基于姿态与样式归一化的换衣行人重识别方法与流程
1.本发明涉及计算机视觉、模式识别等技术领域,主要涉及的是监控视频中行 人的身份重识别,它在预防犯罪、智慧城市和社会治安等方面具有广泛的应用。
背景技术:
2.行人重识别作为智慧城市中一个非常重要的应用,在计算机视觉领域中被广 泛研究。早期行人重识别主要通过手工构建行人特征或者距离度量学习。随着深 度学习在计算机视觉领域的广泛应用,基于深度学习的行人重识别技术开始迅速 发展,并且在封闭世界环境中取得了良好的性能。
3.基于深度学习的行人重识别方法主要针对姿态、光照、背景噪声等问题进行 研究的,其中qian等人在2018年提出了一种基于生成对抗网络的姿态归一化方 法,但是该方法需要openpose等第三方辅助工具,增加了网络模型的规模,使 得行人重识别的预处理工作变得复杂。zheng等人提出的dg-net虽无需第三方 辅助工具,但其严重依赖于服装外观一致性,其身份信息主要由外观特征为主导, 在姿态互换时强制将衣服相同的不同行人判断为同一行人,这种误判现象会导致 识别精度下降。这些方法只适用于短期捕获的行人再识别场景,限制了行人重识 别在实际场景中的应用。
4.为了解决模型依赖服装外观一致性的问题,一些研究对换衣行人重识别进行 了初步探索。li等人在2020年提出了angle specific extractor(ase)模块来建 模不同通道之间的关系,尝试从行人轮廓的角度进行行人重识别,一定程度上消 除了服装颜色变化带来的影响。虽然行人轮廓短期内可能不会改变,但在长期捕 获行人图像的过程中,其易受服装款式的变化而不再具有鲁棒性。yu等人提出 了biometric drows network(bc-net)的双分支结构,分别学习行人生物特征和 衣服特征,衣服检测器和特征提取器是分别进行训练的,该方法主要使检索库的 行人换上画廊图库中行人的衣服,从而保证行人匹配过程中服装外观一致性,但 是该方法需要大量繁杂的预处理过程,还需要第三方衣服模板作为辅助数据,大 大增加了行人重识别的工作量。
5.针对短期捕获的行人重识别技术已经取得了巨大的进展,但是在真实的应用 场景下,短期捕获的行人数据集可能无法适用于换衣场景下的识别需求,因此为 了解决这种问题,提出了一种基于姿态与样式归一化的换衣行人重识别方法。
技术实现要素:
6.发明目的:在现实场景中,人们往往会在几天内身穿不同衣服,这就导致在 长期捕获行人图像的过程中不同时间不同相机拍摄到的行人可能身穿不同衣服, 而目前的换衣行人重识别仍然停留在实验室阶段,现有行人重识别技术都基于短 期捕获的行人数据集进行研究的,对行人服装一致性具有强烈依赖,无法适用于 换衣场景。因此本发明希望通过将生成对抗网络和归一化技术结合,解决换衣场 景下的行人重识别问题,从而使得行人重识别技术能够真正落到实处,为社会保 障方面节省更多的资源。
7.1、一种基于姿态与样式归一化的换衣行人重识别方法,其特征在于,包括 以下步骤:
8.步骤1.1:使用姿态编码器与服装外观编码器对目标图库与检索图库中的行 人进行姿态特征与服装外观特征的提取,并利用解码器进行交叉重建与自我重建。
9.步骤1.2:将生成的行人图像通过归一化模块进行样式擦除,利用内容注意 力机制恢复因擦除丢失的内容鉴别性特征;
10.步骤1.3:擦除后的行人特征通过双通道结构将利用姿态估计获取的行人局 部特征和利用主干网络提取的全局特征进行特征融合;
11.步骤1.4:通过欧氏距离度量,输出行人的身份信息。
12.2、根据权利要求1所述的一种姿态与样式归一化的换衣行人重识别方法, 其特征在于,所述步骤1.1中行人姿态服装互换的方法如下:
13.步骤2.1:利用姿态编码器与外观编码器分别对行人的姿态与服装外观进行 特征提取;
14.步骤2.2:将解耦出的行人姿态特征与服装外观特征交叉组合,利用解码器 生成同一姿态不同服装以及同一服装不同姿态的行人图像;
15.步骤2.3:通过判别器来判断生成的图像是否逼真,并采用对抗性损失来匹 配生成图像的分布与实际数据分布,其中对抗约束如下:
[0016][0017]
其中xi∈d
query
,d
query
={xi|i=1,2,...,n},d
query
是指query里的目标行人数 据集,其中n是数据集中的样本数量。d是判别器,g是生成器,f
ip
,分别 代表xi的姿态特征和xj的服装外观特征,其中xj∈d
gallery
,d
gallery
是指gallery里 的行人数据集,同理,gallery库里的行人生成亦是如此。
[0018]
3、根据权利要求2所述的行人姿态服装互换方法,其特征在于,步骤2.2 中姿态服装特征交叉生成的方法为:
[0019]
步骤3.1:利用姿态编码器和服装外观编码器提取姿态特征和服装外观特征, 在提取姿态特征时将原始图像转化为灰度图,使得网络在提取姿态特征时更倾向 于空间结构特征,从而确保提取的姿态特征不包含其他噪声。
[0020]
步骤3.2:将提取到的姿态特征与服装外观特征交叉融合后进行图像生成, 并对生成的图像进行二次编码,利用重建损失对解耦出的特征进行约束,重建损 失如下:
[0021][0022]
其中e
p
是指姿态编码器,ea是服装外观编码器,是对原始图像xi中的姿态特征f
ip
与生成图像所解耦出的姿态特征进行距离计算, 其中f
ip
=e
p
(xi),同理,是对原始图像xj中的服装外观特征与生成图像所解耦出的服装外观特征进行距离计算。
[0023]
4、根据权利要求1所述的一种基于姿态与样式归一化的换衣行人重识别方 法,其特征在于,所述步骤1.2中通过归一化模块进行样式擦除的方法:
[0024]
步骤4.1:将生成的一组姿态服装互换行图像通过实例归一化操作进行样式 擦除;
[0025]
步骤4.2:将输入特征与实例归一化后的特征做差,得到实例归一化过程中 擦除掉的剩余特征;
[0026]
步骤4.3:采用通道注意力机制从剩余特征中提取内容相关特征;
[0027]
步骤4.4:将内容相关特征与实例归一化后的的特征进行特征融合,获取不 具有样式风格的行人特征。
[0028]
5、根据权利要求4所述的步态识别模型,其特征在于,步骤4.3中的基于 通道注意力机制的内容特征提取方法为:
[0029]
步骤5.1:将每个通道的d=h
×
w维特征向量作为一个特征节点,从而形成 一个具有c个节点的图gc,每个特征节点与其它节点的关系通过嵌入函数映射 到亲和矩阵
[0030]
步骤5.2:将每一行节点的关系向量表示为每一列节点的关系 向量表示为将其在空间上进行展平,然后使用1x1卷积层进行批量归一化, 通过relu激活来执行映射变换,从而实现节点关系的嵌入,并获得通道注意力α,其表示 为:
[0031]
α=g(di)=σ(w2δ(w
1 pool(di)))
[0032]
其中δ(
·
),σ(
·
)分别表示relu激活函数和sigmoid激活函数,)分别表示relu激活函数和sigmoid激活函数,di是指剩余特征,di=f
i-fi=f
i-in(fi),in是实例归一化操作,fi是 输入的原始特征,fi是进行实例归一化后的特征。
[0033]
步骤5.3:将剩余特征与通道注意力结合从而获得内容相关特征d
i+
,将内容相 关特征与实例归一化特征连接,从而获取不具有样式风格的鲁棒行人特征。
[0034]
本发明的有益结果:
[0035]
在短期捕获的行人重识别技术的基础上,结合生成对抗网络和归一化的相关 技术,提出了一种换衣重识别的解决方案,极大地提高了换衣重识别技术落实到 实际应用中的可能性。
附图说明
[0036]
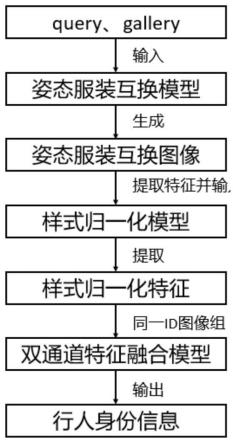
图1是本发明所述的基于姿态与样式归一化的换衣行人重识别方法的核心 结构示意图;
[0037]
图2是基于姿态与样式归一化的行人识别整体模型意图;
[0038]
图3是姿态服装互换模型示意图;
[0039]
图4是样式归一化模型示意图;
[0040]
图5是特征融合模块示意图;
[0041]
图6是双通道特征融合示意图。
具体实施方式
[0042]
下面结合附图对本发明作进一步说明。
[0043]
如图1、图2所示,本发明所述的基于姿态与样式归一化的换衣行人重识别 方法,具体过程如下:
[0044]
步骤1:从query和gallery库中分别选取目标行人和图库行人,传输至姿态 服装互换模型,获得相应的姿态服装互换图像,其中姿态服装互换模型如图3 所示:
[0045]
步骤1.1:为了提取行人的姿态与服装外观特征,分别利用姿态编码器 和服装外观编码器进行潜在编码,其中姿态编码器是浅层网络,先经过四个卷积 层进行特征提取,然后接着四个跳跃连接块,其中每个卷积层的输入输出通道都 为256,卷积核的大小为3x3,步幅和填充都为1,随后进行组归一化并采用线 性整流函数作为激活函数。在进行姿态编码时先对原始输入图像1
×
256
×
128进 行灰度化操作即通道数设为1,并经过两个下采样层,防止外观信息进行干扰, 姿态编码器输出的姿态特征尺寸为128
×
64
×
32;服装外观编码器则是利用在 imagenet上预训练好的resnet50进行改进,其中删除了全局平均池化层和完全 连接层,取而代之的是最大池化层,输出的服装外观代码尺寸为2048
×4×
1。
[0046]
步骤1.2:将解耦出的姿态与服装外观特征进行交叉生成,生成器对姿态特 征进行四个残差块和四个卷积层处理并进行两次上采样,每个残差块包含两个 in层,整合了服装外观代码的尺度和偏置参数。
[0047]
步骤1.3:生成后的图像组传输至判别器,判别器可对64
×
32,128
×
64,256
×
128 的图像进行信息判别,并利用生成对抗损失进行约束,使生成图像拟合真实图像 数据分布,生成对抗损失如下:
[0048][0049]
其中xi∈d
query
,d
query
={xi|i=1,2,...,n},d
query
是指query里的目标行人数 据集,其中n是数据集中的样本数量。d是判别器,g是生成器,f
ip
,分别 代表xi的姿态特征和xj的服装外观特征,其中xj∈d
gallery
,d
gallery
是指gallery里 的行人数据集。
[0050]
步骤1.4:对生成图像再次进行姿态与服装外观进行编码,计算生成图像的 特征与原始图像的特征距离,并对解耦出的姿态与外观特征进行重建损失约束, 其中重建损失如下:
[0051][0052][0053]
其中分别是对姿态特征与服装外观特征进行重建约束,是对由f
ip
,组成的行人图像进行姿态特征提取,计算原始图像 中的姿态特征与生成的姿态特征的特征距离,同理,是对由f
ip
, f
ip
,组成的行人图像进行服装外观特征提取并计算其与原始图像的服装外观 特征之间的距离。
[0054]
步骤2:将步骤1获得的姿态、服装外观特征交叉组合之后,生成同一姿态 不同服
装以及同一服装不同姿态的同一id图像。由于生成的图像由两张不同图 像的潜在编码组合而成,在解码过程中会产生行人以外的噪声,将生成的图像与 原始图像一起放入样式归一化模型中,统一进行样式擦除操作,其中样式归一化 模型结构如图4所示:
[0055]
步骤2.1:引入实例归一化对每个通道上空间位置的特征进行归一化, 保留空间结构,减少图像之间的样式差异,实例归一化过程可以表示为:
[0056][0057]
其中μ(
·
)代表每个通道和每个样本在空间维度上独立计算的平均值,σ(
·
)代 表每个通道和每个样本在空间维度上独立计算的标准偏差。γ,β是从数据训练 中学习得到的参数。
[0058]
步骤2.2:将实例归一化后的特征与原始图像做差,从而获取剩余特征,即 di=f
i-fi=f
i-in(fi)。通过内容注意力机制模块将剩余特征中的相关特征进 行提取,其中内容注意力机制是通过学习通道注意力实现,将每个通道的d=h
×
w维特征向量作为一个特征节点,从而形成一个具有c个节点的图gc,每个特 征节点与其它节点的关系通过嵌入函数映射到亲和矩阵将每一行节 点的关系向量表示为每一列节点的关系向量表示为将 其在空间上进行展平,然后使用1x1卷积层进行批量归一化,通过relu激活来 执行映射变换,从而实现节点关系的嵌入,并获得通道注意力α,其表示为:
[0059]
α=g(di)=σ(w2δ(w
1 pool(di)))
[0060]
其中δ(
·
),σ(
·
)分别表示relu激活函数和sigmoid激活函数,)分别表示relu激活函数和sigmoid激活函数,
[0061]
步骤2.3:将提取到的内容相关特征与归一化后的特征进行连接,获取不具 有样式风格的鲁棒行人特征。利用恢复损失来提高特征的鲁棒性,损失如下:
[0062][0063][0064]
其中h(
·
)=-p(
·
)logp(
·
),softplus(
·
)=ln(1+exp(
·
)),是对内容相关特征 进行约束,则是对内容无关特征进行约束,从而确保从剩余特征中解耦出的 相关性特征具有关联性。
[0065]
步骤3:将每个图像的局部特征与全局特征进行特征融合,采用双通道结构 进行身份信息预测与距离度量,双通道特征融合模型如图5所示:
[0066]
步骤3.1:将原始图像、同一姿态不同服装以及同一服装不同姿态的图像作 为一组放入双通道结构,其中每一张图像都进行全局-局部特征融合,特征融合 模块如图6所示。对每一张图,经过4个convblock+sn块并通过全局平局池化 (gap)操作获得全局特征。
[0067]
步骤3.2:为了获取行人的局部语义特征,我们首先使用姿态估计模型来得 到行人的关键点热度图,然后通过对关键点进行矩阵广播和全局平均池化操作来 获取人体局部特征f
l
,最后将全局特征fg与局部特征f
l concatenate在一起, 并使用三元组损失进行约束:
[0068][0069]
其中分别表示正样本与负样本,β是margin。
[0070]
步骤3.3:如图5,为了提高双通道特征融合的性能,我们使用距离度量d 方法来评估图像之间的相似性,并使用距离损失和分类损失进行约束:
[0071][0072][0073]
其中f代表全连接层,分别表示xi经过特征融合模 型得到的特征,我们使用来表示生成的图像与xi具有相同姿态不同 服装,用表示与xi具有相同服装不同姿态。需要注意的是,我们分 别对进行距离度量而非对所有图像之间进行距离计算,这 样可以更好地减少姿态和服装对行人匹配带来的影响。距离度量损失设计如下:
[0074][0075][0076]
分类损失设计:
[0077]
l
cls
=-log(fg)
[0078]
总体而言,基于姿态与样式归一化的换衣行人重识别模型对目标数据集 market-1501进行训练,将训练批次设为64,训练周期为60,使用adam优化 器,一阶矩估计的指数衰减率为0.5,二阶矩估计的指数衰减率为0.5,初始学 习率设为0.1,最后利用损失函数对识别误差与精度进行约束,直至完全收敛。
[0079]
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具 体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技艺精神所作的 等效实施方式或变更均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1