基于机器学习的蛋白冠上蛋白质相对丰度的预测方法及系统
本发明涉及生物检测,特别是涉及一种基于机器学习的蛋白冠上蛋白质相对丰度的预测方法及系统。
背景技术:
1、纳米粒子体积小,具有多种独特的特性,对包括医学在内的许多技术领域的发展产生了深远的影响。这些纳米粒子非常小,几乎可以进入人体的所有部位。这促使人们开发出一种新的医学方法,即纳米医学。纳米粒子进入生物液体后,会与一系列生物聚合物(包括蛋白质)相互作用,这些聚合物会与纳米粒子结合,形成与纳米粒子相关的“蛋白冠”。蛋白冠的形成可视为纳米粒子与蛋白质之间的相互作用。纳米材料的这种表面“生物转化”会以一种难以预测的方式改变其整体药理和毒理特性及其潜在的治疗或诊断功能。透彻了解蛋白冠的组成及其与纳米粒子的相互作用对于评估其生物效应和在生物医学中的潜在应用至关重要。蛋白冠组成是指冠中蛋白质总量的相对蛋白质丰度(rpa),是描述蛋白冠的重要参数。使用人工智能来建立预测模型可以快速表征蛋白质的吸附行为和蛋白冠的形成。迄今为止,许多因素(如纳米粒子的物理化学特性、孵育和分离条件)都被证明会影响蛋白冠的生物反应和组成,机器学习算法非常适合从这些因素中提取关键信息,从而准确预测蛋白冠的组成。机器学习的应用可以提高蛋白冠研究的广度和深度,可以使蛋白冠的成分分析变得更加便利,可见机器学习在蛋白质冠相关预测领域具有巨大潜力。
2、当前,大部分蛋白冠组成成分研究是基于液相色谱-质谱(lc-ms/ms)来获取蛋白冠上的组成成分信息,也有少部分使用机器学习中随机森林算法来做分类或者回归分析,对蛋白冠上的蛋白质相对丰度进行预测。然而,基于液相色谱-质谱(lc-ms/ms)的分析技术昂贵且耗时;基于随机森林的预测相对简单,并没有挖掘出更深层次的重要特征信息。目前,使用机器学习对rpa的预测较为单一,通过简单的回归分析或分类预测来对rpa进行预测,并不能全面给出rpa的预测结果,其预测性能还有待提高。
技术实现思路
1、基于此,为了解决上述技术问题,提供一种基于机器学习的蛋白冠上蛋白质相对丰度的预测方法及系统,可以提高蛋白质相对丰度的预测性能。
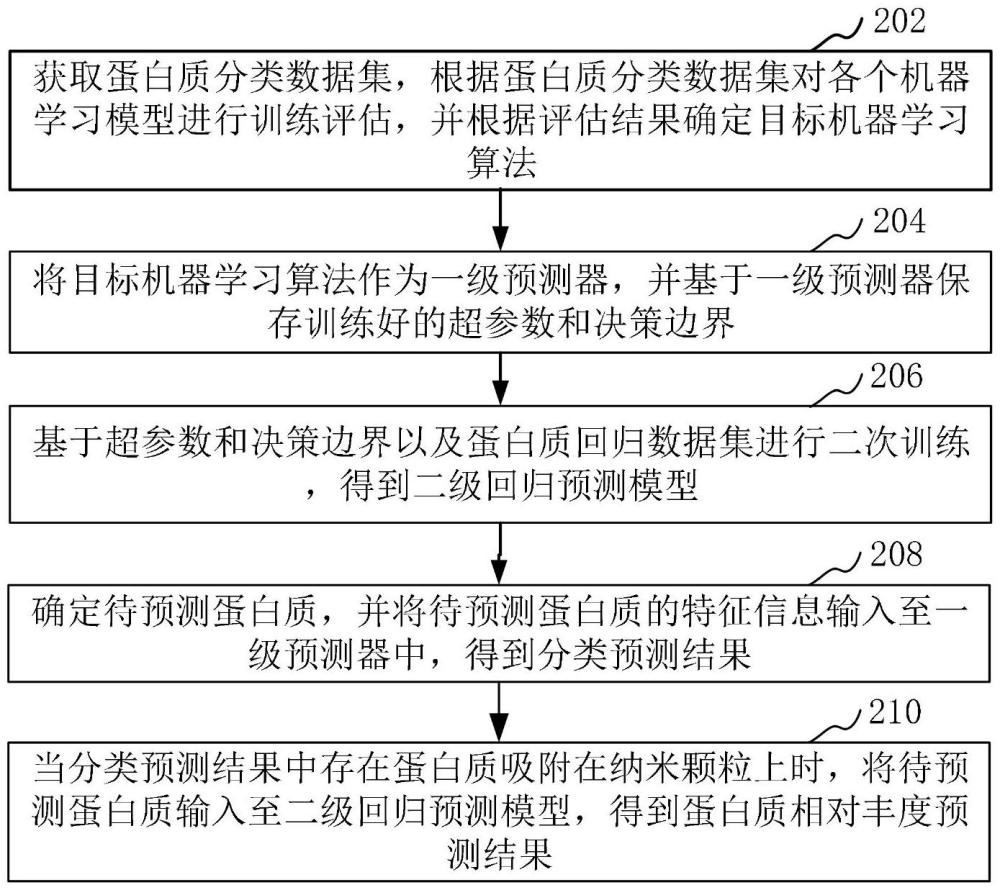
2、一种基于机器学习的蛋白冠上蛋白质相对丰度的预测方法,所述方法包括:
3、获取蛋白质分类数据集,根据所述蛋白质分类数据集对各个机器学习模型进行训练评估,并根据评估结果确定目标机器学习算法;
4、将所述目标机器学习算法作为一级预测器,并基于所述一级预测器保存训练好的超参数和决策边界;
5、基于所述超参数和决策边界以及蛋白质回归数据集进行二次训练,得到二级回归预测模型;
6、确定待预测蛋白质,并将所述待预测蛋白质的特征信息输入至所述一级预测器中,得到分类预测结果;
7、当所述分类预测结果中存在蛋白质吸附在纳米颗粒上时,将所述待预测蛋白质输入至所述二级回归预测模型,得到蛋白质相对丰度预测结果。
8、在其中一个实施例中,所述根据所述蛋白质分类数据集对各个机器学习模型进行训练评估,包括:
9、将所述蛋白质分类数据集分为蛋白质分类训练集、蛋白质分类测试集;
10、基于所述蛋白质分类训练集、蛋白质分类测试集分别对极随机树、随机森林、梯度提升决策树、xgboost、lightgbm、神经网络进行训练评估,并得到各个评估结果。
11、在其中一个实施例中,根据评估结果确定目标机器学习算法,包括:
12、根据各个所述评估结果,从所述极随机树、随机森林、梯度提升决策树、xgboost、lightgbm、神经网络中,将所述极随机树确定为目标机器学习算法。
13、在其中一个实施例中,所述基于所述超参数和决策边界以及蛋白质回归数据集进行二次训练,得到二级回归预测模型,包括:
14、获取蛋白质回归数据集,并将所述蛋白质回归数据集划分为蛋白质回归训练集、蛋白质回归测试集;
15、基于所述蛋白质回归训练集、蛋白质回归测试集,将所述超参数和决策边界迁移到所述蛋白质回归数据集中进行二次训练,得到二级回归预测模型。
16、在其中一个实施例中,所述确定待预测蛋白质,包括:
17、获取若干蛋白质单体,并从若干所述蛋白质单体中选择一个蛋白质单体作为所述待预测蛋白质;
18、提取所述待预测蛋白质中的定性特征、定量特征,并将所述定性特征、定量特征作为所述待预测蛋白质的特征信息。
19、在其中一个实施例中,所述方法还包括:
20、对所述待预测蛋白质的特征信息进行归一化处理,得到处理后的特征信息。
21、在其中一个实施例中,所述将所述待预测蛋白质的特征信息输入至所述一级预测器中,得到分类预测结果,包括:
22、将所述处理后的特征信息输入至所述一级预测器中,通过所述一级预测器预测所述待预测蛋白质是否吸附在纳米颗粒上;
23、将所述待预测蛋白质吸附在纳米颗粒上作为第一分类预测结果;
24、将所述待预测蛋白质未吸附在纳米颗粒上作为第二分类预测结果。
25、在其中一个实施例中,所述方法还包括:
26、当所述分类预测结果为所述第二分类预测结果时,无需将所述待预测蛋白质输入至所述二级回归预测模型,结束蛋白冠上蛋白质相对丰度的预测。
27、一种基于机器学习的蛋白冠上蛋白质相对丰度的预测系统,所述系统包括:
28、算法评估确定模块,用于获取蛋白质分类数据集,根据所述蛋白质分类数据集对各个机器学习模型进行训练评估,并根据评估结果确定目标机器学习算法;
29、数据保存模块,用于将所述目标机器学习算法作为一级预测器,并基于所述一级预测器保存训练好的超参数和决策边界;
30、二次训练模块,用于基于所述超参数和决策边界以及蛋白质回归数据集进行二次训练,得到二级回归预测模型;
31、分类预测模块,用于确定待预测蛋白质,并将所述待预测蛋白质的特征信息输入至所述一级预测器中,得到分类预测结果;
32、蛋白质相对丰度预测模块,用于当所述分类预测结果中存在蛋白质吸附在纳米颗粒上时,将所述待预测蛋白质输入至所述二级回归预测模型,得到蛋白质相对丰度预测结果。
33、上述基于机器学习的蛋白冠上蛋白质相对丰度的预测方法及系统,通过对多种机器学习算法进行评估,选择出最优的一级预测器,然后基于迁移思想,将一级分类训练中得到的最优超参数和最优决策边界迁移到回归数据集中进行二次训练从而构建出完整的二级回归预测模型,二级回归任务是在一级分类任务的基础上进行,可减少一定的训练时间;将分类与回归相结合可以实现对蛋白冠上蛋白质相对丰度的全面预测,在预测吸附与否的基础上可以进一步预测出蛋白冠上蛋白质相对丰度的具体值,提高了蛋白质相对丰度的预测性能。
技术特征:
1.一种基于机器学习的蛋白冠上蛋白质相对丰度的预测方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于机器学习的蛋白冠上蛋白质相对丰度的预测方法,其特征在于,所述根据所述蛋白质分类数据集对各个机器学习模型进行训练评估,包括:
3.根据权利要求2所述的基于机器学习的蛋白冠上蛋白质相对丰度的预测方法,其特征在于,根据评估结果确定目标机器学习算法,包括:
4.根据权利要求1所述的基于机器学习的蛋白冠上蛋白质相对丰度的预测方法,其特征在于,所述基于所述超参数和决策边界以及蛋白质回归数据集进行二次训练,得到二级回归预测模型,包括:
5.根据权利要求1所述的基于机器学习的蛋白冠上蛋白质相对丰度的预测方法,其特征在于,所述确定待预测蛋白质,包括:
6.根据权利要求1所述的基于机器学习的蛋白冠上蛋白质相对丰度的预测方法,其特征在于,所述方法还包括:
7.根据权利要求6所述的基于机器学习的蛋白冠上蛋白质相对丰度的预测方法,其特征在于,所述将所述待预测蛋白质的特征信息输入至所述一级预测器中,得到分类预测结果,包括:
8.根据权利要求7所述的基于机器学习的蛋白冠上蛋白质相对丰度的预测方法,其特征在于,所述方法还包括:
9.一种基于机器学习的蛋白冠上蛋白质相对丰度的预测系统,其特征在于,所述系统包括:
10.根据权利要求9所述的基于机器学习的蛋白冠上蛋白质相对丰度的预测系统,其特征在于,所述算法评估确定模块,还用于:将所述蛋白质分类数据集分为蛋白质分类训练集、蛋白质分类测试集;基于所述蛋白质分类训练集、蛋白质分类测试集分别对极随机树、随机森林、梯度提升决策树、xgboost、lightgbm、神经网络进行训练评估,并得到各个评估结果。
技术总结
本发明涉及一种基于机器学习的蛋白冠上蛋白质相对丰度的预测方法及系统。所述方法包括:对各个机器学习模型进行训练评估确定一级预测器,并保存训练好的超参数和决策边界;基于超参数和决策边界以及蛋白质回归数据集进行二次训练,得到二级回归预测模型;将待预测蛋白质的特征信息输入至一级预测器中,得到分类预测结果;当分类预测结果中存在蛋白质吸附在纳米颗粒上时,将待预测蛋白质输入至二级回归预测模型,得到蛋白质相对丰度预测结果。二级回归任务是在一级分类任务的基础上进行,可减少训练时间;将分类与回归相结合可以实现对蛋白冠上蛋白质相对丰度的全面预测,提高了蛋白质相对丰度的预测性能。
技术研发人员:崔菲菲,付修豪,张子龙
受保护的技术使用者:海南大学
技术研发日:
技术公布日:2024/10/28
- 还没有人留言评论。精彩留言会获得点赞!