模型训练方法、行动策略制定方法、服务器及存储介质与流程
本申请涉及人工智能,尤其涉及一种模型训练方法、智能体的行动策略制定方法、服务器及存储介质。
背景技术:
1、随着人工智能(artificial intelligence,ai)技术的快速发展,人工智能技术被广泛应用于3d游戏、虚拟交通、自动驾驶仿真、机器人轨迹规划等各个领域,在3d虚拟空间中进行ai仿真具有非常大的商业价值,如通过人工智能技术可以实现各类游戏中智能体与真人之间的对局。
2、目前,在部分3d虚拟空间的ai仿真中,智能体需要在3d虚拟空间中进行地图探索、收集各种资源,并在虚拟空间中对抗其他智能体玩家,让自己生存到最后,在这个ai仿真过程中,智能体需要在不同的环境中做出正确行动决策,以使自己以相对安全区域为目标点进行转移与探索,并可以与敌方智能体战斗从而使自己生存到最后。
3、因此,为了增强用户的游戏体验,在ai仿真中我们希望智能体高度拟人化,故,如何实现高度拟人化的ai仿真成为了亟需解决的问题。
技术实现思路
1、本申请实施例提供一种模型训练方法、智能体的行动策略制定方法、服务器及存储介质,旨在实现高度拟人化的ai仿真。
2、第一方面,本申请实施例还提供了一种模型训练方法,所述方法包括:
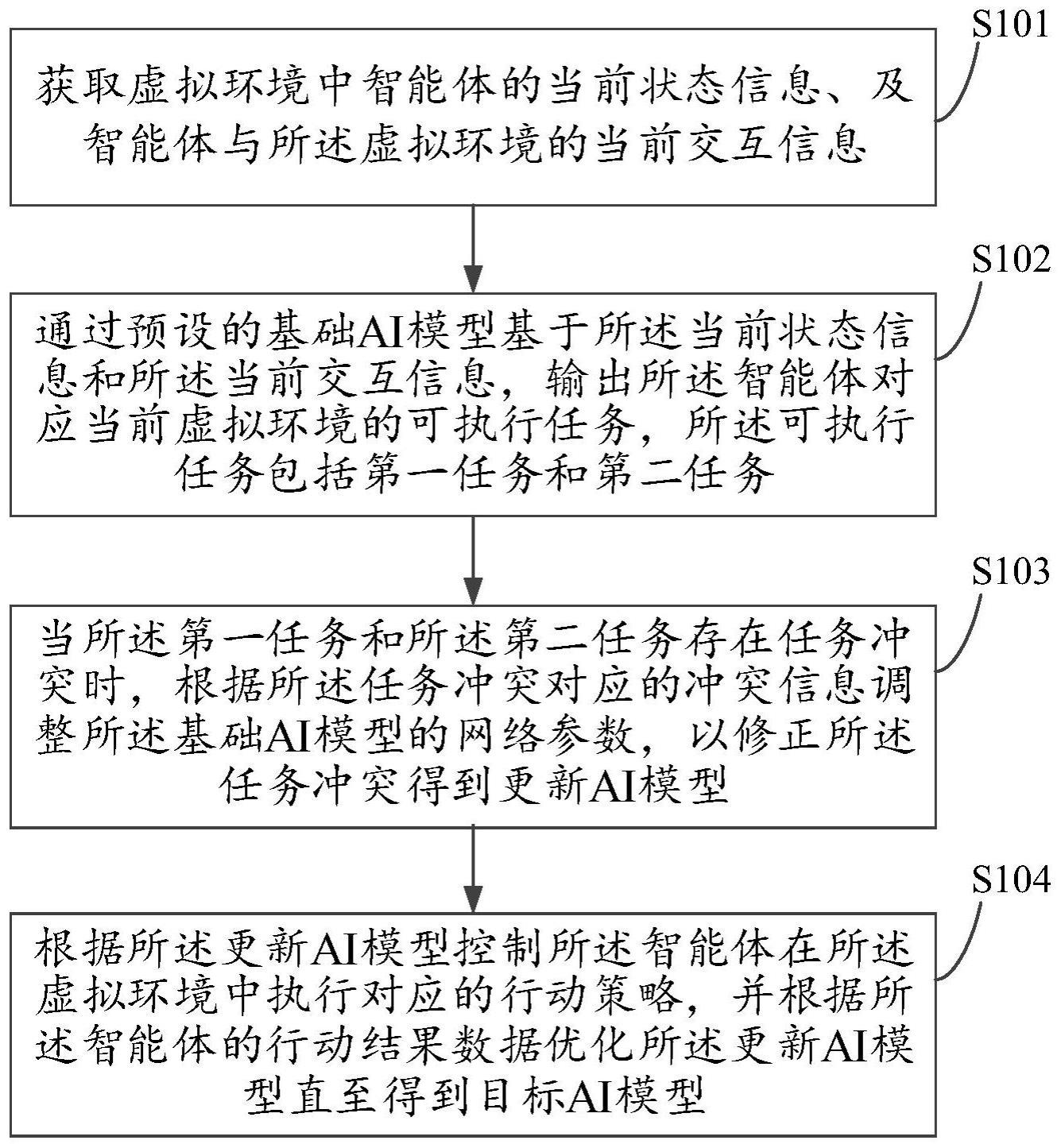
3、获取虚拟环境中智能体的当前状态信息、及智能体与所述虚拟环境的当前交互信息;
4、通过预设的基础ai模型基于所述当前状态信息和所述当前交互信息,输出所述智能体对应当前虚拟环境的可执行任务,所述可执行任务包括第一任务和第二任务;
5、判断所述第一任务和所述第二任务是否存在任务冲突,当所述第一任务和所述第二任务存在任务冲突时,根据所述任务冲突对应的冲突信息调整所述基础ai模型的网络参数,以修正所述任务冲突得到更新ai模型;
6、根据所述更新ai模型控制所述智能体在所述虚拟环境中执行对应的行动策略,并根据所述智能体的行动结果数据优化所述更新ai模型直至得到目标ai模型。
7、第二方面,本申请实施例提供了一种智能体的行动策略制定方法,所述方法包括:
8、获取虚拟环境中智能体的当前状态信息、及智能体与所述虚拟环境的当前交互信息;
9、通过预设的基础ai模型基于所述当前状态信息和所述当前交互信息,输出所述智能体对应当前虚拟环境的可执行任务,所述可执行任务包括第一任务和第二任务;
10、判断所述第一任务和所述第二任务是否存在任务冲突,当所述第一任务和所述第二任务存在任务冲突时,根据所述任务冲突对应的冲突信息调整所述基础ai模型的网络参数,以修正所述任务冲突得到更新ai模型;
11、根据所述更新ai模型控制所述智能体在所述虚拟环境中执行对应的行动策略。
12、第三方面,本申请实施例还提供了一种服务器,所述服务器包括处理器、存储器;所述存储器存储有可以被所述处理器调用并执行的计算机程序,其中,所述计算机程序被所述处理器执行时,实现上述的智能体的行动策略制定方法或模型的训练方法。
13、第四方面,本申请实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序被处理器执行时使所述处理器实现上述的智能体的行动策略制定方法或模型的训练方法。
14、本申请实施例提供了一种模型的训练方法、智能体的行动策略制定方法服务器及存储介质,在一实施方式中,模型的训练方法通过获取虚拟环境中智能体的当前状态信息、及智能体与所述虚拟环境的当前交互信息;通过预设的基础ai模型基于所述当前状态信息和所述当前交互信息,输出所述智能体对应当前虚拟环境的可执行任务,所述可执行任务包括第一任务和第二任务;判断所述第一任务和所述第二任务是否存在任务冲突,当所述第一任务和所述第二任务存在任务冲突时,根据所述任务冲突对应的冲突信息调整所述基础ai模型的网络参数,以修正所述任务冲突得到更新ai模型;根据所述更新ai模型控制所述智能体在所述虚拟环境中执行对应的行动策略,并根据所述智能体的行动结果数据优化所述更新ai模型直至得到目标ai模型。
15、基于在虚拟游戏环境中,智能体可以执行不同的任务,然而,不同的任务之间可能存在互相促进部分,也同样存在互相冲突,本申请实施方式中,在监测到智能体所执行的多个任务中,存在两个相互冲突的任务时,调整控制智能体行动的基础ai模型的网络参数,使得智能体在虚拟环境中所输出的动作更为合理、更具人性化。
技术特征:
1.一种模型训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述智能体在执行不同的任务过程中,所述基础ai模型输出对应的任务梯度数据,所述判断所述第一任务和所述第二任务是否存在任务冲突,包括:
3.根据权利要求2所述的方法,其特征在于,所述第一任务梯度数据对应第一任务梯度方向,所述第二任务梯度数据对应第二任务梯度方向,并且当所述第一任务梯度方向和所述第二任务梯度方向之间的夹角小于或等于预设角度时,所述第一任务和所述第二任务不存在任务冲突。
4.根据权利要求3所述的方法,其特征在于,所述根据所述第一任务梯度数据和所述第二任务梯度数据判断所述第一任务和所述第二任务是否存在任务冲突,包括:
5.根据权利要求4所述的方法,其特征在于,所述冲突信息包括所述第一任务梯度方向、所述第二任务梯度方向、及所述第一任务梯度方向和所述第二任务梯度方向的夹角。
6.根据权利要求5所述的方法,其特征在于,所述根据所述任务冲突对应的冲突信息调整所述基础ai模型的网络参数,以修正所述任务冲突得到更新ai模型,包括:
7.根据权利要求6所述的方法,其特征在于,所述预设角度为90°,所述以另一任务梯度方向为基准,调整所述目标任务梯度方向与另一任务梯度方向的夹角,包括:
8.一种智能体的行动策略制定方法,其特征在于,所述方法包括:
9.一种服务器,其特征在于,所述服务器包括处理器、存储器;所述存储器存储有可以被所述处理器调用并执行的计算机程序,其中,所述计算机程序被所述处理器执行时,实现如权利要求1至7中任一项所述的模型训练方法,或实现如权利要求8所述的智能体的行动策略制定方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时使所述处理器实现如权利要求1至7中任一项所述的模型训练方法,或实现如权利要求8所述的智能体的行动策略制定方法。
技术总结
本申请公开了一种模型训练方法、智能体的行动策略制定方法、服务器及存储介质,其中,模型训练方法包括:获取虚拟环境中智能体的当前状态信息、及智能体与虚拟环境的当前交互信息;通过预设的基础模型基于当前状态信息和当前交互信息,输出智能体对应当前虚拟环境的可执行的第一任务和第二任务;当第一任务和第二任务存在任务冲突时,根据任务冲突对应的冲突信息调整基础模型的网络参数,以修正任务冲突得到更新模型;根据更新模型控制智能体在虚拟环境中执行对应的行动策略,并根据智能体的行动结果数据优化更新模型得到目标模型,通过本申请所用的模型训练方法获取的AI模型可以控制智能体在虚拟环境中所输出的动作更为合理、更具人性化。
技术研发人员:陈嘉欣,陈翰墨,朱晓龙
受保护的技术使用者:超参数科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!