一种基于多中心的血液透析大数据模型构建方法
本发明涉及于模型构建,尤其涉及一种基于多中心的血液透析大数据模型构建方法。
背景技术:
1、目前,随着大数据的发展,大数据模型构建被广泛的运用在各种领域,例如,医疗领域、金融领域、市场营销、能源领域等众多领域、他们都使用先进的数据挖掘和分析技术,如机器学习和人工智能,从大规模数据中提取模式和见解,但是,如果有多个数据获取来源,单一的分析每个数据源的数据会造成数据偏差很大,数据源数据的无用数据较多造成分析不准确。
2、因此,本发明提出了一种基于多中心的血液透析大数据模型构建方法。
技术实现思路
1、本发明提供一种基于多中心的血液透析大数据模型构建方法,用以通过获取多中心血液透析的数据,集合到数据原始库中,之后根据数据类型标签筛选并处理原始数据,得到分类标准数据,之后提取分类标准数据特征数据作为测试集,分类标准数据划为训练集,完成对血液透析大数据模型的构建和训练。
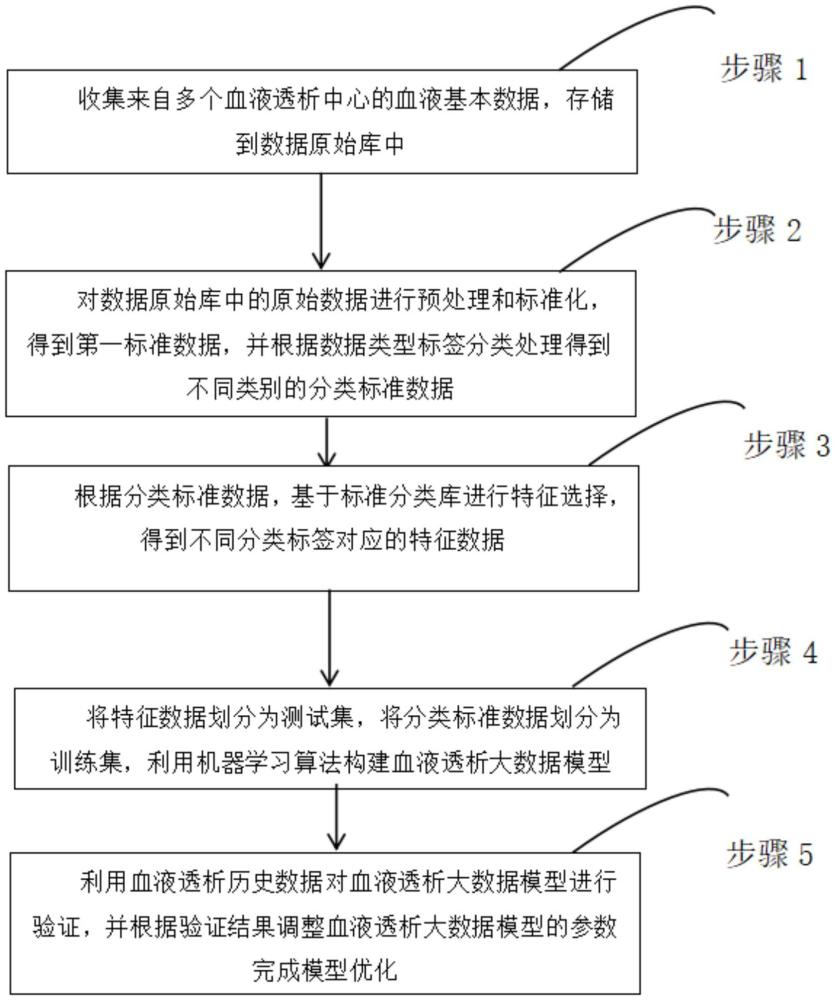
2、一方面,本发明提供一种基于多中心的血液透析大数据模型构建方法,包括:
3、步骤1:收集来自多个血液透析中心的血液基本数据,存储到数据原始库中;
4、步骤2:对数据原始库中的原始数据进行预处理和标准化,得到第一标准数据,并根据数据类型标签分类处理得到不同类别的分类标准数据;
5、步骤3:根据分类标准数据,基于标准分类库进行特征选择,得到不同分类标签对应的特征数据;
6、步骤4:将特征数据划分为测试集,将分类标准数据划分为训练集,利用机器学习算法构建血液透析大数据模型;
7、步骤5:利用血液透析历史数据对血液透析大数据模型进行验证,并根据验证结果调整血液透析大数据模型的参数完成模型优化。
8、另一方面,收集来自多个血液透析中心的血液基本数据,包括:
9、确定要收集的血液透析基本数据的具体内容和范围,得到标准透析数据内容和标准透析范围;
10、确定血液透析的所有目标中心,结合血液透析的标准透析数据内容和标准透析范围制定数据收集方案,根据数据收集方案在目标中心获取血液基本数据。
11、另一方面,存储到数据原始库中,包括:
12、根据预设数据库标准,设计和建立数据原始库;
13、将血液基本数据按照标准字段预处理,之后基于预设安全传输协议,存储到数据原始库中,其中,所述标准字段基于标准透析数据内容-标准字段映射表获取;
14、另一方面,对数据原始库中的原始数据进行预处理和标准化,得到第一标准数据,包括:
15、根据预设抽选字段,根据数据库查询语句的构成,对应字段逻辑顺序构成数据原始库的第一查询语句;
16、利用第一查询语句在数据原始库中匹配获取到对应的原始数据;
17、将原始数据按照标准编码格式转化为标准编码数据,基于数据预处理的格式将所述标准编码数据进行预处理得到第一数据,并且为每个第一数据配置数据标签类型;
18、利用数据预设单位对第一数据单位标准化,得到第一标准数据。另一方面,根据数据类型标签分类处理得到不同类别的分类标准数据,包括:
19、基于数据类型历史库,提取所有第一数据类型,和所有第一数据的数据类型标签进行相似度匹配;
20、其中,sym表示任一第一数据的数据类型标签和任一第一数据类型的相似度,xk表示所述第一数据的数据标签的数据语义系数,由数据名称-语义系数映射表确定,xk0表示所述第一数据类型的数据语义系数,x0表示预设标准数据语义系数,e()表示最低相似度函数,δ1表示距离相似比例系数,δ2表示字符相似比例系数,d()表示字符距离转换函数;
21、将相似度最高的第一数据类型作为簇中心,将所述数据标签作为分类数据类型标签,将分类数据类型标签对应的所有数据作为子数据,形成所述类别下的分类标准数据。
22、另一方面,根据分类标准数据,基于标准分类库进行特征选择,
23、得到不同分类标签对应的特征数据,包括:
24、从标准分类库中导入预定义的特征选择标准,其中,所述特征选择标准包含与各个分类标签对应的重要特征列表;
25、根据每个分类标签,根据标准分类库提取对应的所有重要特征,将所述重要特征作为样例特征,和对应分类标签的所述分类标准数据进行特征提取,得到子特征,并且评估不同子特征的对所述分类标签的贡献值,筛选出高于预设贡献值的特征,组合这些特征形成新的特征数据,得到所述分类标签对应的特征数据。
26、另一方面,将特征数据划分为测试集,将分类标准数据划分为训练集,利用机器学习算法构建血液透析大数据模型,包括:
27、根据预设配置算法参数,利用随机森林算法,对训练集的特征数据和对应分类标签进行模型训练;
28、对训练集进行迭代训练,得到第一模型性能指标;
29、和预设模型性能指标对比,调整配置算法参数,二次利用随机森林算法训练训练集,得到第二模型性能指标;
30、将测试集数据代入第二模型性能指标下的血液透析大数据模型上,得到关键因子,利用关键因子和第二模型性能指标的拟合度,调整模型参数,得到第三模型性能指标;
31、利用所述第三模型性能指标构建血液透析大数据模型。
32、另一方面,利用血液透析历史数据对血液透析大数据模型进行验证,并根据验证结果调整血液透析大数据模型的参数完成模型优化,包括:
33、利用血液透析历史数据,反向验证血液透析大数据模型,获取血液透析大数据模型的验证结果;
34、将所述验证结果和目标验证结果做对比,得到所述血液透析大数据模型的超参数,利用高斯过程对超参数对应的代理函数进行迭代调整,其中所述高斯过程参数由协方差函数结合血液透析历史数据指定;
35、将优化后的血液透析大数据模型部署到生产环境中,用于实际的预测任务;
36、实时监控血液透析大数据模型的预测性能,检测模型预测性能是否满足预设标准。
37、本发明提供一种基于多中心的血液透析大数据模型构建方法,用以通过获取多中心血液透析的数据,集合到数据原始库中,之后根据数据类型标签筛选并处理原始数据,得到分类标准数据,之后提取分类标准数据特征数据作为测试集,分类标准数据划为训练集,完成对血液透析大数据模型的构建和训练。
技术特征:
1.一种基于多中心的血液透析大数据模型构建方法,其特征在于,包括:
2.根据权利要求1所述的一种基于多中心的血液透析大数据模型构建方法,其特征在于,收集来自多个血液透析中心的血液基本数据,包括:
3.根据权利要求2所述的一种基于多中心的血液透析大数据模型构建方法,其特征在于,存储到数据原始库中,包括:
4.根据权利要求1所述的一种基于多中心的血液透析大数据模型构建方法,其特征在于,对数据原始库中的原始数据进行预处理和标准化,得到第一标准数据,包括:
5.根据权利要求4所述的一种基于多中心的血液透析大数据模型构建方法,其特征在于,根据数据类型标签分类处理得到不同类别的分类标准数据,包括:
6.根据权利要求1所述的一种基于多中心的血液透析大数据模型构建方法,其特征在于,根据分类标准数据,基于标准分类库进行特征选择,得到不同分类标签对应的特征数据,包括:
7.根据权利要求1所述的一种基于多中心的血液透析大数据模型构建方法,其特征在于,将特征数据划分为测试集,将分类标准数据划分为训练集,利用机器学习算法构建血液透析大数据模型,包括:
8.根据权利要求1所述的一种基于多中心的血液透析大数据模型构建方法,其特征在于,利用血液透析历史数据对血液透析大数据模型进行验证,并根据验证结果调整血液透析大数据模型的参数完成模型优化,包括:
技术总结
本发明提供一种基于多中心的血液透析大数据模型构建方法,属于模型构建技术领域;收集来自多个血液透析中心的血液基本数据,存储到数据原始库中;对数据原始库中的原始数据进行预处理和标准化,得到第一标准数据,并根据数据类型标签分类处理得到不同类别的分类标准数据;根据分类标准数据,基于标准分类库进行特征选择,得到不同分类标签对应的特征数据;将特征数据划分为测试集,将分类标准数据划分为训练集,利用机器学习算法构建血液透析大数据模型;利用血液透析历史数据对血液透析大数据模型进行验证,并根据验证结果调整血液透析大数据模型的参数完成模型优化。保证了大数据模型构建的准确性,提高对血液透析数据的分析效果。
技术研发人员:边学燕,吴斌,罗春雷,李国辉,杨帆,胡月
受保护的技术使用者:宁波大学附属第一医院
技术研发日:
技术公布日:2024/10/31
- 还没有人留言评论。精彩留言会获得点赞!