一种基于自监督学习的视频聚类方法
1.本申请涉及计算机视觉领域,尤其涉及一种基于自监督学习的视频聚类方法。
背景技术:
2.聚类是一种广泛应用于机器学习、数据挖掘和统计分析等领域的技术。它的目的是将彼此相似的对象归为相同的集合,不同的对象归为不同的集合。视频聚类的目的是将同类视频归为同一类,不同类别的视频归为不同类。与传统视频分类方法不同,视频聚类方法无需考虑视频的真实标签。传统的聚类方法,如kmeans和谱聚类,当它们应用于视频数据时,需要特定的特征提取方式,并且存在聚类边界消失等问题。对于高维的视频数据,传统方法无法保证特征信息得到有效利用,从而导致性能低下。
3.由于近年来深度神经网络的发展,基于深度学习的聚类方法得到提升。许多研究将深度神经网络与深度聚类方法的损失函数结合,以学习更适合聚类的视频特征表示。最近自监督特征学习在视频识别任务中表现优异。在提取视频帧的特征值的过程中,主要的挑战来源于经典特征提取方法更适用于特征分类,而不是聚类。因此,可以将深度聚类方法与自监督视频特征学习结合,以得到适合聚类的视频特征。
技术实现要素:
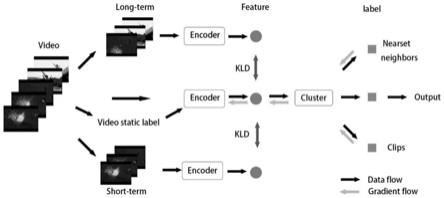
4.发明目的:在本文中,我们没有对提取到的视频特征直接进行分类以完成识别任务,而是通过从rgb和光流不同视角上分别计算最近邻,拉近与其最近邻的特征值的距离,使视频特征具有聚类特性,利用聚类和重建损失函数实现自监督的视频聚类,从而完成自监督视频识别任务。本发明提供了一种基于自监督学习的视频聚类方法。
5.技术方案:一种基于自监督学习的视频聚类方法,其特征在于:包括以下步骤:
6.步骤一:对视频vi使用两种不同进行采样策略进行采样,得到包含全局信息的序列v
i_l
和包含局部信息的序列v
i_s
;
7.步骤二:对视频vi分别在rgb和光流上进行编码,得到特征值f1(vi),f2(vi);
8.步骤三:设rgb中特征值f1(vi)在f1(v)中的k个最近邻为f1(v
i1
),...,f1(v
ik
),拉近对应光流特征值的距离,即f2(vi)与f2(v
i1
),...,f2(v
ik
)的距离;
9.步骤四:重复步骤三,拉近由光流最近邻指导的rgb特征值的距离;
10.步骤五:由于同一视频不同片段属于同一类别,拉近f1(vi)与f1(v
i_s
)和f1(v
i_l
)的距离;
11.步骤六:对数据集v中的每个视频vi提取视频帧x
ij
;
12.步骤七:采用条件变分自编码器对所有的x进行图片聚类,得到视频静态标签;
13.步骤八:利用步骤三、四、五中得到的视频特征值,结合步骤七得到的视频静态标签进行视频聚类,得到视频聚类标签。
14.进一步的,步骤一中,序列v
i_l
采用的采样策略为将视频分割为等长的片段,并从每个片段中选取一帧组成新序列;序列v
i_s
采用的采样策略为随机选取一个起点,截取定长
(v
i_s
)和f1(v
i_l
)的距离;
34.步骤六:对数据集v中的每个视频vi提取视频帧x
ij
;
35.步骤七:采用条件变分自编码器对所有的x进行图片聚类,得到视频静态标签;
36.步骤八:利用步骤三、四、五中得到的视频特征值,结合步骤七得到的视频静态标签进行视频聚类,得到视频聚类标签,采用kmeans对视频特征值进行聚类,并通过聚类损失函数更新特征值,所述聚类损失函数定义为最近邻的对数似然损失,加上交叉熵损失,以防止聚类退化。
37.在本实施例中,ucf101动作数据集由101类人物动作视频组成,共计13320个视频,涵盖常见的人类动作类别,包括弹钢琴、跳水、骑自行车、打棒球等。视频帧为320
×
240的彩色图像。
38.在训练时,设置adam优化器的学习率为1
×
10-4
。特征编码器损失为聚类损失和自监督视频特征两个损失的加权和,方差损失权重λ设为10-2
。聚类损失中,交叉熵损失函数权重设为2。视频特征提取前将视频帧随机裁剪为224
×
224的彩色图像以进行s3d编码。模型训练300次,批大小设为128。
39.在ucf101数据集上比较了基于rgb和光流的最新自监督视频学习方法(coclr)和我们的方法。结果如图3所示,我们方法表现好于coclr。在视频聚类准确度方面,我们的方法比coclr+kmeans高7.0%,聚类评价指标ari高了0.0735。在ucf101子集ucf10上,我们的方法比coclr+kmeans高18.9%,聚类评价指标ari高了0.1803。主要原因是当前的自监督视频特征提取算法获得的视频特征,不具备适合分类的特性。这也意味着本发明提出的算法在实际应用中具有很大的优势。
技术特征:
1.一种基于自监督学习的视频聚类方法,其特征在于:包括以下步骤:步骤一:对视频v
i
使用两种不同采样策略进行采样,得到包含全局信息的序列v
i_l
和包含局部信息的序列v
i_s
;步骤二:对视频v
i
分别在rgb和光流上进行编码,得到特征值f1(v
i
),f2(v
i
);步骤三:所述视频的rgb特征值f1(v
i
)在f1(v)中的k个最近邻为f1(v
i1
),...,f1(v
ik
),拉近对应光流特征值的距离,即f2(v
i
)与f2(v
i1
),...,f2(v
ik
)的距离;步骤四:重复步骤三,拉近由光流最近邻指导的rgb特征值的距离;步骤五:由于同一视频不同片段属于同一类别,拉近f1(v
i
)与f1(v
i_s
)和f1(v
i_l
)的距离;步骤六:对数据集v中的每个视频v
i
提取视频帧x
ij
;步骤七:采用条件变分自编码器对所有的x进行图片聚类,得到视频静态标签;步骤八:利用步骤三、四、五中得到的视频特征值,结合步骤七得到的视频静态标签进行视频聚类,得到视频聚类标签。2.根据权利要求1所述的基于自监督的视频聚类方法,其特征在于:步骤一中,序列v
i_l
采用的采样策略为将视频分割为等长的片段,并从每个片段中选取一帧组成新序列;序列v
i_s
采用的采样策略为随机选取一个起点,截取定长的视频片段作为新序列。3.根据权利要求1所述的基于自监督的视频聚类方法,其特征在于:步骤二中,所述编码采用s3d网络进行特征提取。4.根据权利要求1所述的基于自监督的视频聚类方法,其特征在于:步骤三中,用归一化温度-尺度交叉熵损失来拉近f2(v
i
)与f2(v
i1
),...,f2(v
ik
)距离。5.根据权利要求1所述的基于自监督的视频聚类方法,其特征在于:步骤五中,使用相对熵损失拉近f1(v
i
)与f1(v
i_s
)和f1(v
i_l
)的距离。6.根据权利要求1所述的基于自监督的视频聚类方法,其特征在于:步骤六中,提取视频rgb下的图片帧。7.根据权利要求1所述的基于自监督的视频聚类方法,其特征在于:步骤七中,条件变分自编码器对图片进行聚类,其中帧所在的视频标签将作为自编码器的条件输入。8.根据权利要求1所述的基于自监督的视频聚类方法,其特征在于:步骤八中,采用kmeans对视频特征值进行聚类,并通过聚类损失函数更新特征值。9.根据权利要求8所述的基于自监督的视频聚类方法,其特征在于:所述聚类损失函数定义为最近邻的对数似然损失,加上交叉熵损失,以防止聚类退化。
技术总结
本发明公开了一种基于自监督的视频聚类方法。该方法利用自监督的方式,学习得到视频在RGB和光流中的特征值,并对该特征值进行聚类。为了实现这一目标,将计算视频在RGB和光流中最近邻作为代理任务,实现无标签的视频特征提取。此外,对视频的每帧图片进行图片聚类,每个视频中出现次数最高的聚类标签作为视频的静态聚类标签。最后,将直接对视频提取得到的聚类特征作为视频的动态特征,结合静态聚类标签得到最终视频聚类结果。本发明可以在视频识别的数据集上提取具有判别性的特征表示,有效的提高了视频对齐问题的准确率。的提高了视频对齐问题的准确率。的提高了视频对齐问题的准确率。
技术研发人员:张宇 米思娅 王梓骅
受保护的技术使用者:东南大学
技术研发日:2022.01.10
技术公布日:2022/5/6
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1