一种音视结合的发音质量评估方法及系统
本发明属于计算机视觉、语音分析领域,具体涉及一种结合唇语分析、面部动作分析与音频语音分析的发音质量评估与矫正方法与系统。
背景技术:
1、发音质量评估是指针对发音、声调、声音、节奏等口语表达不正确或者交流方面有障碍的人群的发音质量进行评测,从而达到辅助其实现准确发音的效果。听力障碍、自闭症患者、孤独症患者等群体因为种种原因往往无法与他人进行正常的语言交流,甚至由于长时间不使用自身语言功能而渐渐失去说话的能力。但是他们的语言系统相关器官通常并未发生病变,只是缺乏练习和正确的反馈而无法正常使用语言功能。本文的发音质量评估方法正是希望能为以上人群提供发音质量的评测与反馈,辅助其进行发音练习。此外,本发明也适用于咿呀学语的小孩和希望进行发音矫正的人群。
2、目前的发音质量评估方式常常只利用了音频模态信息,而忽视了发音过程中同样十分重要的视觉模态。常见的发音质量评估方法往往衡量发音音频与标准音频之间的距离,以此判断发音标准与否,然而这种的评估方法无法明确给出导致发音不标准的原因,不能为使用者提供行之有效的发音矫正建议。对此本发明将结合音视双模态对发音进行全方面的质量评估,并根据评估结果给出行之有效且浅显易懂的发音矫正建议。
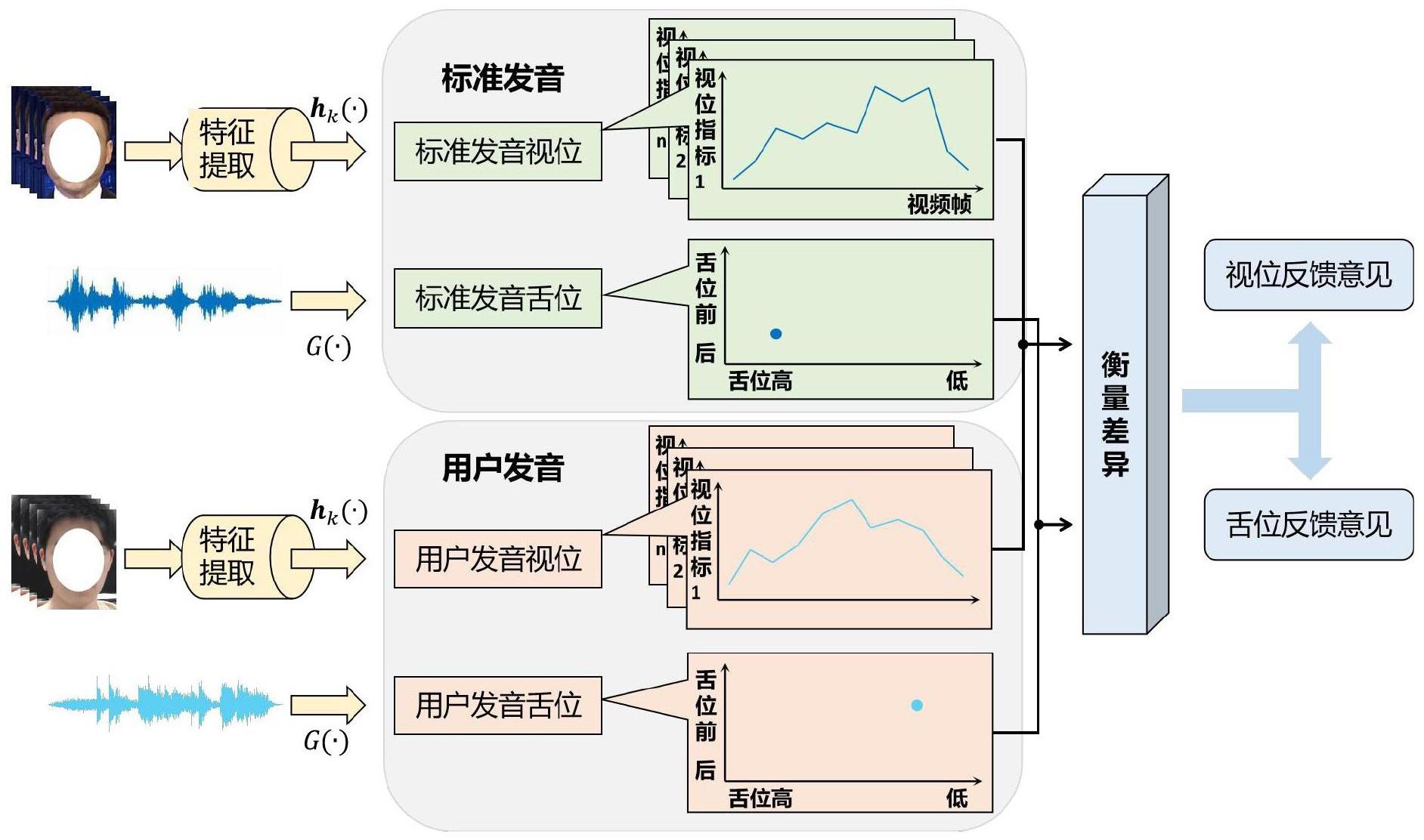
3、人类对语言的理解是多模态的,人的听觉往往会受到视觉的影响,面部肌肉运动的视觉信息与发音之间存在着紧密联系,当人看到的声音与耳朵听到的声音不匹配时常常会发生误听现象,这就是认知心理学中的“麦格克效应”。鉴于面部肌肉运动与语音内容之间存在强烈的关联,我们可以通过衡量视觉上面部动作的标准与否来对该发音的质量进行评估。不同发音对应着不同的面部动作,这与国际标准mpeg-4中定义的视位概念相一致,视位是指与某一音位相对应的嘴、舌头、下腭等可视发音器官所处的状态。设计对不同发音具有区分度的视位指标可以在视觉上有效地区分不同发音,进而能够通过衡量用户发音与标准发音之间的视位差异,以反馈用户发音过程中面部肌肉运动存在的问题并提供改进建议。
4、与此同时,关于中文拼音发音的研究表明,不同的拼音发音与发音时的舌位存在对应关系,舌位是影响发音的一个重要指标。同时舌位又与发音音频的共振峰频率具有较强的关联性,其中前两个共振峰的频率对舌位的前后、高低尤其敏感,因而可以建立音频共振峰频率与舌位之间的映射关系,通过从音频中提取共振峰频率来估计发音的舌位信息。将所得舌位与标准发音舌位比较即可得到关于发音过程中舌位的标准性的评估结果。
技术实现思路
1、针对上述问题,本发明提出一种音视结合的发音质量评估方法,包括:采集标准发音状态下某一音位的标准音视频,获取该音位的标准视位和标准舌位;采集用户实际发音状态的该音位的实际音视频,获取该用户发出该音位的实际视位和实际舌位;分别将该实际视位与标准视位、该实际舌位与该标准舌位进行比对,得到该用户对该音位的发音偏差;基于该发音偏差生成矫正建议,并反馈给该用户进行发音矫正。
2、本发明所述的发音质量评估方法,通过该音位的发音视频,获取该音位发音时的发音器官状态,得到该音位的视位;该视位的指标包括唇上高、唇下高、唇开度、唇展度、唇圆度、下颌开度和唇突度。
3、本发明所述的发音质量评估方法,通过采集该音位的多个标准音视频片段,获取标准视位序列;提取该标准视位序列的最大值vk,max和该标准视位序列的标准差σ_visualk;k∈{1,2,...,n},n为视位指标个数;通过采集该用户对该音位的多个实际音视频片段,获取实际视位序列;提取该实际视位序列的最大值v'k,max;则该用户对该音位的视位发音偏差diff_visualk=vk,max-v'k,max;当diff_visualk大于视位矫正阈值,生成视位矫正建议。
4、本发明所述的发音质量评估方法,当视位指标为唇展度i时:若diff_vissuali<-3σ_vissuali,认为该用户发音时的嘴型宽于标准发音嘴型,发出发音时将嘴唇收窄的视位矫正建议;若diff_vissuali>3σ_visuali,认为该用户发音时的嘴型窄于标准发音嘴型,发出发音时将嘴唇张开的视位矫正建议。
5、本发明所述的发音质量评估方法,通过该音位的发音音频中的共振峰频率,估算该音位发音时的舌位状态,生成该音位的舌位;其中,以第一共振峰频率对应该舌位的高低位置,以第二共振峰频率对应该舌位的前后位置。
6、本发明所述的发音质量评估方法,通过采集该音位的多个标准音视频片段,获取标准舌位序列;提取该标准舌位序列中第一共振峰频率f1的标准差σ_audio1和第二共振峰频率f2的标准差σ_audio2;通过采集该用户对该音位的多个实际音视频片段,获取实际舌位序列;提取该实际舌位序列中第一共振峰频率f'1和第二共振峰频率f'2;则该用户对该音位的第一舌位发音偏差diff_audio1=f1-f'1,第二舌位发音偏差diff_audio2=f2-f'2;当diff_audio1和/或diff_audio2大于舌位矫正阈值,生成舌位矫正建议。
7、本发明所述的发音质量评估方法,若diff_audio1<-3σ_audio1,认为该用户发音时的舌位低于标准发音舌位,发出发音时将舌位抬高的舌位矫正建议;若diff_audio1>3σ_audio1,认为该用户发音时的舌位高于标准发音舌位,发出发音时将舌位放低的舌位矫正建议;若diff_audio2<-3σ_audio2,认为该用户发音时的舌位靠前于标准发音舌位,发出发音时将舌位后缩的舌位矫正建议;若diff_audio2>3σ_audio2,认为该用户发音时的舌位靠后于标准发音舌位,发出发音时将舌位前伸的舌位矫正建议。
8、本发明还提出一种音视结合的发音质量评估系统,包括:标准状态采集模块,用于采集标准发音状态下某一音位的标准音视频,获取该音位的标准视位和标准舌位;实际状态采集模块,用于采集用户实际发音状态的该音位的实际音视频,获取该用户发出该音位的实际视位和实际舌位;发音质量评估模块,用于分别将该实际视位与标准视位、该实际舌位与该标准舌位进行比对,得到该用户对该音位的发音偏差,以评估该用户对该音位的发音质量;矫正模块,用于基于该发音偏差生成矫正建议,并反馈给该用户进行发音矫正。
9、本发明还提出一种计算机可读存储介质,存储有计算机可执行指令,当该计算机可执行指令被执行时,实现如前所述的发音质量评估。
10、本发明还提出一种数据处理装置,包括如前所述的计算机可读存储介质,当该数据处理装置的处理器调取并执行该计算机可读存储介质中的计算机可执行指令时,该数据处理装置实现对用户的发音质量评估。
11、本发明的目的在于利用视觉、听觉双模态信息,为用户提供丰富的发音质量评估方式,以帮助其改进发音过程中的面部动作和舌位,从而达到辅助发音矫正的目的。
技术特征:
1.一种音视结合的发音质量评估方法,其特征在于,包括:
2.如权利要求1所述的发音质量评估方法,其特征在于,通过该音位的发音视频,获取该音位发音时的发音器官状态,得到该音位的视位;该视位的指标包括唇上高、唇下高、唇开度、唇展度、唇圆度、下颌开度和唇突度。
3.如权利要求2所述的发音质量评估方法,其特征在于,通过采集该音位的多个标准音视频片段,获取标准视位序列;提取该标准视位序列的最大值vk,max和该标准视位序列的标准差σ_visualk;k∈{1,2,...,n},n为视位指标个数;
4.如权利要求3所述的发音质量评估方法,其特征在于,当视位指标为唇展度i时:
5.如权利要求1所述的发音质量评估方法,其特征在于,通过该音位的发音音频中的共振峰频率,估算该音位发音时的舌位状态,生成该音位的舌位;其中,以第一共振峰频率对应该舌位的高低位置,以第二共振峰频率对应该舌位的前后位置。
6.如权利要求5所述的发音质量评估方法,其特征在于,通过采集该音位的多个标准音视频片段,获取标准舌位序列;提取该标准舌位序列中第一共振峰频率f1的标准差σ_audio1和第二共振峰频率f2的标准差σ_audio2;
7.如权利要求6所述的发音质量评估方法,其特征在于,
8.一种音视结合的发音质量评估系统,其特征在于,包括:
9.一种计算机可读存储介质,存储有计算机可执行指令,其特征在于,当该计算机可执行指令被执行时,实现如权利要求1~7任一项所述的发音质量评估。
10.一种数据处理装置,包括如权利要求9所述的计算机可读存储介质,当该数据处理装置的处理器调取并执行该计算机可读存储介质中的计算机可执行指令时,该数据处理装置实现对用户的发音质量评估。
技术总结
本发明提出一种音视结合的发音质量评估方法,包括:采集标准发音状态下某一音位的标准音视频,获取该音位的标准视位和标准舌位;采集用户实际发音状态的该音位的实际音视频,获取该用户发出该音位的实际视位和实际舌位;分别将该实际视位与标准视位、该实际舌位与该标准舌位进行比对,得到该用户对该音位的发音偏差;基于该发音偏差生成矫正建议,并反馈给该用户进行发音矫正。本发明还提出一种音视结合的发音质量评估系统,以及一种用于用户发音质量评估的数据处理装置。
技术研发人员:杨双,王飞翔,严哲虞,许卿茹,山世光,陈熙霖
受保护的技术使用者:中国科学院计算技术研究所
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!