,导致任务运行获取资源效率差。一般这种情况,一个简单直接的方案是再搭建一个新的yarn集群。因为hadoop中存储和计算是可以分离的,所以独立搭建yarn完全没有任何问题。之后引流一部分在线任务到新的yarn集群即可分担单集群的压力了。但是这套简单直接的方法会造成日后多个独立集群管理的不便,而且更为重要的一点是它无法保证资源的更高使用率,无法保证每个集群在资源空闲的时候能够及时地安排上任务执行。
技术实现要素:
3.针对现有技术的不足,本发明旨在提供一种针对大规模hadoop集群资源调度管理办法,解决resourcemanager的扩展性问题。
4.为了实现上述目的,本发明采用如下技术方案:
5.一种针对大规模hadoop集群资源调度管理办法,具体过程为:
6.各个yarn子集群通过心跳汇报状态信息,各yarn子集群汇报的状态信息被持久化到了信息持久化存储器中;
7.策略生成角色根据集群的状态信息将相关调度策略信息写入策略信息存储器中;
8.客户端向路由器提交应用请求,路由器与策略信息存储器进行交互,获取策略信息,据此选择一个目标的子集群,然后将客户端的应用请求转发到目标的子集群上,同时提交的应用请求id和目标子集群id映射信息会被保存入信息持久化存储器中。
9.进一步地,所述信息持久化存储器是可选择的,基于memory、zk based或是sql based的都支持。
10.进一步地,路由器会对查询来的信息做高速缓冲处理。
11.本发明的有益效果在于:本发明通过设置一个全局控制各个rm的路由器,可获取并根据各个集群的状态信息来选择目标的子集群,实现集群资源的调度和管理,既可以方便各个子集群的管理,又可以提高资源的利用率。
附图说明
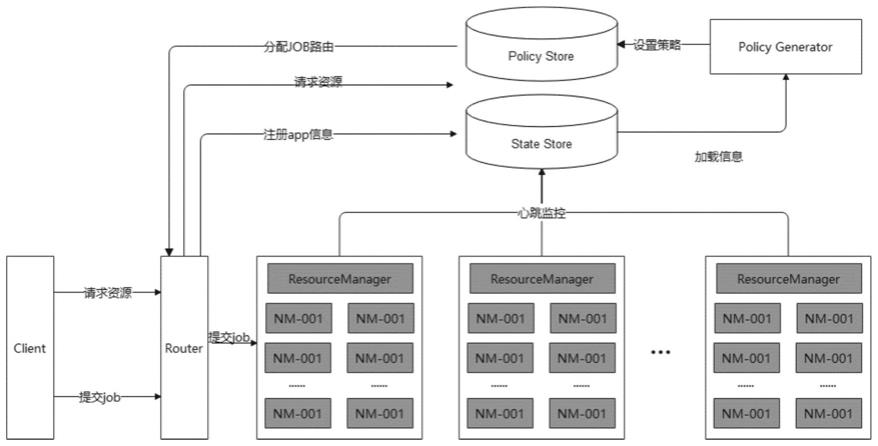
12.图1为本发明实施例中的方法实施的架构示意图。
具体实施方式
13.以下将结合附图对本发明作进一步的描述,需要说明的是,本实施例以本技术方案为前提,给出了详细的实施方式和具体的操作过程,但本发明的保护范围并不限于本实施例。
14.本实施例提供一种针对大规模hadoop集群资源调度管理办法,主要涉及两方面,多集群状态信息收集和存储以及客户端请求路由服务实现。
15.本年实施例的资源调度管理办法的一个重要目标是让众多独立小集群变为逻辑意义上的一个超大资源池。对于客户端来说,它直接面对的将不是众多具体的独立小集群。而要做到统一大集群资源,首先需要知道有哪些集群信息,包括集群id、地址、容量使用等等。而且需要将这些信息进行持久化操作,这样可以做到服务间的信息共享。另外,在客户端和背后多yarn小集群之间,需要有一个路由器router的角色,实现智能的请求转发,这个角色有点load balancer的意思,又可以理解为是一个proxy的role。router需要用到之前持久化的多集群信息。其次,本实施例方法中,路由策略也会根据各个集群的状态信息实现目标集群的选择。
16.如图1所示,state store部分即为信息持久化存储器。policy store为策略信息存储器,是由专门的策略生成类进行存放的。
17.一种针对大规模hadoop集群资源调度管理办法的具体过程为:
18.各个yarn子集群(主要指resourcemanager)通过心跳汇报状态信息,各yarn子集群汇报的状态信息被持久化到了信息持久化存储器state store中。所述state store是可选择的,基于memory、zk based或是sql based的都支持。
19.策略生成角色policy generator根据集群的状态信息将相关调度策略信息写入策略信息存储器policy store中。
20.客户端向路由器router提交应用请求,路由器与策略信息存储器进行交互,获取策略信息,据此选择一个目标的子集群cluster,然后将客户端的应用请求转发到目标的子集群上,同时提交的应用请求id和目标子集群id映射信息会被保存入信息持久化存储器state store中。这是为了后续查询的方便,同样也是为了router重启时应用状态的恢复。
21.本实施例方法中,为了性能上的考虑,减少频繁的信息获取,路由器router会对查询来的信息做高速缓冲(cache)处理。
22.对于本领域的技术人员来说,可以根据以上的技术方案和构思,给出各种相应的改变和变形,而所有的这些改变和变形,都应该包括在本发明权利要求的保护范围之内。
技术特征:
1.一种针对大规模hadoop集群资源调度管理办法,其特征在于,具体过程为:各个yarn子集群通过心跳汇报状态信息,各yarn子集群汇报的状态信息被持久化到了信息持久化存储器中;策略生成角色根据集群的状态信息将相关调度策略信息写入策略信息存储器中;客户端向路由器提交应用请求,路由器与策略信息存储器进行交互,获取策略信息,据此选择一个目标的子集群,然后将客户端的应用请求转发到目标的子集群上,同时提交的应用请求id和目标子集群id映射信息会被保存入信息持久化存储器中。2.根据权利要求1所述的方法,其特征在于,所述信息持久化存储器是可选择的,基于memory、zk based或是sql based的都支持。3.根据权利要求1所述的方法,其特征在于,路由器会对查询来的信息做高速缓冲处理。
技术总结
本发明公开了一种针对大规模Hadoop集群资源调度管理办法,通过设置一个全局控制各个RM的路由器,可获取并根据各个集群的状态信息来选择目标的子集群,实现集群资源的调度和管理,从而既可以方便各个子集群的管理,又可以提高资源的利用率。提高资源的利用率。
技术研发人员:于洋 高经郡
受保护的技术使用者:北京科杰科技有限公司
技术研发日:2021.10.27
技术公布日:2022/1/21
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1