多轮会话式医学影像分析模型的训练方法及应用与流程
本申请涉及会话式模型领域,特别是涉及多轮会话式医学影像分析模型的训练方法及应用。
背景技术:
1、医学影像分析是指利用各种医学影像技术获取的图像数据进行解读和分析的过程。医学影像可以包括x射线、计算机断层扫描(ct扫描)、磁共振成像(mri)、超声波成像、正电子发射计算机断层扫描(pet-ct)等,医学影像分析在医疗领域中扮演着重要的角色,它能够帮助医生进行疾病的诊断、治疗方案的制定和疾病的监测。医学影像分析通常借助计算机辅助诊断(cad)系统来辅助医生进行影像解读和分析,cad系统利用图像处理、模式识别和机器学习等技术,自动提取图像特征,并辅助医生进行诊断和决策。随着人工智能和机器学习的发展,医学影像分析正逐渐向着自动化和智能化方向发展。
2、目前的医学影像分析模型方法一般只有输入图像-输出结果这一种方式,也就是说,使用者将需要分析的医学影像输入到医学影像分析模型中经过分析后得到分析结果,这样的医学影像分析模型无法满足用户的会话式的查询需求。而面向于大众用户的大语言模型虽然可以满足用户的会话式需求,但仅能针对语音文本进行对话,无法针对特定输入的医学影像进行专业的医疗会话。换言之,目前现有技术暂无可靠的可针对医学影像进行多轮会话的分析模型。
技术实现思路
1、本申请实施例提供了一种多轮会话式医学影像分析模型的训练方法及应用,结合医学影像编码器同利用医学领域知识预训练的大语音模型,设计了可用于分析医学影像并回答与医学影像相关的会话式开放查询的多轮会话式医学影像分析模型,满足用户对于医学影像的会话式分析需求。
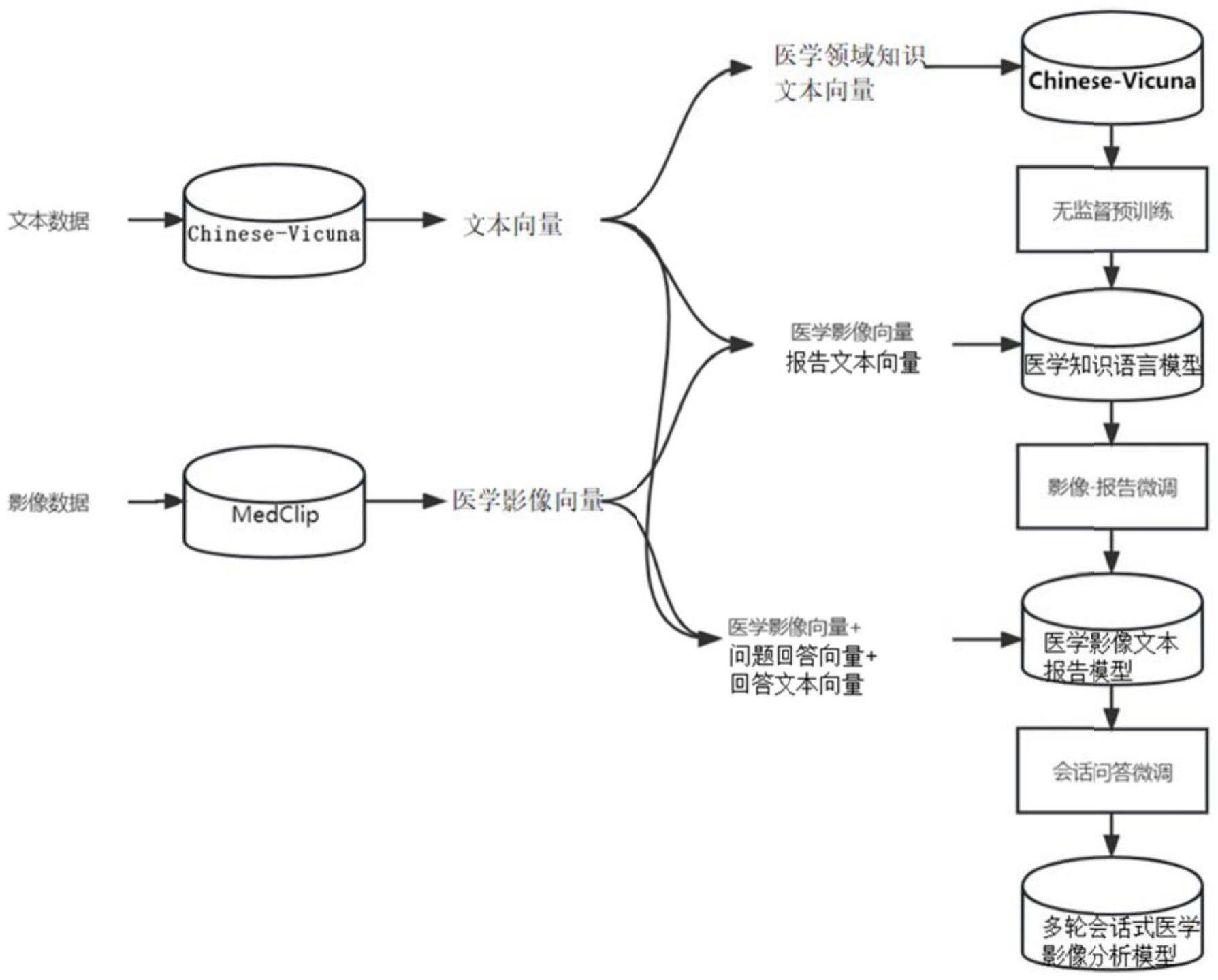
2、第一方面,本申请实施例提供了一种多轮会话式医学影像分析模型的训练方法,包括以下步骤:
3、获取医学领域知识文本数据集,其中医学领域知识文本数据集包括相关于医学影像的医学领域知识,利用医学领域知识文本数据集训练大语言模型得到医学知识语言模型;
4、获取医学影像文本报告数据集,其中所述医学影像文本报告数据集包括多张医学影像以及对应每一医学影像的文本报告;将医学影像文本报告集处理成对应的医学影像向量以及报告文本向量,利用医学影像向量作为医学知识语言模型的初始隐藏状态、对应同一医学影像向量的报告文本向量作为医学知识语言模型的输出结果对医学知识语言模型进行训练得到医学影像文本报告模型;
5、获取针对医学影像的问题回答数据集,其中所述问题回答数据集包括多张医学影像、针对每一医学影像的问题以及针对每一问题的回答,将问题回答数据集处理成对应的医学影像向量、问题文本向量以及回答文本向量,利用医学影像向量和问题文本向量作为医学影像文本报告模型的输入,回答文本向量作为医学影像文本报告模型的输出对医学影像文本报告模型进行训练得到多轮会话式医学影像分析模型。
6、第二方面,本申请实施例提供了一种多轮会话式医学影像分析模型,采用任一所述的多轮会话式医学影像分析模型的训练方法对对应的医学影像进行训练得到。
7、第三方面,本申请实施例提供了一种多轮会话式医学影像分析模型的应用方法,包括:将医学影像输入到医学影像编码器中得到医学影像向量;将医学影像向量输入到对应的任一所述的多轮会话式医学影像分析模型的训练方法训练后的多轮会话式医学影像分析模型中,并将相关该医学影像的问题输入到多轮会话式医学影像分析模型中输出对应的回答。
8、本发明的主要贡献和创新点如下:
9、本申请实施例提供了一种多轮会话式医学影像分析模型的训练方法,通过大量医学领域知识预训练大语音模型得到医学知识语言模型,并将分析医学医影像医学影像编码器与医学知识语言模型通过简单的线性变换对齐后,训练得到可用于分析医学影像并回答与医学影像本身相关的开放式会话查询的多轮会话式医学影像分析模型,融入了医学领域知识的医学知识语言模型其本身强大的对话功能可以很好地帮助完成会话式查询任务,进而使得该多轮会话式医学影像分析模型可以生成关于医学影像丰富的上下文对话,满足用户对医学影像在不同场景下的会话需求。
10、该方案具有强大的灵活性和泛化能力:采用了预训练的大型语言模型,这使得模型具有出色的语言理解和生成能力,可以从大量的非结构化文本中学习,并应用到语言生成任务中,这使得模型在遇到新问题或新情境时也能够产生准确的输出;具有增强的互动性:不同于传统的影像报告生成模型只能生成静态报告,该模型可以根据新问题生成新的答案,让医生可以通过向模型提问获取更深入的洞察,进一步提高诊断的准确性;可以融合多模态的医学信息:将影像和文本信息相结合,因此可以处理更复杂的任务,例如针对特定影像的问题回答。这使得本方案的医学影像分析模型相较于传统的单一模态报告生成模型有更大的优势
11、本申请的一个或多个实施例的细节在以下附图和描述中提出,以使本申请的其他特征、目的和优点更加简明易懂。
技术特征:
1.一种多轮会话式医学影像分析模型的训练方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的多轮会话式医学影像分析模型的训练方法,其特征在于,在“利用医学领域知识文本数据集训练大语言模型得到医学知识语言模型”步骤中,对医学领域知识文本数据集中的医学领域知识进行数据清洗和数据修正,并将每段医学领域知识分割成系列的tokens,将系列tokens输入到大语言模型中进行训练得到医学知识语言模型。
3.根据权利要求1所述的多轮会话式医学影像分析模型的训练方法,其特征在于,在“获取医学影像文本报告数据集”步骤中,将所有医学影像进行图像调整后得到统一规格标准的医学影像,移除缺乏影像描述评估、影像描述不满足要求、影像评估不满足要求的文本报告,并移除文本报告中引用病患过往医疗情况的文本。
4.根据权利要求1所述的多轮会话式医学影像分析模型的训练方法,其特征在于,在“将医学影像文本报告集处理成对应的医学影像向量以及报告文本向量”步骤中,采用预训练的医学影像编码器对医学影像进行处理得到医学影像向量,利用预训练的语言编码器将文本报告进行处理得到报告文本向量,且将医学影像向量通过线性变换层投影到报告文本向量的空间。
5.根据权利要求4所述的多轮会话式医学影像分析模型的训练方法,其特征在于,线性变换层表示为lv=w*vp+b,其中:lv是经过线性变换层后的输出向量,vp是医学影像编码器输出的医学影像向量,w是线性变换层的权重矩阵,b是偏置向量,w和b在训练过程中会不断更新以最小化损失函数。
6.根据权利要求1所述的多轮会话式医学影像分析模型的训练方法,其特征在于,在“将问题回答数据集处理成对应的医学影像向量、问题文本向量以及回答文本向量”步骤中,采用预训练的医学影像编码器对医学影像进行处理得到医学影像向量,利用预训练的语言编码器将问题和回答进行处理得到问题文本向量以及回答文本向量,且将医学影像向量通过线性变换层投影到问题文本向量以及回答文本向量的空间。
7.一种多轮会话式医学影像分析模型,其特征在于,采用权利要求1到7任一所述的多轮会话式医学影像分析模型的训练方法对对应的医学影像进行训练得到。
8.一种多轮会话式医学影像分析模型的应用方法,其特征在于,包括:
9.一种电子装置,包括存储器和处理器,其特征在于,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行权利要求1到7任一所述的多轮会话式医学影像分析模型的训练方法或权利要求8所述的多轮会话式医学影像分析模型的应用方法。
10.一种可读存储介质,其特征在于,所述可读存储介质中存储有计算机程序,所述计算机程序包括用于控制过程以执行过程的程序代码,所述过程包括根据权利要求1到7任一所述的多轮会话式医学影像分析模型的训练方法或权利要求8所述的多轮会话式医学影像分析模型的应用方法。
技术总结
本发明提供一种多轮会话式医学影像分析模型的训练方法及应用,该方案针对多轮会话式医学影像分析模型的训练分为三大阶段,第一阶段是利用医学领域知识文本数据集训练大语言模型得到具有医学领域知识的医学知识语言模型,第二阶段是利用医学影像文本报告数据集训练医学知识语言模型得到可知晓医学影像同文本报告关联关系的医学影像文本报告模型;第三阶段利用问题回答数据集进一步训练医学影像文本报告模型得到可理解问题和医学影像之间的关系且针对问题做出应答的多轮会话式医学影像分析模型。
技术研发人员:许振影,张旷,周华健,傅亦婷,赵宇飞,杨啸天,方震宇
受保护的技术使用者:浙江一山智慧医疗研究有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!