一种用于厌氧膜生物反应器膜污染关键影响因子识别方法
本发明涉及污水处理领域,尤其是涉及一种厌氧膜生物反应器膜污染预测与关键影响因子识别方法。
背景技术:
1、厌氧膜生物反应器(anaerobic membrane bioreactor,anmbr)主要应用在市政污水、工业废水和畜禽废水等水处理过程中。anmbr因其具有占地面积小、出水水质高、能耗强度低以及能源回收率高等优点而备受关注,在污水处理领域更具发展前景。然而,膜污染是anmbr操作运行过程中不可避免的问题与挑战,制约了anmbr技术的进一步推广与应用。
2、厌氧膜生物反应器膜污染形成的原因主要包括浓差极化、膜孔堵塞以及表面沉积等。膜污染过程十分复杂,受生物质特性、膜组件特征以及操作参数等多种变量影响,具有非线性影响因素复杂、变量间耦合作用强等特征。在过去几十年里,研究人员相继构建了解析生物质特性以及操作参数等与膜污染间关系的经典数学模型。然而,传统数学模型适用情况较为单一,因此通用性较差;而且数学模型在模拟过程中,通常需要诸多先验假设,难以解析复杂因素间的非线性关系,存在数值条件要求高、模拟效果不佳等问题。
3、人工智能算法的发展使膜污染预测成为可能,随机森林是一种组合分类器技术,由多颗决策树组合而成,相较于决策树等单分类器,具有更好的预测性能,对高维度数据处理效果更好可有效从大量非线性数据中挖掘其隐藏的规律,并做出分类或回归预测,在膜污染预测与关键影响因子识别等复杂非线性问题方面具有一定的潜力。
技术实现思路
1、针对现有技术存在的上述问题,本发明提供了一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,将厌氧膜生物反应器运行过程中的膜污染相关数据集输入至模型中,便可完成膜污染预测与膜污染关键影响因子的识别分析,本发明能够指导厌氧膜生物反应器对膜污染进行针对性控制。
2、本发明的技术方案如下:
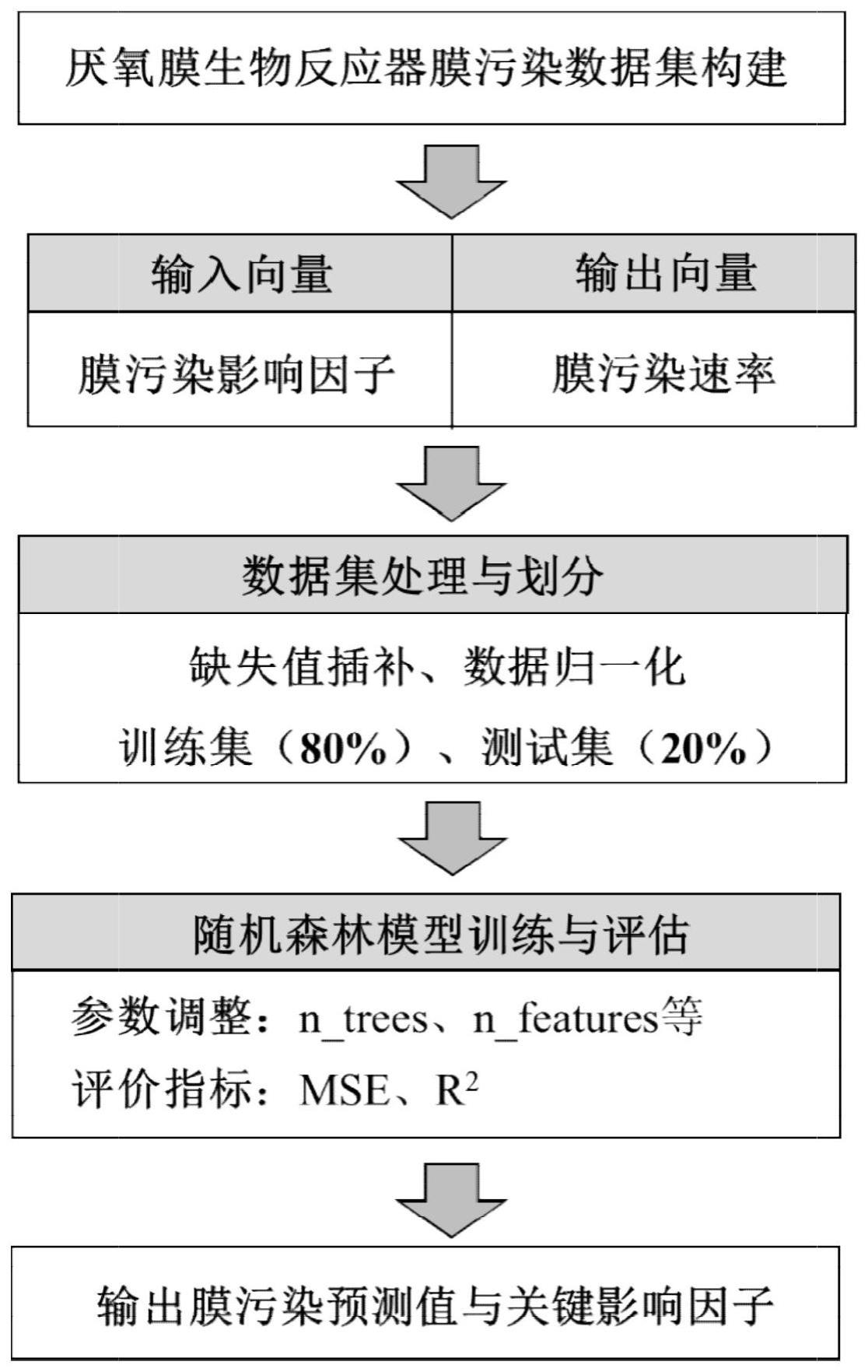
3、一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,包括以下步骤:
4、s1、收集与筛选原始数据;所述原始数据包括但不限于:厌氧膜生物反应器的操作参数、生物质特性、膜组件特征、膜污染速率;
5、s2、将厌氧膜生物反应器运行操作过程中的膜污染速率作为输出向量,膜组件特征、操作参数以及生物质特性作为输入向量,构建形成数据集;
6、s3、构建基于决策树的随机森林模型;
7、s4、根据最优随机森林模型的输入特征进行目标特征输出,获得膜污染预测值;
8、s5、基于最优随机森林模型输出的每个输入向量的相对重要性数值,对各个膜污染影响因子重要性指标进行排序,按照特征重要性顺序识别膜污染关键影响因子。
9、进一步的,步骤s1的原始数据包括14种特征参数:膜孔径、膜有效面积、膜通量、有机负荷、生物气回曝速率、水力停留时间、挥发性固体浓度、可溶性微生物产物蛋白质浓度、可溶性微生物产物多糖浓度、可溶性微生物产物蛋白质与多糖比率、胞外聚合物蛋白质浓度、胞外聚合物多糖浓度、胞外聚合物蛋白质与多糖比率、进水cod浓度;
10、将上述14种特征参数设置为模型输入向量。
11、进一步的,步骤s3包括以下步骤:
12、s3-1、将数据集划分为测试集与预测集,并输入至randomforestregressor模型;
13、s3-2、对randomforestregressor模型进行超参数优化以及数据集训练,超参数包括但不限于:树数、特征数、每颗决策树最大深度、内部节点再划分所需的最小样本数、叶节点最小样本数;分别建立测试集与预测集的输入矩阵与输出矩阵,采用网格搜索方法或手动调整参数结合的方法确定最优参数,完成randomforestregressor模型的构建;
14、s3-3、利用测试集数据对模型进行精度检验,使用均方差mse和拟合优度r2评估模型精度,计算公式如下:
15、
16、
17、其中,n为样本个数,为第i个样本膜污染预测值,yi为i个样本膜污染实际值,实际样本平均值。
18、进一步的,步骤s3-1中,数据集按80%以及20%比例随机划分为测试集与预测集。
19、进一步的,步骤s3-1划分数据集时,如果数据集存在部分缺失值,就先对缺失值进行插值处理,再对数据集进行归一化处理。
20、进一步的,采用回归插补法、热卡填充法、中值替换法、随机森林插补法中的任一种方法对数据集的缺失值进行插值。
21、进一步的,树数的取值范围是200~1300,步长为100;
22、特征数的取值范围是1~14,步长为1;
23、每颗决策树最大深度的取值为none;
24、内部节点再划分所需的最小样本数的取值为2;
25、叶节点最小样本数的取值为1。
26、进一步的,步骤s3-3使用均方差mse和拟合优度r2评估模型精度的方法如下:
27、如果r2≥0.85并且mse≤0.2,就认为该模型合理有效,否则重新调整该模型的超参数取值,并重复执行步骤s3-2。
28、进一步的,步骤s3所述随机森林模型训练过程是以python编程语言为载体,并且基于matplotlib、numpy、sklearn、pandas模块搭建。
29、进一步的,步骤s5通过平均杂质减少法计算每个输入向量的特征重要性。
30、本发明有益的技术效果在于:
31、(1)克服了传统数学模型膜污染预测过程中假设条件多、模拟效果不佳和通用性差等问题,提供厌氧膜生物反应器膜污染预测与分析的新型方法;
32、(2)从算法应用方面提出了厌氧膜生物反应器膜污染预测与膜污染关键影响因子的识别方法,丰富了厌氧膜生物反应器膜污染解析与控制理论;
33、(3)引入随机森林算法建模,实现了膜污染关键影响因子的分类分析,直观的显示了各类因素对膜污染的影响程度。
技术特征:
1.一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,其特征在于:
3.根据权利要求1所述的一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,其特征在于,步骤s3包括以下步骤:
4.根据权利要求3所述的一种基于随机森林算法的厌氧膜生物反应器膜污染预测与关键影响因子识别方法,其特征在于:
5.根据权利要求3所述的一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,其特征在于:
6.根据权利要求5所述的一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,其特征在于,采用回归插补法、热卡填充法、中值替换法、随机森林插补法中的任一种方法对数据集的缺失值进行插值。
7.根据权利要求3所述的一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,其特征在于:
8.根据权利要求3所述的一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,其特征在于,步骤s3-3使用均方差mse和拟合优度r2评估模型精度的方法如下:
9.根据权利要求1所述的一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,其特征在于,步骤s3所述随机森林模型训练过程是以python编程语言为载体,并且基于matplotlib、numpy、sklearn、pandas模块搭建。
10.根据权利要求1所述的一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,其特征在于,步骤s5通过平均杂质减少法计算每个输入向量的特征重要性。
技术总结
本发明公开了一种用于厌氧膜生物反应器膜污染关键影响因子识别方法,包括以下步骤:收集与筛选原始数据;构建数据集;构建基于决策树的随机森林模型;输出预测结果;识别关键影响因子。本发明相较于传统数学模型具有数据选取灵活、无需先验假设等特点,可以较为精准的预测厌氧膜生物反应器膜污染进程并识别诸多膜污染影响因素中的关键影响因子,弥补传统数学模型模拟效果有限、通用性较差的缺点,为膜污染机理解析研究提供参考,也为厌氧膜生物反应器膜污染控制提供相关理论依据。
技术研发人员:王志伟,牛承鑫,史威,戴若彬,李雪松
受保护的技术使用者:同济大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!