一种面向精神疾病文本的多层次特征融合分类方法与流程
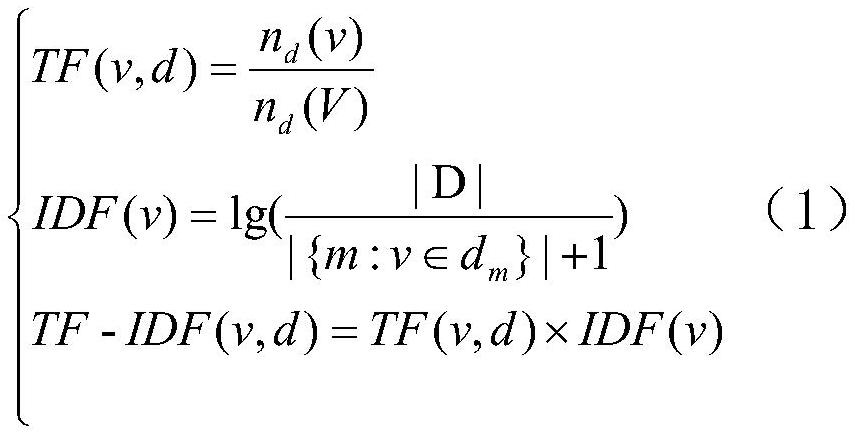
本发明涉及一种面向精神疾病文本的多层次特征融合分类方法,该方法适用于精神疾病文本的分类。
背景技术:
0、技术背景
1、在过去的几年里,基于深度学习的方法在自然语言处理领域卓有成效。一方面,卷积神经网络因为其局部感受野、权值共享等特性,已经普遍的应用在自然语言处理领域,例如vgg、resnet等,其中,textcnn在cnn的基础上进行了一定的变形,在简单的网络模型结构下,依旧能够具有不错的效果。另一方面,循环神经网络因为其能够获取到上下文信息,同样是自然语言处理领域的重要技术,例如lstm、gru等。而bilstm作为lstm的变种,通过引入前向和后向的lstm网络,使得模型同时具有文本的上下文信息。
2、在精神疾病的治疗上,医生和病人间的对话是医生主要诊断患者是否患有精神疾病以及精神疾病种类的主要依据,通过人工智能技术,对医生与患者之间的对话进行语义分析,可以帮助对精神疾病的辅助诊断以及判别。现阶段大多数对语义的研究都是对微博、论坛等用户可以自由发言的平台上的帖子进行数据抓取并进行相应的研究,几乎没有直接在医疗领域的应用。
3、目前国内基本没有使用人工智能技术对精神疾病问诊过程中的开放性对话文本进行分析的相关研究。即使有使用单一模型者,其准确率不高,对于精神疾病问诊过程中的开放性对话文本,有待人们去设计高效率、高准确率的机器学习模型,
技术实现思路
1、本发明的目的是为了解决现有技术的需要及不足而提供一种面向精神疾病文本的多层次特征融合分类方法,从医生与患者之间的交流对话中提取源数据,以此训练设计的机器学习模型并进行相应的测试,通过不断的迭代更新,能获得高性能、高准确率的机器学习模型。
2、为了达到上述目的,本发明提供的一种面向精神疾病文本的多层次特征融合分类方法,包括以下步骤:
3、步骤一:精神疾病问诊过程中的开放性对话录音预处理;
4、步骤二:训练面向精神疾病文本的多层次特征融合模型;
5、步骤三:识别患者是否患有精神疾病以及精神疾病种类。
6、步骤一具体包括:
7、将采集到的精神疾病问诊过程中的开放性对话录音通过使用市面上成熟的asr(自动语音识别)技术进行转译,将语音转化为文本。
8、人工校验asr技术转译后的文本,将其中存在的转译错误进行修正。
9、(1.1)对文本中存在的嘈杂信息剔除,例如非患者以及医生的对话(问诊过程中可能存在其他人进来说话的情况)。
10、步骤二具体包括:
11、(2.1)将步骤一中处理好的精神疾病问诊过程中的开放性对对话文本收集整理为文本数据集,将医生的诊断结果作为标签,将文本与标签进行对应。按照7:1:2的比例进行划分,将数据集划分为训练集、验证集、测试集。
12、(2.2)使用word2vec在训练集上训练出词向量模型,词向量维度为100,使用cbow模式进行训练,训练得到词向量模型。并使用训练好的word2vec模型将文本向量化。
13、(2.3)使用tf-idf(词频-逆文本概率)算法以及chi(卡方检验)算法计算文本中每个词的重要性指标,tf-idf算法如公式(1)所示,chi算法如公式(2)所示。通过重要性指标提取出每个对话文本的关键词,并将关键词通过word2vec模型向量化,作为模型的关键词特征。
14、
15、
16、(2.4)使用textcnn提取文本的局部特征。textcnn分为三层,每一层的卷积核大小分别为2、3、4,每一层的隐藏层神经元数量为128。
17、(2.5)使用bilstm提取文本的全局特征。每一层的隐藏层神经元数量为128,并使用attention层对bilstm产生的输出向量进行加权。
18、(2.6)将提取到的关键词特征、局部特征和全局特征进行拼接,将拼接后的特征进行全连接作为最后的特征,并通过softmax函数进行分类。输出结果为0(无病)、1(抑郁症)、2(精神分裂症)、3(双相情感障碍)。
19、步骤三具体包括:
20、(3.1)将对话内容转译成文本。
21、(3.2)加载步骤二中存储的训练好的面向精神疾病文本的多层次特征融合分类模型,将对话文本输入到模型中。
22、(3.3)得到识别结果。
23、本发明的技术特点及效果:
24、1)本发明使用tf-idf算法以及chi算法提取出文本的关键词,增加了文本分类特征的维度。
25、2)通过融合关键词特征、局部特征和全局特征,使分类器能够使用的特征更加丰富,进而提高分类器的准确率。
26、3)相对于其他的词向量模型(例如bert等)体积更小,收敛速度更快。
27、4)本发明能够在实际应用情况下具有较高的识别准确率和识别速度,能够较好的辅助诊断。
技术特征:
1.一种面向精神疾病文本的多层次特征融合分类方法,包括以下步骤:
技术总结
一种面向精神疾病文本的多层次特征融合分类方法,包括以下步骤:步骤一:精神疾病问诊过程中的开放性对话录音预处理;步骤二:训练面向精神疾病文本的多层次特征融合模型;步骤三:识别患者是否患有精神疾病以及精神疾病种类。本发明的技术特点及效果:1、本发明使用TF‑IDF算法以及CHI算法提取出文本的关键词,增加了文本分类特征的维度。2、通过融合关键词特征、局部特征和全局特征,使分类器能够使用的特征更加丰富,进而提高分类器的准确率。3、相对于其他的词向量模型(例如Bert等)体积更小,收敛速度更快。本发明能够在实际应用情况下具有较高的识别准确率和识别速度,能够较好的辅助诊断。
技术研发人员:池凯凯,张闰哲,毛科技,张华,徐金宇
受保护的技术使用者:杭州工成数智科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!