一种基于机器学习的非晶形成能力预测方法
本发明属于非晶形成能力预测,尤其涉及一种基于机器学习的非晶形成能力预测方法。
背景技术:
1、非晶合金具有塑性好、耐腐蚀、坚固等特点,广泛应用于生物医学、军工航天、高新技术等领域。目前非晶合金应用的最主要瓶颈是其形成能力非常有限,提高非晶形成能力是非晶制备中需要解决的首要问题。所以解决合金中的非晶形成能力问题,不仅可以促进非晶合金本身的应用,而且也能推动凝聚态物理学的发展
2、非晶形成能力用来表征合金形成非晶的难易程度,可以通过临界冷却速率或临界铸造直径来评估。尽管临界冷却速率是一个更加合适的参数,但很难通过实验和热分析计算获得,所以大量学者通过提出一些标准来预测金属玻璃的临界铸造直径以表征其非晶形成能力。这些标准诸如γ参数、玻璃转变温度trg、过冷液相区δtx等。但是这些标准只针对特定的合金成分且预测准确度不高。
技术实现思路
0、
技术实现要素:
1、本发明要解决的技术问题:提供一种基于机器学习的非晶形成能力预测方法,以解决现有技术表征非晶合金的非晶形成能力存在的只针对特定的合金成分且预测准确度不高等技术问题。
2、本发明技术方案:
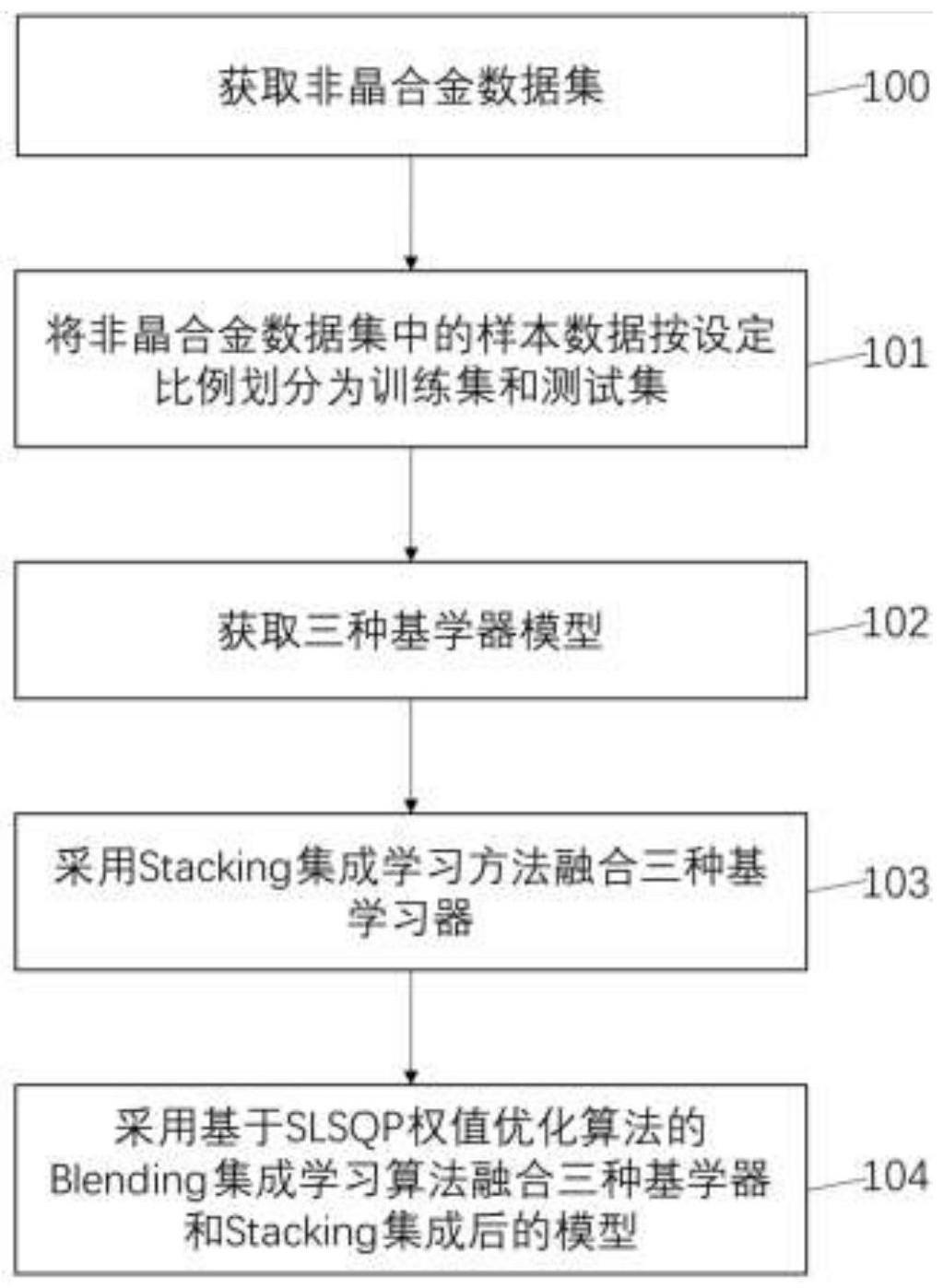
3、一种基于机器学习的非晶形成能力预测方法,所述方法包括:
4、步骤1、获取非晶特征数据集及预处理,数据集的数据包括玻璃化转变温度tg、结晶转变温度tx、熔化结束温度tl和临界铸造直径dmax;
5、步骤2、非晶特征数据集中的样本数据按设定比例划分为训练集和测试集;
6、步骤3、获取机器学习模型,所述机器学习模型包括knn、lightgbm和randomforest三种机器学习模型;
7、步骤4、采用stacking集成学习算法融合所获取的三种基机器学习模型,得到stacking集成后的机器学习模型;
8、步骤5、将knn模型、lightgbm模型、randomforest模型和stacking融合后的模型使用slsqp算法加权平均得到预测非晶形成能力的机器学习模型。
9、预处理的方法为:将各属性每条数据减去该属性集中最小值除以该属性集中最大值和最小值的差,使得每种属性取值范围在0-1之间。
10、按设定比例划分为训练集和测试集的划分方法为:非晶合金数据集中的样本数据按7:3的比例划分为训练集和测试集。
11、步骤4所述采用stacking集成学习算法融合所获取的三种基机器学习模型,得到stacking集成后的机器学习模型的方法包括:
12、采用stacking集成学习框架融合拟合后的三种机器学习模型;
13、stacking集成学习是将基学习器的预测结果整合起来作为元学习器的训练数据,以此来提高模型的泛化能力,stacking将第一级模型预测结果用作第二级的输入;在第一级的模型训练中,使用5折交叉验证的方式训练基模型;以randomforest作为元学习器,利用第一层的预测结果矩阵来训练一个随机森林模型,将9维的数据映射到3维;最后利用训练好的随机森林模型对数据集tp进行预测,该结果即为stacking方法在测试集上最终的预测结果。
14、得到预测非晶形成能力的机器学习模型的方法为:对四种学习器采用slsqp算法加权求和,slsqp算法具体过程为:
15、
16、
17、0<wi<1#(3)
18、式中:为预测值,yi为真实测量值,wi为各模型的权值,z为测量值和预测值差的平方和。
19、所述方法还包括:
20、步骤5、模型评估和测试,所述模型评估的方法为:通过计算模型的皮尔逊相关系数r、均方根误差mse、平均绝对误差mae进行衡量,由于预测值和测量值不存在负相关所以r取值在[0,1]之间,越靠近1表明模型性能越好,mse和mae取值也在[0,1]之间,越靠近0表明模型性能越好;计算公式为:
21、
22、
23、
24、模型测试的方法为:将训练后得到的三种基学习器以及stacking集成后的模型分别对测试集进行预测,四种模型预测的结果与对应的权值相乘再求和,得到模型在测试集上的结果。
25、本发明有益效果是:
26、本发明在stacking的第一层选取了不同类型的强机器学习模型,相比于传统集成学习,强异构模型的结合有利于增强模型的泛化能力。
27、stacking第一层采用了交叉验证的方法,第二层的训练数据来自第一层的测试预测数据而不是训练预测数据,使得模型更加贴近测试集上的表现从而增强了模型的泛化能力。
28、stacking训练数据的获取相当于特征提取的过程,算法的自动特征提取能力相比于人为的特征提取有更好的稳定性。
29、stacking元学习器和基学习器间相互调和,从而使得模型整体达到中和状态。
30、采用基于slsqp权值优化算法的blending集成学习建模,提高了模型的性能与泛化能力。
31、本发明计算速度快,预测精度高、成本低、周期短;本发明所建数据集覆盖元素范围广,模型在数据集上表现优异,说明本发明具有普适性,对于各类非晶合金均适用。
32、解决了现有技术表征非晶合金的非晶形成能力存在的只针对特定的合金成分且预测准确度不高等技术问题。
技术特征:
1.一种基于机器学习的非晶形成能力预测方法,其特征在于:所述方法包括:
2.根据权利要求1所述的一种基于机器学习的非晶形成能力预测方法,其特征在于:预处理的方法为:将各属性每条数据减去该属性集中最小值除以该属性集中最大值和最小值的差,使得每种属性取值范围在0-1之间。
3.根据权利要求1所述的一种基于机器学习的非晶形成能力预测方法,其特征在于:按设定比例划分为训练集和测试集的划分方法为:非晶合金数据集中的样本数据按7:3的比例划分为训练集和测试集。
4.根据权利要求1所述的一种基于机器学习的非晶形成能力预测方法,其特征在于:步骤4所述采用stacking集成学习算法融合所获取的三种基机器学习模型,得到stacking集成后的机器学习模型的方法包括:
5.根据权利要求1所述的一种基于机器学习的非晶形成能力预测方法,其特征在于:得到预测非晶形成能力的机器学习模型的方法为:对四种学习器采用slsqp算法加权求和,slsqp算法具体过程为:
6.根据权利要求1所述的一种基于机器学习的非晶形成能力预测方法,其特征在于:所述方法还包括:
技术总结
本发明公开一种基于机器学习的非晶形成能力预测方法,包括:获取非晶特征数据集及预处理,将非晶特征数据集中的样本数据按设定比例划分为训练集和测试集;获取机器学习模型,所述机器学习模型包括KNN、LightGBM和RandomForest三种机器学习模型;采用Stacking集成学习算法融合所获取的三种基机器学习模型,得到Stacking集成后的机器学习模型;将KNN模型、LightGBM模型、RandomForest模型和Stacking融合后的模型使用SLSQP算法加权平均得到预测非晶形成能力的机器学习模型;解决了表征非晶合金的非晶形成能力存在的只针对特定的合金成分且预测准确度不高等技术问题。
技术研发人员:梁永超,孙波,陈贵平,王梦琦,谢继兴
受保护的技术使用者:贵州大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!