一种加速碱基识别的测序和分析系统及碱基识别装置的制作方法
本发明涉及生物基因数据处理领域和计算机系统结构设计领域,尤其是一种加速碱基识别的新型测序和分析系统,以及配置该系统的碱基识别装置。
背景技术:
1、基因测序是基因研究的基础,它指的是通过生物技术来直接获取生物体内的脱氧核糖核酸(dna)序列或者核糖核酸(rna)序列的技术。目前最有潜力的测序技术是三代测序技术。三代测序技术直接将dna序列穿过纳米孔(称为流孔),不同的碱基序列将产生不同强度的电流,通过对电流的识别即可得到待测序的碱基序列。基因分析指的是对测序得到的序列进行组装识别等分析过程,最终得到其生物含义。基因分析的关键点是将测序仪得到的信号翻译成a,c,g,t和n五种碱基,这一过程被称为碱基识别。碱基识别是基因分析技术的主要瓶颈,尽管目前学术界与工业界提出了大量的基因分析架构加速碱基识别,但是基因分析的吞吐量仍远远跟不上基因测序的吞吐量,通量差距是基因分析的一个关键难题,在基因分析加速研究中占据着十分重要的地位。
2、图1显示了传统的测序系统和碱基识别的流水线,其主要分成三步:第一步,cpu内核使用minknow软件控制流动池开始测序;第二步,流动池将输入基因组测序为电信号并写入dram;第三步,cpu将电信号传输到远程服务器(如英伟达a100 gpu),完成碱基识别过程。这种方案能效较低,离边缘基因组分析还很远。
3、测序仪的标准吞吐量为2050000信号每秒。如果仅考虑吞吐量,目前也有一些碱基识别工具例如bonito可以达到这个吞吐量,但是他们计算量非常大。例如,bonito需要高端的nvidia a100 gpu才能达到4300000信号每秒,功耗高达250瓦特。当前的测序仪基准吞吐量为34167信号每秒每瓦特。当考虑到碱基识别的能效,目前碱基识别工具和测序仪的吞吐量存在1至3个数量级的差距。此外,主流的加速器如《helix:algorithm/architecture co-design for accelerating nanopore genome base-calling》(q.lou等)中所介绍的helix,其也和测序仪基准吞吐量差了两个数量级。这意味着碱基识别加速器的设计不仅需要具有高的吞吐量,此外还必须在能耗方面具有优势。这样才能使得移动端测序变成可能。
4、综上所述,现阶段基因分析需要一种高吞吐量、高能效的新型测序和分析系统去加速碱基识别。
技术实现思路
1、本发明的发明目的在于:针对上述存在的全部或部分问题,提供一种加速碱基识别的测序和分析系统及碱基识别装置,以实现高吞吐量、高能效地碱基识别。
2、本发明采用的技术方案如下:
3、一种加速碱基识别的测序和分析系统,包括流动池、dram和cpu;所述cpu控制所述流量池对输入的基因组进行测序;所述流量池将所述基因组测序为电信号并写入所述dram;所述cpu获取所述dram中的所述电信号,利用cpu中的高速缓存内碱基识别架构进行碱基识别;其中,
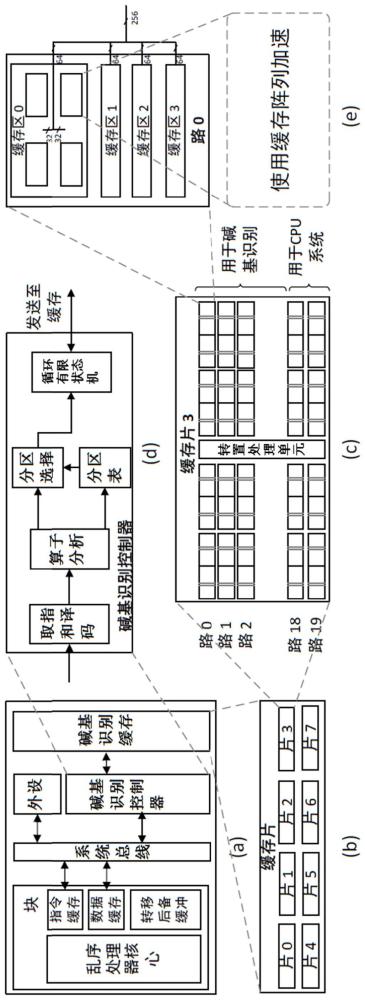
4、所述高速缓存内碱基识别架构包括碱基识别控制器和碱基识别缓存;所述碱基识别控制器接收并解析cpu内核的指令,在该指令指示执行加速模式的情况下,根据预配置的分区表,选择所述碱基识别缓存中相应的缓存阵列来执行碱基识别计算。
5、进一步的,所述碱基识别缓存包含缓存片阵列,对于所述缓存片阵列中的各缓存片,在其分片表中配置有指示标识,以指示该缓存片所执行的指令类型。
6、进一步的,通过对所述缓存片阵列预先执行测试任务,根据执行测试任务时各缓存片中关键算子的时间占比,来确定为所述缓存片阵列中各缓存片所配置的指示标识类型。
7、进一步的,所述缓存片阵列包含排序依次为0~7的缓存片,其中,缓存片0~缓存片3被配置第一类指示标识,以执行编码部分的指令,缓存片4到缓存片5被配置第二类指示标识,以执行集束搜索的指令,缓存片6到缓存片7被配置第三类指示标识,以执行字符转换的指令。
8、进一步的,所述缓存片包含多路缓存资源,所述缓存片的分片表中配置有激活标识,所述激活标识在加速模式情况下,指示激活预配置的那些路的缓存资源来执行碱基识别计算。
9、进一步的,所述缓存片中的第0路-第17路缓存资源被配置为在加速模式下执行碱基识别计算,在非加速模式下执行cpu正常运行,第18路-第19路缓存资源被配置为始终执行cpu正常运行。
10、进一步的,每一路缓存资源均包含多个缓存区,每个缓存区均包含有多个缓存阵列;所述碱基识别控制器利用为各缓存区配置的循环有限状态机执行对各缓存区中缓存阵列的控制。
11、进一步的,所述碱基识别控制器被配置为:
12、根据cpu内核的指令的指示,激活加速模式,以激活各缓存片中相应的缓存资源以备执行碱基识别计算;以及
13、将关键算子的时间占比写入各缓存片的分片表。
14、进一步的,所述碱基识别控制器配置有第一类接口、第二类接口和第三类接口;通过所述第一类接口选择运行模式和配置分区表;通过第二类接口发送或者接收数据;通过第三类接口调用关键运算符。
15、本发明还提供了一种碱基识别装置,所述碱基识别装置上配置有上述的加速碱基识别的测序和分析系统。
16、综上所述,由于采用了上述技术方案,本发明的有益效果是:
17、1、当下的加速器大多数没有完全加速碱基识别这一瓶颈操作,导致吞吐量比测序仪吞吐量低,即使最新的squigglefilter技术,它也只适用于病毒序列,不能直接加速碱基识别。本发明提出的加速系统全面加速了碱基识别,经试验可承担15台测序仪的测序吞吐量。
18、2、本发明通过增强测序仪中cpu的缓存来实现碱基识别的计算加速,通过引入高速缓存,将瓶颈操作卸载到高速缓存运算中。
技术特征:
1.一种加速碱基识别的测序和分析系统,包括流动池、dram和cpu;其特征在于,所述cpu控制所述流量池对输入的基因组进行测序;所述流量池将所述基因组测序为电信号并写入所述dram;所述cpu获取所述dram中的所述电信号,利用cpu中的高速缓存内碱基识别架构进行碱基识别;其中,
2.如权利要求1所述的加速碱基识别的测序和分析系统,其特征在于,所述碱基识别缓存包含缓存片阵列,对于所述缓存片阵列中的各缓存片,在其分片表中配置有指示标识,以指示该缓存片所执行的指令类型。
3.如权利要求2所述的加速碱基识别的测序和分析系统,其特征在于,通过对所述缓存片阵列预先执行测试任务,根据执行测试任务时各缓存片中关键算子的时间占比,来确定为所述缓存片阵列中各缓存片所配置的指示标识类型。
4.如权利要求3所述的加速碱基识别的测序和分析系统,其特征在于,所述缓存片阵列包含排序依次为0~7的缓存片,其中,缓存片0~缓存片3被配置第一类指示标识,以执行编码部分的指令,缓存片4到缓存片5被配置第二类指示标识,以执行集束搜索的指令,缓存片6到缓存片7被配置第三类指示标识,以执行字符转换的指令。
5.如权利要求2所述的加速碱基识别的测序和分析系统,其特征在于,所述缓存片包含多路缓存资源,所述缓存片的分片表中配置有激活标识,所述激活标识在加速模式情况下,指示激活预配置的那些路的缓存资源来执行碱基识别计算。
6.如权利要求5所述的加速碱基识别的测序和分析系统,其特征在于,所述缓存片中的第0路-第17路缓存资源被配置为在加速模式下执行碱基识别计算,在非加速模式下执行cpu正常运行,第18路-第19路缓存资源被配置为始终执行cpu正常运行。
7.如权利要求6所述的加速碱基识别的测序和分析系统,其特征在于,每一路缓存资源均包含多个缓存区,每个缓存区均包含有多个缓存阵列;所述碱基识别控制器利用为各缓存区配置的循环有限状态机执行对各缓存区中缓存阵列的控制。
8.如权利要求5所述的加速碱基识别的测序和分析系统,其特征在于,所述碱基识别控制器被配置为:
9.如权利要求8所述的加速碱基识别的测序和分析系统,其特征在于,所述碱基识别控制器配置有第一类接口、第二类接口和第三类接口;通过所述第一类接口选择运行模式和配置分区表;通过第二类接口发送或者接收数据;通过第三类接口调用关键运算符。
10.一种碱基识别装置,其特征在于,所述碱基识别装置上配置有如权利要求1-9任一所述的加速碱基识别的测序和分析系统。
技术总结
本发明公开了一种加速碱基识别的测序和分析系统及碱基识别装置,属于生物极影数据处理领域,用以实现高吞吐量、高能效地碱基识别。本发明利用CPU控制流量池对输入的基因组进行测序;流量池将基因组测序为电信号并写入DRAM;CPU获取DRAM中的电信号,利用高速缓存内碱基识别架构进行碱基识别。该架构包括碱基识别控制器和碱基识别缓存。碱基识别控制器接收并解析CPU内核的指令,在该指令指示执行加速模式的情况下,根据预配置的分区表,选择碱基识别缓存中相应的缓存阵列来执行碱基识别计算。本发明通过增强测序仪中CPU的缓存来实现碱基识别的计算加速,通过引入高速缓存,将瓶颈操作卸载到高速缓存运算中,可承担15台测序仪的测序吞吐量。
技术研发人员:谭光明,李叶文
受保护的技术使用者:中科计算技术西部研究院
技术研发日:
技术公布日:2024/5/19
- 还没有人留言评论。精彩留言会获得点赞!