多语言预测模型的训练及阿尔茨海默病预测的方法、装置与流程
本申请涉及人工智能,尤其涉及一种多语言预测模型的训练及阿尔茨海默病预测的方法、装置。
背景技术:
1、随着当前社会老龄化程度的不断加深,人口老龄化也将伴随诸多健康问题,其中失能和失智等认知障碍疾病将对社会现行健康体系带来严峻挑战。
2、医学研究表明,语音和语言的某些特征变化是阿尔茨海默病或其他神经退行性疾病的信号,比其他严重的症状出现得更早。早期阿尔茨海默症的精准预测对于预防阿尔茨海默症病情的恶化具有重大意义。
3、现有技术通常是通过评估员和受试者进行一对一的认知评估,这种评估方式往往带有主观性,评估结果不精准,而且效率低。现有技术中还公开了通过人工智能技术来预测阿尔茨海默症,但是现有技术中都是从人物的表情、运动数据等层面单一的评估,导致评估结果也不准确。另外,对于不同语言的人群,受限于语种的差异,目前无法实现使用单一模型对不同语种的人群进行疾病的预测。
技术实现思路
1、为了解决现有技术中对阿尔茨海默症的评估不准确以及只能对单一特定语种的人群进行疾病预测的技术问题。本申请提供了一种多语言预测模型的训练及阿尔茨海默病预测的方法、装置,其主要目的在于通过多种特征综合预测阿尔茨海默症,提高阿尔茨海默症的预测准确度,以及实现多语种的疾病预测。
2、为实现上述目的,本申请提供了一种多语言阿尔茨海默症预测模型的训练方法,该方法包括:
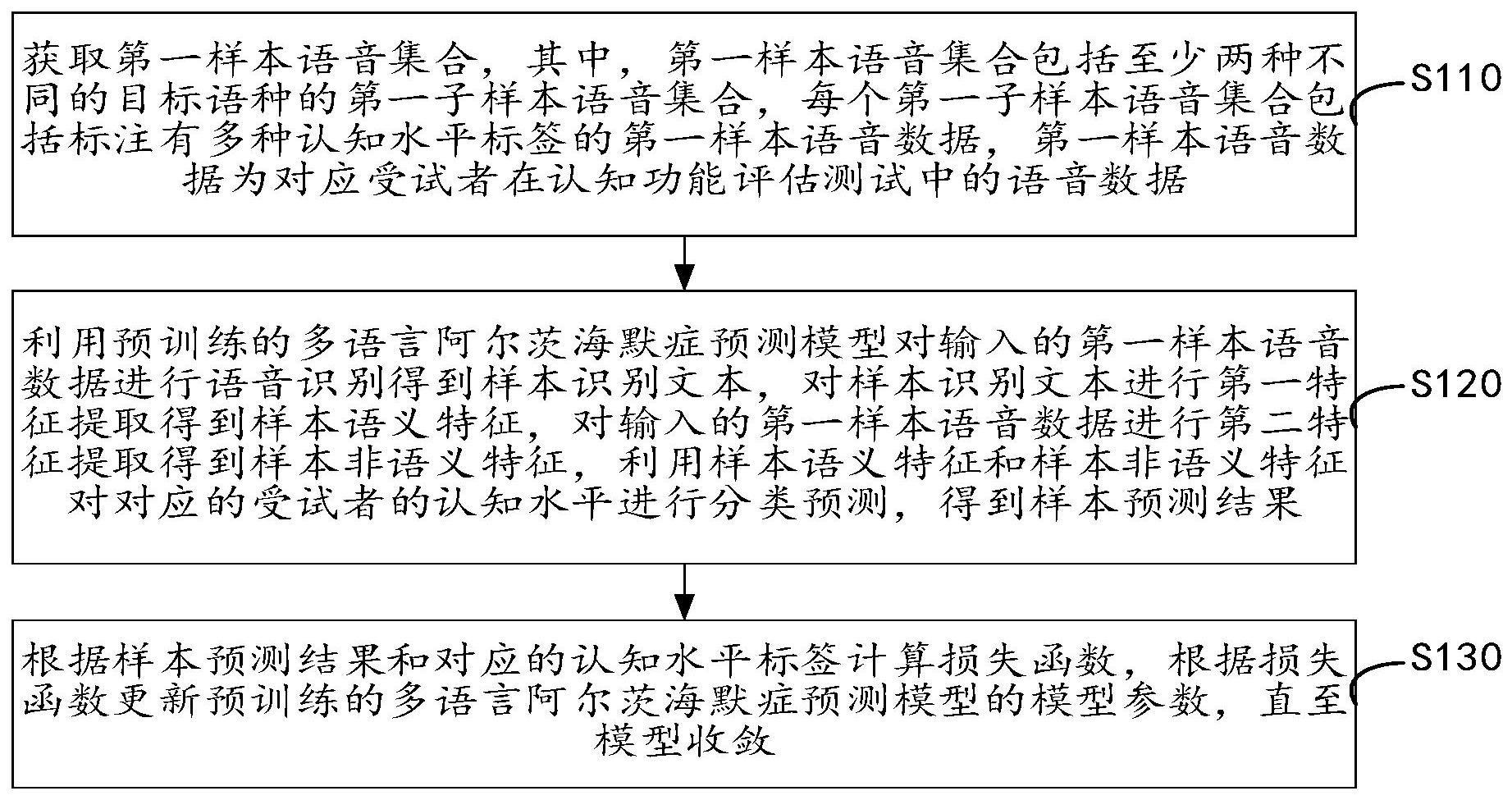
3、获取第一样本语音集合,其中,第一样本语音集合包括至少两种不同的目标语种的第一子样本语音集合,每个第一子样本语音集合包括标注有多种认知水平标签的第一样本语音数据,第一样本语音数据为对应受试者在认知功能评估测试中的语音数据;
4、利用预训练的多语言阿尔茨海默症预测模型对输入的第一样本语音数据进行语音识别得到样本识别文本,对样本识别文本进行第一特征提取得到样本语义特征,对输入的第一样本语音数据进行第二特征提取得到样本非语义特征,利用样本语义特征和样本非语义特征对对应的受试者的认知水平进行分类预测,得到样本预测结果;
5、根据样本预测结果和对应的认知水平标签计算损失函数,根据损失函数更新预训练的多语言阿尔茨海默症预测模型的模型参数,直至模型收敛。
6、此外,为实现上述目的,本申请还提供了一种阿尔茨海默症的预测方法,该方法包括:
7、获取待评估对象在认知功能评估测试中的目标语音数据;
8、利用已训练的多语言阿尔茨海默症预测模型提取目标语音数据的目标语义特征和目标非语义特征,根据目标语义特征和目标非语义特征对待评估对象的认知水平进行分类预测,得到目标预测结果,其中,已训练的多语言阿尔茨海默症预测模型是根据前面任一项的多语言阿尔茨海默症预测模型的训练方法得到的。
9、此外,为实现上述目的,本申请还提供了一种多语言阿尔茨海默症预测模型的训练装置,该装置包括:
10、第一数据获取模块,用于获取第一样本语音集合,其中,第一样本语音集合包括至少两种不同的目标语种的第一子样本语音集合,每个第一子样本语音集合包括标注有多种认知水平标签的第一样本语音数据,第一样本语音数据为对应受试者在认知功能评估测试中的语音数据;
11、训练预测模块,用于利用预训练的多语言阿尔茨海默症预测模型对输入的第一样本语音数据进行语音识别得到样本识别文本,对样本识别文本进行第一特征提取得到样本语义特征,对输入的第一样本语音数据进行第二特征提取得到样本非语义特征,利用样本语义特征和样本非语义特征对对应的受试者的认知水平进行分类预测,得到样本预测结果;
12、参数更新模块,用于根据样本预测结果和对应的认知水平标签计算损失函数,根据损失函数更新预训练的多语言阿尔茨海默症预测模型的模型参数,直至模型收敛。
13、为实现上述目的,本申请还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机可读指令,处理器执行计算机可读指令时执行如前面任一项的多语言阿尔茨海默症预测模型的训练方法的步骤,或,处理器执行计算机可读指令时执行如前面任一项的阿尔茨海默症的预测方法的步骤。
14、为实现上述目的,本申请还提供了一种计算机可读存储介质,计算机可读存储介质上存储有计算机可读指令,计算机可读指令被处理器执行时,使得处理器执行如前面任一项的多语言阿尔茨海默症预测模型的训练方法的步骤,或,使得处理器执行如前面任一项的阿尔茨海默症的预测方法的步骤。
15、本申请提出的多语言预测模型的训练及阿尔茨海默病预测的方法、装置,通过根据阿尔茨海默症患者与正常人在理解能力和语言表达上的较大差异,通过神经网络模型学习不同语种的正常人群和阿尔茨海默症患者的语音数据中语义特征分布规律和非语义特征分布规律,且由于非语义特征与语种无关,因此能够对共享的跨语言的非语义特征进行学习,实现了对语音数据的全面分析,使得训练出来的多语言阿尔茨海默症预测模型能够综合进行阿尔茨海默症的预测,克服了现有技术只能从单一特征进行疾病预测的缺陷,提高了阿尔茨海默症的预测准确度和可靠性,且实现了多语种的疾病预测。
技术特征:
1.一种多语言阿尔茨海默症预测模型的训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述预训练的多语言阿尔茨海默症预测模型包括多语言文本预训练网络、多语言语音预训练网络和决策网络;
3.根据权利要求2所述的方法,其特征在于,所述根据所述损失函数更新所述预训练的多语言阿尔茨海默症预测模型的模型参数,包括:
4.根据权利要求2所述的方法,其特征在于,在所述预训练的多语言阿尔茨海默症预测模型构建之前,所述多语言语音预训练网络预先使用无标签且不同目标语种的第二样本语音数据训练过,其中,不同的第二样本语音数据中包括与阿尔茨海默症无关的常见语音数据;
5.根据权利要求2或4所述的方法,其特征在于,在所述预训练的多语言阿尔茨海默症预测模型构建之前,所述多语言语音预训练网络预先使用第二样本语音集合训练过,其中,所述第二样本语音集合包括不同目标语种的第二子样本语音集合,每个所述第二子样本语音集合包括对应语种的第二样本语音数据,所述第二样本语音数据使用相同语种且内容一致的文本标签标注,不同的第二样本语音数据中包括与阿尔茨海默症无关的常见语音数据;
6.一种阿尔茨海默症的预测方法,其特征在于,所述方法包括:
7.根据权利要求6所述的方法,其特征在于,所述利用已训练的多语言阿尔茨海默症预测模型提取所述目标语音数据的目标语义特征和目标非语义特征,根据所述目标语义特征和目标非语义特征对所述待评估对象的认知水平进行分类预测,得到目标预测结果,包括:
8.一种多语言阿尔茨海默症预测模型的训练装置,其特征在于,所述装置包括:
9.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机可读指令,其特征在于,所述处理器执行所述计算机可读指令时执行如权利要求1-5任一项所述的多语言阿尔茨海默症预测模型的训练方法的步骤,或,所述处理器执行所述计算机可读指令时执行如权利要求6-7任一项所述的阿尔茨海默症的预测方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机可读指令,其特征在于,所述计算机可读指令被处理器执行时,使得所述处理器执行如权利要求1-5任一项所述的多语言阿尔茨海默症预测模型的训练方法的步骤,或,使得所述处理器执行如权利要求6-7任一项所述的阿尔茨海默症的预测方法的步骤。
技术总结
本申请涉及人工智能技术,提出一种多语言预测模型的训练及阿尔茨海默病预测的方法、装置,该方法包括:获取第一样本语音集合,利用预训练的多语言阿尔茨海默症预测模型对样本语音数据进行语音识别得到样本识别文本,对样本识别文本进行第一特征提取得到样本语义特征,对第一样本语音数据进行第二特征提取得到样本非语义特征,利用样本语义特征和样本非语义特征对受试者的认知水平进行分类预测,得到样本预测结果;根据样本预测结果和认知水平标签计算的损失函数更新预训练的多语言阿尔茨海默症预测模型的模型参数直至模型收敛。本申请提高了阿尔茨海默症的预测和诊断的准确度和可靠性,且实现了多语种的疾病预测,广泛应用于数字医疗领域。
技术研发人员:陈闽川,马骏,王少军
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!