基于链式搜索算法的母系MT单倍群鉴定方法、装置及设备与流程
基于链式搜索算法的母系mt单倍群鉴定方法、装置及设备
技术领域
1.本发明属于线粒体单倍群鉴定技术领域,具体涉及一种基于链式搜索算法的母系mt单倍群鉴定方法、装置及设备。
背景技术:
2.线粒体dna是在细胞核之外独特的环状dna。与父系祖源的y染色体遗传方式不同,受精卵中的线粒体dna一般只来自于母亲提供的卵子,也就是只能由母亲传递给子代(极少例外),后代都会继承几乎与母亲完全相同的的线粒体dna。线粒体dna基因组大小约为16,569个碱基,可以分为控制区和编码区。控制区大小约有1,000个核苷酸,剩下的15,000多个碱基属于编码区。控制区的碱基突变速率较高且较不稳定,而编码区的突变速率较低并比较恒定。利用mtdna全序中编码区的突变,结合控制区突变,线粒体dna基因组全序平均3,000年左右一个突变,适合构建数千至数万年尺度的人类谱系。线粒体单倍群(mtdna haplogroup)就是依据整个线粒体基因组的突变构建的。这样的突变在人类族群数万年的演化历史中会被积累下来,被分子人类学家用于推演族群的演化历史,我们称之为母系祖源。
3.根据不同族群的线粒体dna(mtdna)数据,分子人类学家建立了树状的mtdna单倍群图谱,这个树上每一个节点都对应了一个单倍群,用于代表具有相似突变的线粒体。通过用户检测结果和参考的mtdna单倍群树结构的比较,可以准确推测其mtdna单倍群,从而追溯母系祖源的起源、演化和迁徙历史。因此,如何鉴定母系mt单倍群,对母系祖源的追溯具有重要意义。
技术实现要素:
4.为了解决现有技术存在的上述问题,本发明提供了一种基于链式搜索算法的母系mt单倍群鉴定方法、装置及设备,以实现对样本的母系mt单倍群鉴定。
5.本发明提供的技术方案如下:
6.一方面,一种基于链式搜索算法的母系mt单倍群鉴定方法,包括:
7.将目标数据库的母系单倍群数据解析为预设格式的基准母系单倍群数据;
8.获取样本芯片检测结果,将所述样本检测结果进行forward链转换,获取每个样本检测结果的基因型信息;
9.根据所述样本检测结果的基因型信息,提取每个所述样本检测结果的突变位点信息,并根据所述突变位点信息及命名规则,对所述突变位点信息进行命名并进行格式转换,获取目标格式的基因型信息;
10.根据所述目标格式的基因型信息,与所述基准母系单倍群数据进行比对,根据匹配到的基因突变信息计算每个样本所有mt单倍群的初始得分;
11.对初始得分超过预设得分阈值的单倍群,进行全局链式搜索,获取每个样本的的可信单倍群链和单倍群的最终全局得分;
12.按照最终全局得分对所有候选单倍群进行排序,得分最高且可信单倍群链最长的单倍群为鉴定结果。
13.可选的,所述目标数据库为phylotree;所述将目标数据库的母系单倍群数据解析为预设格式的基准母系单倍群数据,包括:
14.将html格式的母系单倍群数据解析成以tab键分割的txt格式文件,命名为database.txt;所述解析后的txt文件,包含两列信息,分别为单倍群名称和单倍群对应的突变位点信息,突变位点命名方式为祖先碱基
‑
位置
‑
衍生碱基。
15.可选的,根据所述样本检测结果的基因型信息,提取每个所述样本检测结果的突变位点信息,并根据所述突变位点信息及命名规则,对所述突变位点信息进行命名并进行格式转换,获取目标格式的基因型信息,包括:
16.提取每个所述样本检测结果中所有mt线粒体上位点的基因型结果,比较检测基因型与参考基因型,保留与参考等位不一致的位点,按照预设命名规则进行突变位点的命名并将过滤后的突变位点基因型转换成hsd格式文件;
17.所述hsd格式文件包含四列信息,第一列为样本名称,第二列为检测范围,第三列为单倍群信息,第四列为保留的检测位点基因型并按突变位点所在的mt位置从小到大进行排序。
18.可选的,所述根据所述目标格式的基因型信息,与所述基准母系单倍群数据进行比对,根据匹配到的基因突变信息计算每个样本信息的mt单倍群的初始得分,包括:
19.根据所述样本的突变点位信息,匹配所述database.txt中的单倍群;
20.根据匹配的结果获取匹配到的每个单倍群的初始得分。
21.可选的,所述对初始得分超过预设得分阈值的单倍群,进行全局链式搜索,包括:
22.获取初始得分大于等于0.5的单倍群;将所述初始得分大于等于0.5的单倍群,按照预设的全局链式搜索规则进行搜索。
23.可选的,所述预设全局链式搜索规则,包括:
24.若候选单倍群与被搜索单倍群名字完全一样,则跳过并搜索下一个单倍群;
25.若候选单倍群名字完全包含被搜索单倍群,则候选单倍群初始得分累加上被搜索单倍群初始得分,且,候选单倍群匹配的单倍群添加上被搜索单倍群,形成单倍群链;
26.候选单倍群h1搜索全部其它单倍群后,给出最终的单倍群链和最终得分;
27.全局链式搜索完成后,进行单倍群与单倍群链核对和检查,如果与单倍群链中最邻近单倍群之间步长相差大于2且突变位点频数大于2则该单倍群不予考虑,认为是因为位点多单倍群匹配导致的结果。
28.可选的,所述获取样本检测结果,包括:基于设计有线粒体位点探针的人全基因组snp芯片,获取样本检测结果。
29.又一方面,一种基于链式搜索算法的母系mt单倍群鉴定装置,包括:解析模块、第一获取模块、第二获取模块、计算模块和鉴定模块;
30.所述解析模块,用于将目标数据库的母系单倍群数据解析为预设格式的基准母系单倍群数据;
31.所述第一获取模块,用于获取样本芯片检测结果,将所述样本检测结果进行forward链转换,获取每个样本检测结果的基因型信息;
32.所述第二获取模块,用于根据所述样本检测结果的基因型信息,提取每个所述样本检测结果的突变位点信息,并根据所述突变位点信息及命名规则,对所述突变位点信息进行命名并进行格式转换,获取目标格式的基因型信息;
33.所述计算模块,用于根据所述目标格式的基因型信息,与所述基准母系单倍群数据进行比对,根据匹配到的基因突变信息计算每个样本所有mt单倍群的初始得分;
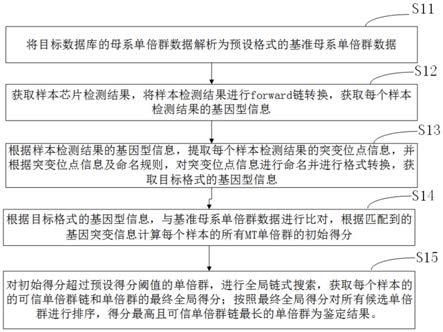
34.所述鉴定模块,用于对初始得分超过预设得分阈值的单倍群,进行全局链式搜索,获取每个样本的的可信单倍群链和单倍群的最终全局得分;按照最终全局得分对所有候选单倍群进行排序,得分最高且可信单倍群链最长的单倍群为鉴定结果。
35.可选的,所述解析模块,用于将html格式的母系单倍群数据解析成以tab键分割的txt格式文件,命名为database.txt;所述解析后的txt文件,包含两列信息,分别为单倍群名称和单倍群对应的突变位点信息,突变位点命名方式为祖先碱基
‑
位置
‑
衍生碱基。
36.又一方面,一种基于链式搜索算法的母系mt单倍群鉴定设备,包括:处理器,以及与所述处理器相连接的存储器;
37.所述存储器用于存储计算机程序,所述计算机程序至少用于执行上述任一项所述的基于链式搜索算法的母系mt单倍群鉴定方法;
38.所述处理器用于调用并执行所述存储器中的所述计算机程序。
39.本发明的有益效果为:
40.本发明实施例提供的基于链式搜索算法的母系mt单倍群鉴定方法、装置及设备,通过将目标数据库的母系单倍群数据解析为易读且易处理的txt格式;将样本asa芯片检测结果转换成forward链、计算检出率和性别;提取每个样本检测结果的突变位点信息,并根据突变位点信息及命名规则,对基因型信息进行命名并进行格式转换,获取目标格式的基因型信息;计算每个样本的所有检测到mt单倍群的初始得分;统计单个样本利用全局链式搜索法给所有候选mt单倍群的最终得分;将全局链式搜索法鉴定的单倍群与haplogrep2软件进行比较评估方法的鲁棒性。本发明能对被检样本不同illumina snp芯片数据进行母系mt单倍群鉴定,成本低、准确性高、操作方便、适用广。
附图说明
41.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
42.图1为本发明实施例提供的一种基于链式搜索算法的母系mt单倍群鉴定方法的流程示意图;
43.图2为本发明实施例提供的一种基于链式搜索算法的母系mt单倍群鉴定装置的结构示意图;
44.图3为本发明实施例提供的一种基于链式搜索算法的母系mt单倍群鉴定设备的结构示意图。
具体实施方式
45.为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
46.为了至少解决本发明中提出的技术问题,本发明实施例提供一种基于链式搜索算法的母系mt单倍群鉴定方法。其中,mt为线粒体。
47.图1为本发明实施例提供的一种基于链式搜索算法的母系mt单倍群鉴定方法流程示意图,请参阅图1,本发明实施例提供的方法,可以包括以下步骤:
48.s11、将目标数据库的母系单倍群数据解析为预设格式的基准母系单倍群数据。
49.在一些实施例中,可选的,包括:将html格式的母系单倍群数据解析成以tab键分割的txt格式文件,命名为database.txt;解析后的txt文件,包含两列信息,分别为单倍群名称和单倍群对应的突变位点信息,突变位点命名方式为祖先碱基
‑
位置
‑
衍生碱基。其中,突变位点之间以“,”分隔。
50.在一个具体的实现过程中,可先行对目标数据库进行解析构建本地数据库,如,基于phylotree(version build 17)的html格式解析成以tab键分割的txt格式文件,命名为database.txt,从而建立mtdna单倍群树状参考数据库作为本发明实施例中预设格式的基准母系单倍群数据。
51.其中,解析后的txt文件,包含两列信息,分别为单倍群名称和单倍群对应的突变位点信息,突变位点命名方式为祖先碱基
‑
位置
‑
衍生碱基,突变位点之间以“,”分隔。例如,g15043a,表示为该样本15043这个碱基位置上祖先碱基由g突变为a。
52.s12、获取样本检测结果,将样本检测结果进行forward链转换,获取每个样本检测结果的基因型信息。
53.本实施例中,可以基于设计有mt线粒体位点探针的人全基因组snp芯片,获取样本检测结果。例如,基于illumina人全基因组snp芯片,如,infinium asian screening array
‑
24v1.0芯片:illumina公司产品,货号为20016320,该芯片上设计有mt线粒体位点探针等,此处不做具体限定。
54.例如,经过asa芯片后,获取样本检测结果,进行forward链转换,计算检出率,进行性别鉴定等分析,检测的基因型作为输入文件。
55.在本实施例中,采用该芯片对32名女性被检者和25名男性被检者的dna样本进行snp位点检测,具体操作按照芯片说明书进行,本实施例以该57个样本的检测结果为例,对本发明的方案进行说明。
56.例如,首先,可以将phylotree(version build 17)解析为程序易读的txt格式。
57.将phylotree(version build 17)的html格式解析成以tab键分割的txt文件,命名为database.txt。解析后一共包含5,433个母系单倍群,其中包含某系单倍群名字为nolabel,表明这类单倍群尚未得到各官方机构的命名,表示方式为上一级单倍群名字+该单倍群突变位点信息,例如:单倍群f2+16291,即表示f2单倍群下发生16291t突变的单倍群。另外,每个单倍群突变位点中还有几种特殊的命名方式,如下:
58.碱基颠换,衍生等位用小写字母代替大写字母;例如:c5178a;
59.插入,格式:“插入位置
‑
.
‑
相对插入位置
‑
插入碱基”;例如,2156.1a表示在2156前插入了一个a碱基;
60.圆括号里的突变信息表示不确定或者反复的突变位点;
61.斜体的是初步的结果,后续根据额外的数据再来定义;
62.回复突变,格式:“祖先碱基
‑
位置
‑
复原突变”;例如,a15301g!的g复原突变回a;
63.还有一些突变位点在mtdna新版的单倍群树中删除了,比如309.1c(c),315.1c,ac indels at 515
‑
522,a16182c,a16183c,16193.1c(c)和c16519t/t16519c。
64.其次,将样本asa芯片检测结果转换成forward链、计算检出率和性别。
65.例如,在本实施例中,将57个样本asa芯片的样本检测结果根据芯片扫描后得到的原始二进制文件(idat)导入分析gencall分析软件,gencall软件版本(linux v1.0.0)和参数设置如下:
‑
t 6、
‑
g、其它参数均为默认参数;输出为gtc格式的基因型文件,每个基因型根据聚类的结果给定一个gc score值用于过滤掉低质量的基因分型结果。根据illumina公司官方推荐,gc score≤0.15代表着是失败的分型。因此,gc score值≤0.15的基因型都被定义为缺失值,根据gencall得到样本位点的缺失值,计算每个样本的位点检出率,并保留检出率≥97%的样本。最终57个样品检出率最低为98.06%,最高为99.60%。
66.s13、根据样本检测结果的基因型信息,提取每个样本检测结果的突变位点信息,并根据突变位点信息及命名规则,对突变位点信息进行命名并进行格式转换,获取目标格式的基因型信息。
67.在一些实施例中,可选的,包括:提取每个样本检测结果中所有mt线粒体上位点的基因型结果,比较检测基因型与参考基因型,保留与参考等位不一致的位点,按照phylotree(version build 17)命名规则进行突变位点的命名并将过滤后的突变位点基因型转换成hsd格式文件;hsd格式文件包含四列信息,第一列为样本名称,第二列为检测范围,第三列为单倍群信息,第四列为保留的检测位点基因型并从大到小进行排序。
68.例如,根据芯片注释文件转换forward后得到的57个样本的基因型信息,提取各个样本发生突变位点按照phylotree(version build 17)规则进行命名,并将重新命名和筛选后的结果转换成hsd格式便于后续的分析。该文件包含四列信息,第一列为样本名称,第二列为检测范围(默认为1
‑
16,569),第三列为单倍群信息,第四列为保留的检测位点基因型并按突变位点所在的mt位置从小到大进行排序。
69.s14、根据目标格式的基因型信息,与基准母系单倍群数据进行比对,根据匹配到的基因突变信息计算每个样本的所有mt单倍群的初始得分。
70.在一些实施例中,可选的,包括:根据样本的突变位点信息,匹配database.txt中的单倍群;获取匹配到的每个单倍群的初始得分。
71.例如,根据每个样本的突变位点信息来匹配database.txt中的单倍群,并给出匹配到的每个单倍群初始得分(primer score)。初始得分由两部分组成,1)该样本在此单倍群检测到位点数/此单倍群包含所有位点数,保留两位小数;2)该样本在此单倍群检测到位点的频率最小值的倒数,保留两位小数。其中,单倍群拥有的位点被检测到越多,得分越高;单倍群检测到所有位点的最小频率越低,该单倍群得分越高,低频率被检测到表明更有可能代表实际的单倍群情况。
72.在本实施例中,基于芯片检测结果和mtdna单倍群树状参考数据库给予每个检测
到单倍群初始得分的计算方法,该初始得分可作为该单倍群后续是否能作为候选单倍群的唯一指标。
73.s15、对初始得分超过预设得分阈值的单倍群,进行全局链式搜索,获取每个样本的的可信单倍群链和单倍群的最终全局得分;按照最终全局得分对所有候选单倍群进行排序,得分最高且可信单倍群链最长的单倍群为鉴定结果。
74.具体的,按照最终全局得分对所有候选单倍群进行排序,得分最高且可信单倍群链最长的单倍群则鉴定为最优的结果。
75.例如,将primer score>=0.5的单倍群在步骤(s14)得到的所有单倍群中进行全局链式搜索,算法具体规则如下:a)如果候选单倍群h1与被搜索单倍群h2名字完全一样,则跳过并搜索下一个单倍群;b)如果候选单倍群h1名字完全包含被搜索单倍群h2,则候选单倍群h1初始得分累加上h2的primer score,另外,h1匹配的单倍群添加上h2单倍群,形成单倍群链;c)候选单倍群h1搜索全部其它单倍群后,给出最终的单倍群链和最终得分;d)值得注意的是,当匹配的单倍群链越长最终得分会越高,得分最高的单倍群则为该样本最终鉴定得到的母系mt单倍群,表明该单倍群拥有足够完整的突变位点信息的支持。e)全局链式搜索完成后,进行单倍群与单倍群链核对和检查,如果与单倍群链中最邻近单倍群之间步长相差大于2且突变位点频数大于2,则该单倍群不予考虑,认为是因为位点多单倍群匹配导致的结果。
76.在本实施例中,57个样本通过全局链式搜索法得到的单倍群得分中,最低分为7.17,最高分为28.53。分数越高表明匹配到的单倍群链越多越完整,该单倍群的可信度就越高。比如a2样本通过链式搜索鉴定单倍群为b4g2,链式搜索得分为7.17分,匹配的单倍群链只有一个b4g,说明整体支持度不高;a18样本通过链式搜索鉴定单倍群为m7b1a1e1,得分为28.53,匹配的单倍群链为m,m7,m7b'c,m7b1,m7b1a,m7b1a1,m7b1a1e,可以看到a18样本形成完整的单倍群链,故最终得分高,单倍群为m7b1a1e1可信度也非常高。其它55个样本的得分都介于7.17
‑
28.53之间。
77.在本实施例中,结果输出为包含三列的txt格式文件。第一列为鉴定得到的母系mt单倍群,第二列为通过全局链式搜索得到的单倍群链,第三列为该单倍群的最终得分。
78.为了进一步说明,全局链式搜索法鉴定的单倍群的鲁棒性,本实施例中,可以将57个样本全局链式搜索法鉴定的单倍群与haplogrep2软件进行比较。
79.表1为全局链式搜索法鉴定单倍群与haplogrep2鉴定结果统计表,参阅表1,通过全局链式搜索法预测的样本单倍群与haplogrep2鉴定结果相比,53个样本鉴定的结果一致,4个样本鉴定结果不一致。四个不一致的样品分别为a1,a2,a8,a45,其中a1,a8,a45样品通过链式搜索可以看到能形成比较完整的单倍群链,因此可信度也较高。a2样品只有一个匹配单倍群,haplogrep2打分为0.67得分较低,因此该样本单倍群结果来看,整体可信度都不太高两者皆可。
80.本发明的有益效果是:本发明在不增加任何实验成本的情况下,全局链式搜索mt单倍群法能对被检样本illumina snp芯片(芯片上设计有mt线粒体的探针)数据进行母系单倍群的快速而准确地鉴定,其优势如下:
81.(1)成本低:本方法判断样本的性别无需进行任何额外的实验。
82.(2)准确性高:采用针对asa芯片的全局搜索算法和打分机制,以单倍群链结合累
加初始得分的形式给候选mt单倍群进行可靠性排序,综合考虑影响mt单倍群的各项因素,得到的结果可信可靠。与已发表的高引用软件相比,更加适用于illumina人全基因组snp芯片的mt单倍群鉴定分析。
83.表1全局链式搜索法鉴定单倍群与haplogrep2鉴定结果统计表
84.样本编号链式搜索法鉴定单倍群匹配的单倍群链链式单倍群得分haplogrep2鉴定单倍群haplogrep2得分a1m12a1m,m12a,m1213.49m50.7578a2b4g2b4g7.17hv0.6705a3m33cm,m3312.33m33c0.8299a4d4hm80'd,d4,d12.18d4h0.8657a5r11'b6n6.95r11'b60.6761a6r9b1a2ar9b,r9b1a2,n,r9,r9b120.8r9b1a2a0.7899a7r11b1r11b,r11'b6,n,r1113.56r11b10.7422a8a2wn,a14.06a+152+16362+2000.7967a9d4m80'd,d11.03d40.8754a10f1a4af1a4,f1,f,r9,f1a'c'f,f1a17.31f1a4a0.7631a11c7ac7,c,m814.61c7a0.857a12b5ab58.7b5a0.6308a13g2a1g2a'c,g,g2a,g212.23g2a10.7947a14m8a2'3m,m8a,m816.24m8a2'30.8908a15d4e5bd4e5,m80'd,d4,d18.26d4e5b0.8868a16d4g2a1m80'd,d4,d4g2,d,d4g2a14.65d4g2a10.8336a17a5b1n,a,a5b,a519.35a5b10.8167a18m7b1a1e1m7,m7b1a1e,m,m7b'c,m7b1,m7b1a,m7b1a128.53m7b1a1e10.8161a19a25a9.83a250.8438a20d5a2d5a'b,m80'd,d5,d5a,d17.37d5a20.8743a21d4b2dd4b,m80'd,d4,d,d4b214.96d4b20.8548a22d5a2d5a'b,m80'd,d5,d5a,d18.87d5a20.8249a23r9b1a2br9b,r,r9b1a2,r9,r9b1,r9b1a19.11r9b1a2b0.8404a24d4jm80'd,d49.67d4j0.8595a25b4a3b4,b4a12.03b4a30.7474a26d4b2b2bd4b2b,d4b,m80'd,d4,d4b2b2,d,d4b220.55d4b2b2b0.8563a27g1ag1,g10.2g1a0.8408a28r9b1a3r,r9,r9b113.79r9b1a30.759a29n9a10n9a,n12.77n9a100.8419a30d5a2d5a'b,m80'd,d5,d5a,d17.37d5a20.8743a31z3z,m8,m15.37z30.7906a32b5a2a1ab5a2a,b5a2a1,b5,b5a,b5a220.53b5a2a1a0.7202a33f1a1f1,f,f1a'c'f,f1a12.46f1a10.7427a34b5bb514.77b5b0.7652a35f1a1f1,f,f1a'c'f,f1a12.46f1a10.7427a36d4b2bd4b,m80'd,d4,d,d4b215.76d4b2b0.8731a37cm8,m13.53c0.83a38f1a1f1,f,f1a'c'f,f1a12.46f1a10.7512a39r9c1ar9c,r,r915.17r9c1a0.7641a40z4az,z410.1z4a0.8343a41a5b1ba5b,a,a5,a5b112.99a5b1b0.7296a42n9a3n9a,n15.03n9a30.7952a43a15a11.62a150.8182a44m12a1a1m,m12a1a,m12,m12a,m12a123.41m12a1a10.8028a45n9a2dn,n9a7.51hv0.6398a46d4jm80'd,d4,d11.18d4j0.8887a47a5b1ba,a5b1,a5b,a516.63a5b1b0.8083a48g2a5g2a'c,g,g2a,g213.48g2a50.7658a49b4b1ab4b'd'e'j,b4b,b4,b4b115.59b4b1a0.723a50n9a10n9a,n12.77n9a100.8419
a51m8a3am8a3,m,m8a2'3,m8a,m821.44m8a3a0.8559a52b4b1b4b'd'e'j,b4b,b412.39b4b10.7213a53n9a1n9a,n13.44n9a10.8144a54n9a3n9a,n15.03n9a30.8376a55m8a2'3m,m8a,m816.24m8a2'30.8956a56f2+16291f,f210.21f2+162910.7473a57b4c1b2cb4c1a'b,b4c1b2,b4c1,b4,b4c1b,b4c17.76b4c1b2c0.7151
85.(3)操作方便:操作者仅需统计好被检测者mt线粒体上突变位点的数量即可判断被检样本的母系mt单倍群,操作快速、简单、方便。
86.(4)适用范围广:本方法适用于所有设计有mt线粒体位点探针的illumina snp芯片。
87.本发明实施例提供的基于链式搜索算法的母系mt单倍群鉴定方法,将phylotree(version build 17)的html格式文件解析为易读且易处理的txt格式;将样本asa芯片检测结果转换成forward链、计算检出率和性别;提取mt线粒体检测得到的突变位点,命名转换和文件格式转换;计算每个样本的所有检测到mt单倍群的初始得分;统计单个样本利用全局链式搜索法给所有候选mt单倍群的最终得分;将全局链式搜索法鉴定的单倍群与haplogrep2软件进行比较评估方法的鲁棒性。本发明能对被检样本不同illumina snp芯片数据进行母系mt单倍群鉴定,成本低、准确性高、操作方便、适用广。
88.基于一个总的发明构思,本发明实施例还提供一种基于链式搜索算法的母系mt单倍群鉴定装置。
89.图2为本发明实施例提供的一种基于链式搜索算法的母系mt单倍群鉴定装置的结构示意图,请参阅图2,本发明实施例提供的装置,可以包括以下结构:解析模块21、第一获取模块22、第二获取模块23、计算模块24和鉴定模块25;
90.解析模块21,用于将目标数据库的母系单倍群数据解析为预设格式的基准母系单倍群数据;
91.第一获取模块22,用于获取样本检测结果,将样本检测结果进行forward链转换,获取每个样本检测结果的基因型信息;
92.第二获取模块23,用于根据所述样本基因型检测结果,提取其突变位点信息,并根据所述突变位点信息及命名规则,对所述突变位点信息进行命名并进行格式转换,获取目标格式的基因型信息;
93.计算模块24,用于根据目标格式的基因型信息,与基准母系单倍群数据进行比对,根据匹配到的基因突变信息计算每个样本的所有mt单倍群的初始得分;
94.鉴定模块25,用于对初始得分超过预设得分阈值的单倍群,进行全局链式搜索,获取每个样本的的可信单倍群链和单倍群的最终全局得分;按照最终全局得分对所有候选单倍群进行排序,得分最高且可信单倍群链最长的单倍群为鉴定结果。
95.可选的,解析模块21,用于将html格式的母系单倍群数据解析成以tab键分割的txt文件,命名为database.txt;解析后的txt文件,包含两列信息,分别为单倍群名称和单倍群对应的突变位点信息,突变位点命名方式为祖先碱基
‑
位置
‑
衍生碱基,突变位点之间以“,”分隔。
96.关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
97.本发明实施例提供的基于链式搜索算法的母系mt单倍群鉴定装置,将phylotree(version build 17)(mtdna tree build 17)的html格式文件解析为易读且易处理的txt格式;将样本asa芯片检测结果转换成forward链、计算检出率和性别;提取mt线粒体检测得到的突变位点,命名转换和文件格式转换;计算每个样本的所有检测到mt单倍群的初始得分;统计单个样本利用全局链式搜索法给所有候选mt单倍群的最终得分;将全局链式搜索法鉴定的单倍群与haplogrep2软件进行比较评估方法的鲁棒性。本发明能对被检样本不同illumina snp芯片数据进行母系mt单倍群鉴定,成本低、准确性高、操作方便、适用广。
98.基于一个总的发明构思,本发明实施例还提供一种基于链式搜索算法的母系mt单倍群鉴定设备。
99.图3为本发明实施例提供的一种基于链式搜索算法的母系mt单倍群鉴定设备结构示意图,请参阅图3,本发明实施例提供的一种基于链式搜索算法的母系mt单倍群鉴定设备,包括:处理器31,以及与处理器相连接的存储器32。
100.存储器32用于存储计算机程序,计算机程序至少用于上述任一实施例记载的基于链式搜索算法的母系mt单倍群鉴定方法;
101.处理器31用于调用并执行存储器中的计算机程序。
102.以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
103.可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
104.需要说明的是,在本发明的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是指至少两个。
105.流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本发明的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本发明的实施例所属技术领域的技术人员所理解。
106.应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
107.本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
108.此外,在本发明各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模
块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
109.上述提到的存储介质可以是只读存储器,磁盘或光盘等。
110.在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
111.尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1