一种基于机器学习的肿瘤ctDNA信息统计处理方法
本发明涉及数据处理,具体涉及一种基于机器学习的肿瘤ctdna信息统计处理方法。
背景技术:
1、肿瘤ctdna信息统计处理是肿瘤诊断和治疗领域的一个快速发展的领域,现在已经有多个公司和机构提供多样化的数据分析服务,如突变检测、突变拆分、高通量测序、数据解释和制定相应病例的分子病理诊断计划等等。一些公司利用高通量测序数据和生物信息学技术研发商业化的分子病理学分析器,其中包括机器学习和人工智能等算法,为临床医生提供存链的分子诊断信息。或者利用信息学工具与算法,提供对ctdna信息的异质性分析,以获得更精准的诊断和治疗信息。随着技术进步和需求不断扩大,ctdna信息统计处理相关正在迅速发展,为肿瘤治疗学和基因组学领域的个性化治疗和分子诊断提供了广阔前景。
2、ctdna检测的技术有很多种,其中最常见的方法是利用ngs技术对ctdna片段及其突变信息进行检测和分析。ngs技术处理ctdna数据虽然在肿瘤诊断和治疗方面具有很大的优势,但由于ctdna浓度较低或者杂质较多会导致一些问题的出现。其中,最主要的问题是难以区分真正的低频突变位点和测序误差。
技术实现思路
1、本发明提供一种基于机器学习的肿瘤ctdna信息统计处理方法,以解决现有的问题。
2、本发明的一种基于机器学习的肿瘤ctdna信息统计处理方法采用如下技术方案:
3、本发明一个实施例提供了一种基于机器学习的肿瘤ctdna信息统计处理方法,该方法包括以下步骤:
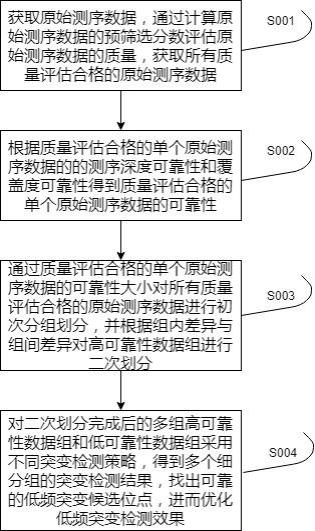
4、获取原始测序数据,通过计算原始测序数据的预筛选分数评估原始测序数据的质量,获取所有质量评估合格的原始测序数据;
5、根据质量评估合格的单个原始测序数据的测序深度可靠性和质量评估合格的单个原始测序数据的覆盖度可靠性得到质量评估合格的单个原始测序数据的可靠性;
6、通过质量评估合格的单个原始测序数据的可靠性大小对所有质量评估合格的原始测序数据进行初次分组划分;得到高可靠性数据组和低可靠性数据组;根据高可靠性数据组组内相似性与高可靠性数据组组间差异性确定高可靠性数据组的最优二次划分分组;得到二次划分完成后的多组高可靠性数据组;
7、对二次划分后每组高可靠性数据组通过全局比对法进行突变检测;对低可靠性数据组针对高度重复和低复杂度区域采用局部比对的突变检测获得突变检测结果,根据突变检测结果得到可靠的低频突变位点,根据可靠的低频突变位点优化低频突变检测效果。
8、优选的,所述原始测序数据的预筛选分数的获取方法如下:
9、原始测序数据的预筛选分数的计算表达式为:
10、
11、式中,表示为的单条原始测序数据的预筛选分数;表示质量分数阈值,表示为的数据的质量分数;表示测序适配器污染阈值,表示为的数据的测序适配器污染值;表示含量分布阈值,表示为的数据的含量分布值;表示阶跃函数。
12、优选的,所述质量评估合格的单个原始测序数据的测序深度可靠性的获取方法如下:
13、单个原始测序数据的测序深度可靠性的计算表达式为:
14、
15、式中,表示为的单条原始测序数据的测序深度可靠性;表示为的单条原始测序数据的第个位点;表示为的单条原始测序数据上所有位点的测序深度值标准差;表示为的单条原始测序数据上所有位点的测序深度值均值;表示为的单条原始测序数据的第个位点中超出期望测序深度值上下限的测序深度值个数占该位点整体测序深度值个数的比例;表示为的单条原始测序数据的测序深度可靠性系数;表示为的单条原始测序数据的测序深度值;表示期望测序深度值上限;表示期望测序深度值下限;表示整组原始测序数据的测序深度值均值;表示整组原始测序数据的测序深度值标准差。
16、优选的,所述质量评估合格的单个原始测序数据的覆盖度可靠性的获取方法如下:
17、单个原始测序数据的覆盖度可靠性的计算表达式:
18、
19、式中,表示为的单条原始测序数据的覆盖度可靠性;表示为的单条原始测序数据上位点的覆盖度超过覆盖度阈值的位点数量;表示为的单条原始测序数据上位点总数量;表示为的单条原始测序数据上位点的覆盖度均值;表示为的单条原始测序数据上位点的覆盖度标准差。
20、优选的,所述质量评估合格的单个原始测序数据的可靠性的获取方法如下:
21、单个原始测序数据的可靠性的计算表达式为:
22、
23、式中,表示为的单条原始测序数据的可靠性;表示为的单条原始测序数据的测序深度可靠性;表示为的单条原始测序数据的覆盖度可靠性。
24、优选的,所述通过质量评估合格的单个原始测序数据的可靠性大小对所有质量评估合格的原始测序数据进行初次分组划分,包括的具体步骤如下:
25、根据单个原始测序数据的测序深度可靠性进行划分,若单个原始测序数据的测序深度可靠性为0,则划分为低可靠性数据组内的单个原始测序数据;若单个原始测序数据的测序深度可靠性不为0,则划分为高可靠性数据组内的单个原始测序数据。
26、优选的,所述根据高可靠性数据组组内相似性与高可靠性数据组组间差异性确定高可靠性数据组的最优二次划分分组,包括的具体步骤如下:
27、将高可靠性数据组分成的所有组的组内相似性求和的值与高可靠性数据组的组间差异性的值做乘积得到分组阈值,根据分组阈值最大值确定出高可靠性数据组的最优二次划分分组。
28、优选的,所述高可靠性数据组分成的所有组的组内相似性的获取方法如下:
29、高可靠性数据组的第组数据的组内相似性的计算表达式为:
30、
31、式中,表示第组数据的组内相似性;表示高可靠性数据组分成的组总数量;表示组内第1数据和第条数据的杰卡德系数;表示组内第和第条数据的杰卡德系数。
32、优选的,所述高可靠性数据组的组间差异性的获取方法如下:
33、组间差异性的计算为对高可靠性数据组中所有组的组内相似性求均值,得到高可靠性数据组的组间相似性。
34、本发明的技术方案的有益效果是:对原始测序数据质量进行评估,将测序数据进行划分,提高数据分析的效率和准确性,优化低频突变检测效果,可以更准确地分析原始测序数据所体现的相关变异因素。
技术特征:
1.一种基于机器学习的肿瘤ctdna信息统计处理方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述一种基于机器学习的肿瘤ctdna信息统计处理方法,其特征在于,所述原始测序数据的预筛选分数的获取方法如下:
3.根据权利要求1所述一种基于机器学习的肿瘤ctdna信息统计处理方法,其特征在于,所述质量评估合格的单个原始测序数据的测序深度可靠性的获取方法如下:
4.根据权利要求1所述一种基于机器学习的肿瘤ctdna信息统计处理方法,其特征在于,所述质量评估合格的单个原始测序数据的覆盖度可靠性的获取方法如下:
5.根据权利要求1所述一种基于机器学习的肿瘤ctdna信息统计处理方法,其特征在于,所述质量评估合格的单个原始测序数据的可靠性的获取方法如下:
6.根据权利要求1所述一种基于机器学习的肿瘤ctdna信息统计处理方法,其特征在于,所述通过质量评估合格的单个原始测序数据的可靠性大小对所有质量评估合格的原始测序数据进行初次分组划分,包括的具体步骤如下:
7.根据权利要求1所述一种基于机器学习的肿瘤ctdna信息统计处理方法,其特征在于,所述根据高可靠性数据组组内相似性与高可靠性数据组组间差异性确定高可靠性数据组的最优二次划分分组,包括的具体步骤如下:
8.根据权利要求7所述一种基于机器学习的肿瘤ctdna信息统计处理方法,其特征在于,所述高可靠性数据组分成的所有组的组内相似性的获取方法如下:
9.根据权利要求7所述一种基于机器学习的肿瘤ctdna信息统计处理方法,其特征在于,所述高可靠性数据组的组间差异性的获取方法如下:
技术总结
本发明涉及数据处理技术领域,具体涉及一种基于机器学习的肿瘤ctDNA信息统计处理方法,包括:获取原始测序数据通过评估原始测序数据质量进行预筛选,对测序数据的测序深度和覆盖度进行分析量化原始测序数据的可靠性,依据可靠性进行第一次数据组的划分,对一次划分后的数据根据组内差异与组间差异进行二次划分,根据数据所在组的特点选择不同的突变检测策略,通过比较多个细分组的变异检测结果,找出可靠的低频突变候选位点,优化低频突变检测效果。本发明对原始测序数据质量进行评估,将测序数据进行划分,提高数据分析的效率和准确性,优化低频突变检测效果,可以更准确地分析原始测序数据所体现的相关变异因素。
技术研发人员:鱼潇,王佳
受保护的技术使用者:西安交通大学医学院第一附属医院
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!