用于推荐安全治疗方案的离线强化学习方法及装置
本发明涉及医学电子病历数据挖掘的,尤其涉及一种用于推荐安全治疗方案的离线强化学习方法,以及用于推荐安全治疗方案的离线强化学习装置。
背景技术:
1、为了提高离线强化学习模型在分布外样本上的适用能力,降低离线学习方法中存在的过高估计问题,调整强化学习部件中的奖励信息是解决方法之一。由于医疗数据以及临床任务的本体特点,患者的个体化差异明显,不同经验的医生治疗方案的制定策略也有所不同,导致分布外样本会频繁出现。离线强化学习通过历史数据治疗轨迹进行策略学习,其中可以分为动作预测模型和状态动作评估模型,预测模型以患者状态为输入信息,预测相应的治疗方案,评估模型以患者状态与治疗方案为输入,输出治疗方案对于患者的评估值,即治疗方案的有效性。对于训练样本,即分布内样本,离线强化学习的评估通常良好。然而在实际治疗方案推荐中可能出现分布外样本,即测试预测样本于训练集样本的分布不一致的样本,导致离线强化学习对于其评估产生较大偏差。
2、因而,对离线强化学习应用于治疗方案推荐的方法须满足以下条件:1.基于离线数据进行学习,但是测试数据可能出现分布外样本;2.对分布外样本须保持合理的评估;3.强化学习模型推荐的治疗方案与专家医师制定的治疗方案相似。
3、用于解决过高估计与分布外样本问题的离线强化学习模型方法众多。如利用推荐方案与记录方案度量距离最小化的正则化方法,构建多个强化学习基础部件以不同初始化的方式进行集成学习。然而上述方法难以应对临床任务中频繁出现的分布外样本问题。
技术实现思路
1、为克服现有技术的缺陷,本发明要解决的技术问题是提供了一种用于推荐安全治疗方案的离线强化学习方法,其能够提高强化学习模型在推荐治疗方案时的性能与安全性,扩展强化学习模型对于评估数据的分布范围,减缓分布外样本与过高估计带来的不利影响。
2、本发明的技术方案是:这种用于推荐安全治疗方案的离线强化学习方法,其包括以下步骤:
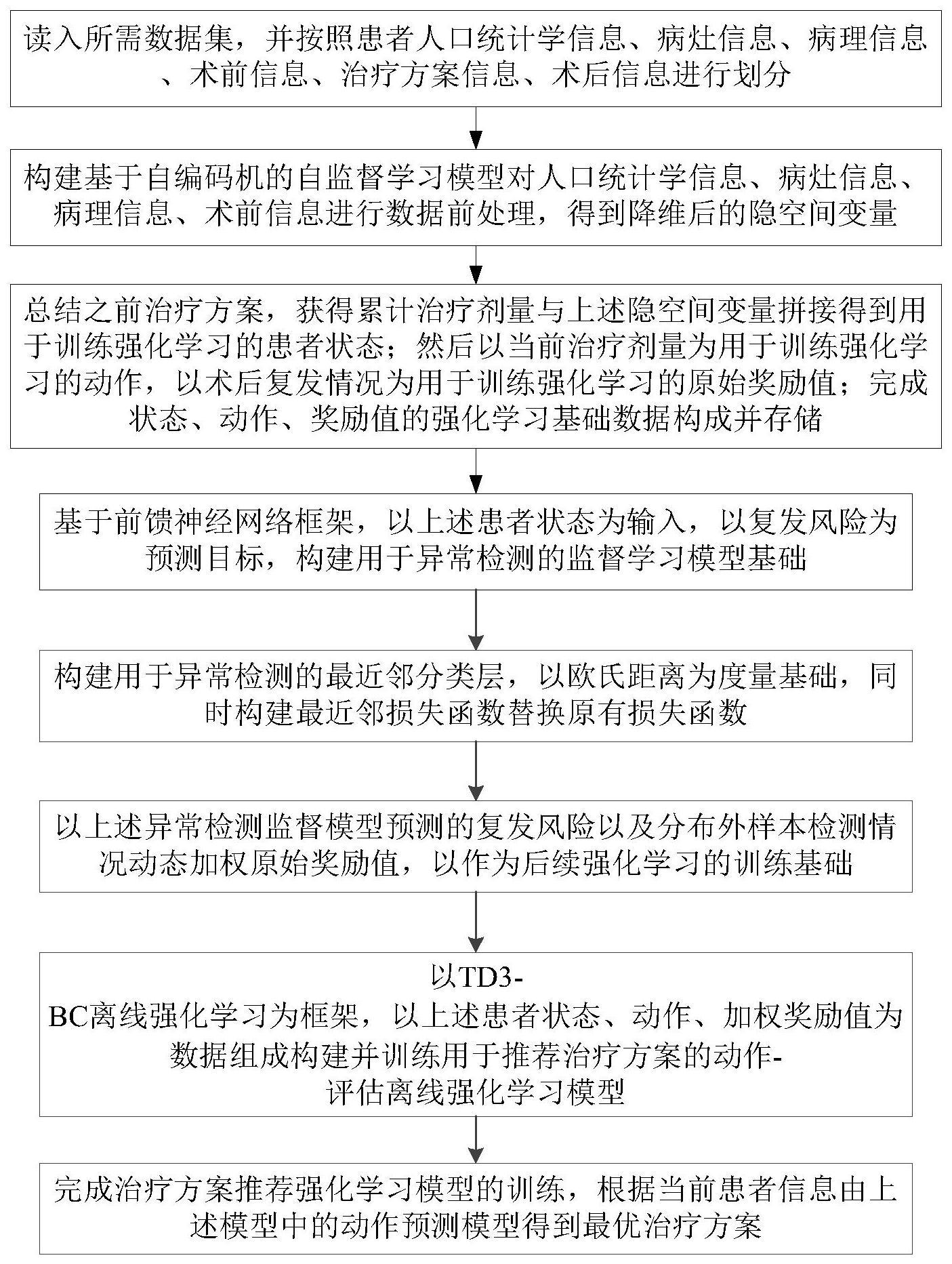
3、(1)读入所需数据集,并按照患者人口统计学信息、病灶信息、病理信息、术前信息、治疗方案信息、术后信息进行划分;
4、(2)构建基于自编码机的自监督学习模型对人口统计学信息、病灶信息、病理信息、术前信息进行数据前处理,得到降维后的隐空间变量;
5、(3)总结之前治疗方案,获得累计治疗剂量与上述隐空间变量拼接得到用于训练强化学习的患者状态;然后以当前治疗剂量为用于训练强化学习的动作,以术后复发情况为用于训练强化学习的原始奖励值;完成状态、动作、奖励值的强化学习基础数据构成并存储;
6、(4)基于前馈神经网络框架,以上述患者状态为输入,以复发风险为预测目标,构建用于异常检测的监督学习模型基础;
7、(5)构建用于异常检测的最近邻分类层,以欧氏距离为度量基础,同时构建最近邻损失函数替换原有损失函数;
8、(6)以上述异常检测监督模型预测的复发风险以及分布外样本检测情况动态加权原始奖励值,以作为后续强化学习的训练基础;
9、(7)以td3-bc离线强化学习为框架,以上述患者状态、动作、加权奖励值为数据组成构建并训练用于推荐治疗方案的动作-评估离线强化学习模型;
10、(8)完成治疗方案推荐强化学习模型的训练,根据当前患者信息由上述模型中的动作预测模型得到最优治疗方案。
11、本发明基于异常检测机制以标签信息引导训练监督学习模型并以此预测奖励值,预测奖励值与原始奖励值的动态加权作为评估信号引导强化学习模型推荐最优治疗方案。异常检测机制以最近邻分类层与最近邻损失函数组成,可与基于神经网络分类模型兼容,灵活性高。离线强化学习模型以td3-bc模型为框架,性能高,预测结果鲁棒。基于异常检测机制识别分布外样本,以此改变奖励值以避免强化学习模型产生过高估计问题。基于异常检测机制可以构建分布外样本数据对,扩展了离线强化学习的可训练数据范围。针对构建人口统计学信息,病灶信息,病理信息,术前信息等时序变化较慢的数据进行编码以降低维度,提高强化学习模型的学习效率。
12、还提供了用于推荐安全治疗方案的离线强化学习装置,其包括:
13、读取模块,其配置来读入所需数据集,并按照患者人口统计学信息、病灶信息、病理信息、术前信息、治疗方案信息、术后信息进行划分;
14、自监督学习模块,其配置来构建基于自编码机的自监督学习模型对人口统计学信息、病灶信息、病理信息、术前信息进行数据前处理,得到降维后的隐空间变量;
15、基础数据构成模块,其配置来总结之前治疗方案,获得累计治疗剂量与上述隐空间变量拼接得到用于训练强化学习的患者状态;然后以当前治疗剂量为用于训练强化学习的动作,以术后复发情况为用于训练强化学习的原始奖励值;完成状态、动作、奖励值的强化学习基础数据构成并存储;
16、异常检测模块,其配置来基于前馈神经网络框架,以上述患者状态为输入,以复发风险为预测目标,构建用于异常检测的监督学习模型基础;
17、最近邻模块,其配置来构建用于异常检测的最近邻分类层,以欧氏距离为度量基础,同时构建最近邻损失函数替换原有损失函数;
18、动态加权模块,其配置来以上述异常检测监督模型预测的复发风险以及分布外样本检测情况动态加权原始奖励值,以作为后续强化学习的训练基础;
19、强化学习建模模块,其配置来以td3-bc离线强化学习为框架,以上述患者状态、动作、加权奖励值为数据组成构建并训练用于推荐治疗方案的动作-评估离线强化学习模型;
20、输出模块,其配置来完成治疗方案推荐强化学习模型的训练,根据当前患者信息由上述模型中的动作预测模型得到最优治疗方案。
技术特征:
1.用于推荐安全治疗方案的离线强化学习方法,其特征在于,其包括以下步骤:
2.根据权利要求1所述的用于推荐安全治疗方案的离线强化学习方法,其特征在于:所述步骤(1)中,读入数据,令其为x,x∈rn×d,n为样本总数,d为特征维度,其中xd,xl,xpth,xper,xt,xpost分别为人口统计学信息,病灶信息,病理信息,术前信息,治疗方案信息,术后信息特征的样本,x={xd∪xl∪xpth∪xper∪xt∪xpost},令xae={xd∪xl∪xpth∪xper}。
3.根据权利要求2所述的用于推荐安全治疗方案的离线强化学习方法,其特征在于:所述步骤(2)中,构建基于自编码机的自监督学习,以得到降维后的隐空间变量:
4.根据权利要求3所述的用于推荐安全治疗方案的离线强化学习方法,其特征在于:所述步骤(3)中,构建用于强化学习模型训练的数据集:
5.根据权利要求4所述的用于推荐安全治疗方案的离线强化学习方法,其特征在于:所述步骤(4)中,基于前馈神经网络部件全连接层fnn(·)与激活函数relu(·)构建分类器,分类监督模型除去最后一层为全连接层与激活函数的嵌套fnni+1(relui(fnni(relui-1(...)))),其中i为模型的当前层数,令最后一层的输出为f。
6.根据权利要求5所述的用于推荐安全治疗方案的离线强化学习方法,其特征在于:所述步骤(5)中,构建用于异常检测的最近邻分类层以及最近邻损失函数:
7.根据权利要求6所述的用于推荐安全治疗方案的离线强化学习方法,其特征在于:所述步骤(6)中,令对不同分布样本检测情况基于异常检测监督模型预测的复发风险为则动态加权后的奖励值为rw=r+rad。
8.根据权利要求7所述的用于推荐安全治疗方案的离线强化学习方法,其特征在于:所述步骤(7)中,以td3-bc离线强化学习为框架,构建离线强化学习模型:
9.根据权利要求8所述的用于推荐安全治疗方案的离线强化学习方法,其特征在于:所述步骤(8)中,基于上述步骤完成治疗方案推荐强化学习模型的训练,最终得到动作预测模型μ*,则得最优治疗方案a=μ*(x)。
10.用于推荐安全治疗方案的离线强化学习装置,其特征在于,其包括:
技术总结
用于推荐安全治疗方案的离线强化学习方法及装置,能够提高强化学习模型在推荐治疗方案时的性能与安全性,扩展强化学习模型对于评估数据的分布范围,减缓分布外样本与过高估计带来的不利影响。方法包括:(1)读入所需数据集,进行划分;(2)进行数据前处理,得到降维后的隐空间变量;(3)完成状态、动作、奖励值的强化学习基础数据构成并存储;(4)构建用于异常检测的监督学习模型基础;(5)构建用于异常检测的最近邻分类层,最近邻损失函数;(6)以上述异常检测监督模型预测的复发风险以及分布外样本检测情况动态加权原始奖励值;(7)构建并训练用于推荐治疗方案的动作‑评估离线强化学习模型;(8)得到最优治疗方案。
技术研发人员:宋红,翁旭涛,林毓聪,杨健,艾丹妮,范敬凡,付天宇,肖德强
受保护的技术使用者:北京理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!