一种基于云端AI自动优化的疫苗需求量预测方法与流程
本发明涉及统计学和机器学习,尤其涉及一种基于云端ai自动优化的疫苗需求量预测方法。
背景技术:
1、随着人工智能的发展、大数据的应用、物联网和互联网技术的普及,人工智能和大数据应该渗透到各行各业。目前疫苗注射关乎民生,每个人在对应的成长期都要注射相应种类的疫苗,因此疫苗种类众多。同时随着疫苗接种的普及,各个国家各个地区的人口都在接种疫苗,因此疫苗生产流通数量巨大。有些疫苗的需求量具有突发性,但是大多数具有规律性。如果对疫苗的需求数量没有一种科学的预测方法,将会出现疫苗需求量激增时疫苗短缺情况;同时,由于疫苗具有固定生命周期,保证注射的疫苗具有活性;如果对疫苗需求量没有科学预测,还会出现疫苗大量浪费的情况。
技术实现思路
1、鉴于上述的分析,本发明实施例旨在提供一种基于云端ai自动优化的疫苗需求量预测方法,用以解决现有疫苗的需求量缺乏科学预测方法的问题。
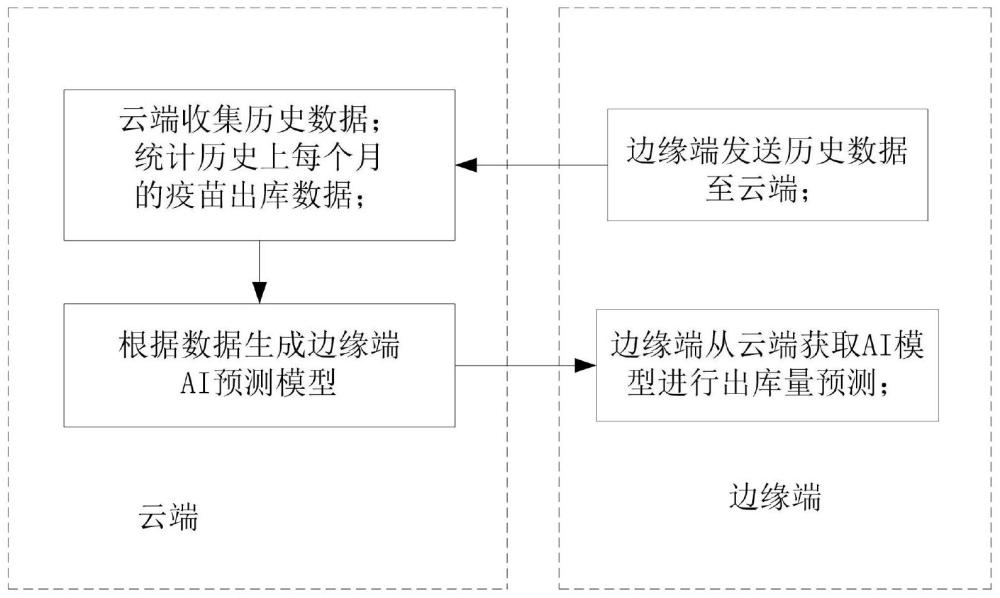
2、本发明实施例提供了一种基于云端ai自动优化的疫苗需求量预测方法,各边缘端服务器将获取的智慧冷库的历史疫苗数据发送至云端;
3、云端建立各个边缘端的ai预测模型;所述ai预测模型为混合长短期记忆模型lstm、向量自回归滑动平均模型varima、时间序列模型prophet的加权平均模型;
4、云端基于各边缘端发送的历史疫苗数据构建相应ai预测模型的训练样本集,利用所述训练样本集对各ai预测模型进行训练得到训练好的各边缘端ai预测模型;
5、将训练好的各ai预测模型和模型参数发送到相应边缘端服务器;各个边缘端服务器基于训练好的ai预测模型对各自智慧冷库未来疫苗需求量进行预测。
6、进一步的,ai预测模型基于三种预测模型的最小均方差mse分配权重,
7、每种预测模型的权重αk为:
8、
9、其中,k=1、2、3,msek为每种预测模型的均方误差。
10、进一步的,所述智慧冷库的历史疫苗数据为该冷库不同种类疫苗在历史日期的出库数量;
11、云端基于各边缘端发送的历史疫苗数据构建相应ai预测模型的训练样本集,包括:
12、根据各类疫苗在历史日期的出库数量,统计得到各类疫苗在历史各月份的出库数量;
13、将不同种类疫苗在不同月份的出库数量采用tensor张量记录,所述tensor张量作为lstm模型的训练样本集;
14、将不同种类疫苗在不同月份的出库数量形成数据框dataframe,所述dataframe作为varima和prophet模型的训练样本集。
15、进一步的,每个边缘端的ai预测模型中,所述prophet模型包括多个prophet子模型,每个prophet子模型用于预测边缘端所在地区的一种疫苗的需求量;所述混合长短期记忆模型lstm用于预测对应边缘端所在地区的所有疫苗的需求量;所述向量自回归滑动平均模型varima用于预测对应边缘端所在地区的所有疫苗的需求量。
16、进一步的,lstm模型训练样本集的数据张量tensor的格式为(n,t,1),其中,维度n代表疫苗的种类,维度t代表时间步长数,维度1代表疫苗实际出库数量;varima模型和prophet模型训练样本集的dataframe格式为(t1,d1,d2,...,dn),其中,t1代表年月,d1、d2...dn代表与t1对应的不同种类疫苗的实际出库数量。
17、进一步的,varima模型训练过程包括:
18、确定模型参数p、d、q的区间范围,其中p为自回归部分参数,d为差分部分参数,q为移动平均部分参数,且p、d、q均取整数;初始化varima模型时,将p、d、q初始值及时间周期长s输入模型,同时将数据框dataframe也输入模型;然后调用训练函数对varima模型进行训练,通过网格搜索法确定参数p、d、q,即在p、d、q三个参数的不同组合之下,计算出疫苗需求量预测值和真实值的均方差,找出各种疫苗均方差之和最小时p、d、q的组合作为所需的varima模型参数值。
19、进一步的,各边缘端的prophet子模型训练过程包括:
20、将各数据框dataframe中每种疫苗在不同月份的出库量数据输入相应的prophet子模型进行训练;
21、采用贝叶斯优化方法确定各prophet子模型的参数,分别定义参数seasonality_prior_scale和changepoint_prior_scale的搜索空间范围,在设定的迭代次数内,计算疫苗出库量预测值与真实值之间的均方误差;将均方误差取最小值时的参数作为最佳的参数seasonality_prior_scale和changepoint_prior_scale,进而得到训练好的各prophet子模型。
22、进一步的,lstm模型训练过程中使用adm优化器,通过mse均方误差来优化训练参数,通过早停算法对训练叫停。
23、进一步的,所述lstm模型数据包括依次连接的第一选择记忆模块、第二选择记忆模块、输出层;所述第一选择记忆模块和第二选择记忆模块均包括依次连接的lstm层和dropout层;输出层用来输出各种疫苗的预测需求量。
24、进一步的,第一选择记忆模块的lstm神经元数量设置为64,第二选择记忆模块的lstm神经元个数设为32,时间步长为12;dropout层概率值设置为θ,θ的范围在[0,0.2]。
25、与现有技术相比,本发明至少可实现如下有益效果之一:
26、1、本申请采用混合lstm模型,varima模型和prophet模型的加权平均模型对大数据进行处理分析,综合运用了统计学和机器学习方法,同时兼顾了统计学的模型计算准确度以及机器学习较强的泛化学习能力,因此能够学习到各种疫苗在时间序列上的规律,提高模型的适用性的同时又保证了预测精度。并且通过三个模型之间的权重配置,实现了高精准度的疫苗需求预测。
27、2、本申请提供了一种科学的疫苗出库数据预测方法,可缓解疫苗需求量激增时疫苗短缺情况;同时避免不必要的生产,减少浪费。
28、本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
技术特征:
1.一种基于云端ai自动优化的疫苗需求量预测方法,其特征在于,
2.根据权利要求1所述的预测方法,其特征在于,ai预测模型基于三种预测模型的最小均方差mse分配权重,
3.根据权利要求1所述的预测方法,其特征在于,所述智慧冷库的历史疫苗数据为该冷库不同种类疫苗在历史日期的出库数量;
4.根据权利要求3所述的预测方法,其特征在于,每个边缘端的ai预测模型中,所述prophet模型包括多个prophet子模型,每个prophet子模型用于预测边缘端所在地区的一种疫苗的需求量;所述混合长短期记忆模型lstm用于预测对应边缘端所在地区的所有疫苗的需求量;所述向量自回归滑动平均模型varima用于预测对应边缘端所在地区的所有疫苗的需求量。
5.根据权利要求4所述的预测方法,其特征在于,lstm模型训练样本集的数据张量tensor的格式为(n,t,1),其中,维度n代表疫苗的种类,维度t代表时间步长数,维度1代表疫苗实际出库数量;varima模型和prophet模型训练样本集的dataframe格式为(t1,d1,d2,...,dn),其中,t1代表年月,d1、d2...dn代表与t1对应的不同种类疫苗的实际出库数量。
6.根据权利要求4所述的预测方法,其特征在于,varima模型训练过程包括:
7.根据权利要求5所述的预测方法,其特征在于,
8.根据权利要求5所述的预测方法,其特征在于,lstm模型训练过程中使用adm优化器,通过mse均方误差来优化训练参数,通过早停算法对训练叫停。
9.根据权利要求8所述的预测方法,其特征在于,所述lstm模型数据包括依次连接的第一选择记忆模块、第二选择记忆模块、输出层;所述第一选择记忆模块和第二选择记忆模块均包括依次连接的lstm层和dropout层;输出层用来输出各种疫苗的预测需求量。
10.根据权利要求9所述的预测方法,其特征在于,第一选择记忆模块的lstm神经元数量设置为64,第二选择记忆模块的lstm神经元个数设为32,时间步长为12;dropout层概率值设置为θ,θ的范围在[0,0.2]。
技术总结
本发明涉及一种基于云端AI自动优化的疫苗需求量预测方法,包括:各边缘端服务器将获取的智慧冷库的历史疫苗数据发送至云端;云端建立各个边缘端的AI预测模型;所述AI预测模型为混合长短期记忆模型LSTM、向量自回归滑动平均模型VARIMA、时间序列模型Prophet的加权平均模型;云端基于各边缘端发送的历史疫苗数据构建相应AI预测模型的训练样本集,利用所述训练样本集对各AI预测模型进行训练得到训练好的各边缘端AI预测模型;将训练好的各AI预测模型和模型参数发送到相应边缘端服务器;各个边缘端服务器基于训练好的AI预测模型对各自智慧冷库未来疫苗需求量进行预测。
技术研发人员:石铁军,傅超,蒋鹏,谷双双
受保护的技术使用者:沈苏科技(苏州)股份有限公司
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!