一种应用于医疗领域的公平联邦学习方法
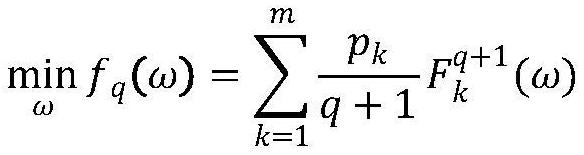
本发明涉及一种联邦学习方法,更具体的说是涉及一种应用于医疗领域的公平联邦学习方法。
背景技术:
1、人工智能在医疗方面的研究工作创造了极大的价值,但是这些研究普遍需要大量的数据来支撑。各级医院拥有大量可用于研究的医学数据,可是只有少部分研究团队可以拿到这些数据,且只能和一两家医院达成合作从而获得部分数据,无法利用各级医院组成的巨大数据集。医院的医学数据中有很多牵扯到患者的隐私,出于对患者隐私的保护,使得各级医院的海量数据更加难以被用于研究。
2、联邦学习技术的应用能够有效帮助多个医疗参与机构数据融合和机器学习联合建模。联邦学习使得各医疗数据参与方在不共享原始数据的基础上,通过密码学算法交互进行联合建模,从技术上打破数据孤岛现象,实现医疗大数据ai协作。
3、联邦学习需要协调不同客户端协同完成模型训练,而医院客户端之间的数据分布差异很大,导致全局模型很难满足所有客户的最优性能,只能趋近于集中训练模型的最优性能。除此之外,大部分联邦学习工作会主要选取数据量作为权重,而在医疗场景下,各家医院的计算资源差距较大,传统的公平性联邦学习不完全适合医疗场景。因此,针对医疗场景的联邦学习公平性研究变得非常必要。
4、如申请号为202111381852.6,名称为联邦学习方法、联邦学习装置、电子设备以及存储介质的发明专利便是公开了现有的联邦学习方法,然而该学习方法没有考虑到各家医院的计算资源,因而该学习方法公平性存在一定的不足。
技术实现思路
1、针对现有技术存在的不足,本发明的目的在于提供一种应用于医院的考虑了医院的计算资源的公平联邦学习方法。
2、为实现上述目的,本发明提供了如下技术方案:一种应用于医疗领域的公平联邦学习方法,包括如下步骤:
3、步骤一,通过各级医院客户端上传的方式,收集各级医院所拥有的cpu、gpu计算资源量到中心服务器,数据量、cpu资源量和gpu资源量这三种属性组成权重pk;
4、步骤二,中心服务器随机从k个医院客户端内选出t个医院客户端,并根据步骤一组成的权重pk计算选出的医院客户端的有效性e和公平性j;
5、步骤三,中心服务器将设定的服务器参数ωt分发给选中的t个医院客户端;
6、步骤四,步骤三中被选出的医院客户端更新本地的参数和
7、步骤五,选中的医院客户端将本地的参数和发给中心服务器,中心服务器更新服务器参数,得到服务器参数ωt+1;
8、步骤六,完成联邦学习。
9、作为本发明的进一步改进,所述步骤二中中心服务器随机从k个医院客户端内选出t个医院客户端之后,通过以下方式计算医院客户端的有效性e和公平性j:
10、结合数据量、cpu资源量和gpu资源量这三种属性组成的权重pk以及各医院客户端本地数据的准确率ak来充当效用rk,并用于评价最终结果的有效性e和公平性j,最终获得如下公式:
11、rk=akpk
12、
13、
14、作为本发明的进一步改进,所述步骤四中更新的本地的参数和通过以下公式计算得出:
15、
16、
17、
18、式中,ωtt为时刻全局参数,为设备k在t时刻在目标函数上以固定步长经过多轮sgd运算后的参数,为设备k在t时刻的参数变化量,l为学习率,为公平性目标函数。
19、作为本发明的进一步改进,所述公平性目标函数如下:
20、
21、式中,pk为公平联邦学习的目标函数权重,q为我们设计的用于调整公平性的参数。
22、作为本发明的进一步改进,所述步骤五中更新服务器参数通过以下公式计算更新:
23、
24、本发明的有益效果,本发明通过获取不同医院的数据量和计算能力,结合联邦学习公平性算法以及公平性评价指标,使得联邦学习在保证医院患者数据隐私的前提下,能够实现医院客户端之间的公平性并取得一定的性能。
技术特征:
1.一种应用于医疗领域的公平联邦学习方法,其特征在于:包括如下步骤:
2.根据权利要求1所述的应用于医疗领域的公平联邦学习方法,其特征在于:所述步骤二中中心服务器随机从k个医院客户端内选出t个医院客户端之后,通过以下方式计算医院客户端的有效性e和公平性j:
3.根据权利要求1或2所述的应用于医疗领域的公平联邦学习方法,其特征在于:所述步骤四中更新的本地的参数和通过以下公式计算得出:
4.根据权利要求3所述的应用于医疗领域的公平联邦学习方法,其特征在于:所述公平性目标函数如下:
5.根据权利要求4所述的应用于医疗领域的公平联邦学习方法,其特征在于:所述步骤五中更新服务器参数通过以下公式计算更新:
技术总结
本发明公开了一种应用于医疗领域的公平联邦学习框架,该框架会将不同医院的数据量以及计算能力设计到目标函数的参数中来并会设计新的效用结合评价指标来实现性能和公平性的度量,同时基于公平性函数α‑fairness设计了新的目标函数来,让参与联邦学习的医院客户端之间的公平性得到保证。本发明选取医院的数据量、CPU数量和GPU数量作为权重,结合新设计的目标函数,同时定义了新的公平性评价方式,实现多医院合作场景下的联邦学习任务,保证了公平性,同时保护了患者数据的隐私,以尽可能实现各医院客户端的最优性能。
技术研发人员:林博,王童,尹建伟
受保护的技术使用者:浙江大学
技术研发日:
技术公布日:2024/11/11
- 还没有人留言评论。精彩留言会获得点赞!