一种基于子空间感知的多智能体探索方法和设备
本发明涉及多智能体强化学习,尤其涉及一种基于子空间感知的多智能体探索方法和设备。
背景技术:
1、由于许多现实世界的任务都涉及多个智能体的交互,多智能体强化学习领域得到了越来越多研究者的关注。虽然该领域的进展显著,但研究者们大多聚焦于具有密集奖励的多智能体任务。然而,在许多现实世界的任务中,智能体能获得的任务奖励往往是极端稀疏的。为了应对奖励稀疏的场景,智能体必须具备探索环境的能力。研究表明,多智能体环境中巨大的状态空间严重限制了现有方法的性能,这是由于,在多智能体环境中,状态空间的大小随着智能体的数量的线性增加而指数增长。现有的多智能体探索方法无法细致的控制智能体的探索方向,从而浪费了大量的探索机会,导致了低效的探索。
技术实现思路
1、针对现有技术存在的问题,本发明提供一种基于子空间感知的多智能体探索方法和设备。
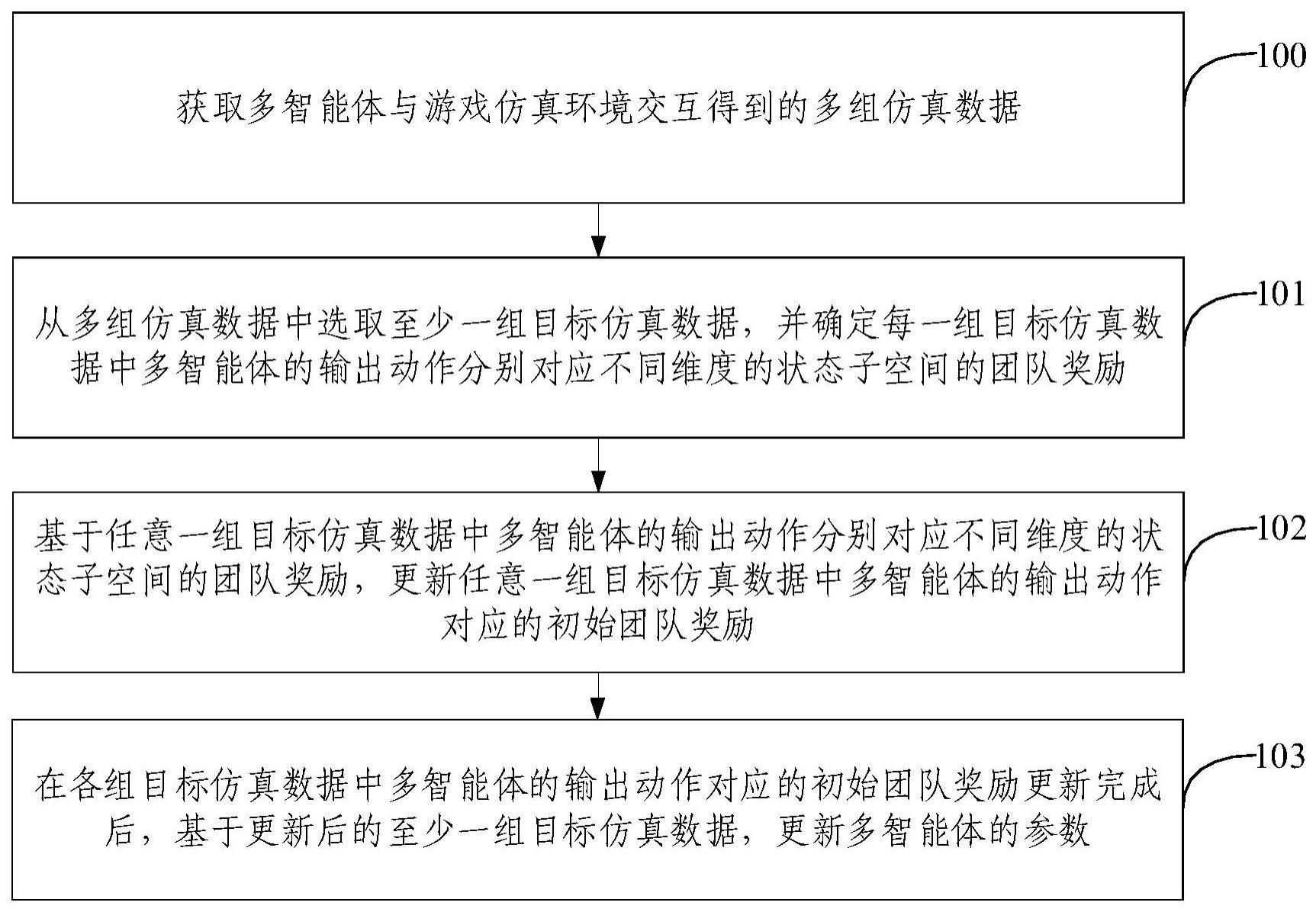
2、第一方面,本发明提供一种基于子空间感知的多智能体探索方法,应用于游戏人工智能训练场景,包括:
3、获取多智能体与游戏仿真环境交互得到的多组仿真数据,每一组仿真数据包括:第t时刻所述游戏仿真环境的状态、第t时刻所述多智能体的观测数据、第t时刻所述多智能体的输出动作、第t+1时刻所述游戏仿真环境的状态、所述第t时刻所述多智能体的输出动作对应的初始团队奖励,t为大于或者等于0的整数;
4、从所述多组仿真数据中选取至少一组目标仿真数据,并确定每一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励;
5、基于任意一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励,更新所述任意一组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励;
6、在各组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励更新完成后,基于更新后的所述至少一组目标仿真数据,更新所述多智能体的参数。
7、可选地,所述确定每一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励,包括:
8、基于所述每一组目标仿真数据中第t时刻所述多智能体的观测数据、第t时刻所述多智能体的输出动作和第t+1时刻所述游戏仿真环境的状态,确定所述每一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励。
9、可选地,所述每一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励基于以下公式确定:
10、be=(-logdπ(st+1,εe)-1)/((1+1/u(dπ,εe))log|εe|)
11、其中,be表示所述第t时刻所述多智能体的输出动作对应的任意一个维度的状态子空间的团队奖励,st+1表示第t+1时刻所述游戏仿真环境的状态,εe表示包含所述游戏仿真环境的所述任意一个维度的状态子空间,π表示以第t时刻所述多智能体的观测数据为输入,以第t时刻所述多智能体的输出动作为输出的策略,dπ(st+1,εe)表示给定策略π时,状态st+1在子空间εe的访问概率,u(dπ,εe)表示给定策略π时,子空间εe的不确定度,|εe|表示子空间εe的大小。
12、可选地,所述基于任意一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励,更新所述任意一组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励,包括:
13、基于所述任意一组目标仿真数据中所述多智能体的输出动作分别对应各个维度的状态子空间的团队奖励之和,更新所述任意一组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励。
14、可选地,所述基于所述任意一组目标仿真数据中所述多智能体的输出动作分别对应各个维度的状态子空间的团队奖励之和,更新所述任意一组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励,包括:
15、将第一乘积、所述任意一组目标仿真数据中所述第t时刻所述多智能体的输出动作对应的全空间的团队奖励、所述任意一组目标仿真数据中所述第t时刻所述多智能体的输出动作对应的初始团队奖励三者之和,作为更新后的所述任意一组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励;
16、其中,所述第一乘积为所述任意一组目标仿真数据中所述多智能体的输出动作分别对应各个维度的状态子空间的团队奖励之和与大于0的超参数的乘积。
17、可选地,所述任意一组目标仿真数据中所述第t时刻所述多智能体的输出动作对应的全空间的团队奖励,基于所述任意一组目标仿真数据中所述第t+1时刻所述游戏仿真环境的状态确定。
18、可选地,所述基于更新后的所述至少一组目标仿真数据,更新所述多智能体的参数,包括:
19、基于更新后的所述至少一组目标仿真数据,使用qmix算法更新所述多智能体的参数。
20、第二方面,本发明还提供一种基于子空间感知的多智能体探索装置,包括:
21、获取模块,用于获取多智能体与游戏仿真环境交互得到的多组仿真数据,每一组仿真数据包括:第t时刻所述游戏仿真环境的状态、第t时刻所述多智能体的观测数据、第t时刻所述多智能体的输出动作、第t+1时刻所述游戏仿真环境的状态、所述第t时刻所述多智能体的输出动作对应的初始团队奖励,t为大于或者等于0的整数;
22、确定模块,用于从所述多组仿真数据中选取至少一组目标仿真数据,并确定每一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励;
23、第一更新模块,用于基于任意一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励,更新所述任意一组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励;
24、第二更新模块,用于在各组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励更新完成后,基于更新后的所述至少一组目标仿真数据,更新所述多智能体的参数。
25、第三方面,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上所述第一方面所述的基于子空间感知的多智能体探索方法。
26、第四方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上所述第一方面所述的基于子空间感知的多智能体探索方法。
27、本发明提供的基于子空间感知的多智能体探索方法和设备,通过目标仿真数据中多智能体的输出动作分别对应不同维度的状态子空间的团队奖励更新目标仿真数据中智能体的输出动作对应的初始团队奖励,并根据更新后的目标仿真数据更新多智能体的参数,使得智能体的探索方向可以被控制,提高了多智能体的探索效率。
技术特征:
1.一种基于子空间感知的多智能体探索方法,应用于游戏人工智能训练场景,其特征在于,包括:
2.根据权利要求1所述的基于子空间感知的多智能体探索方法,其特征在于,所述确定每一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励,包括:
3.根据权利要求2所述的基于子空间感知的多智能体探索方法,其特征在于,所述每一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励基于以下公式确定:
4.根据权利要求1至3任一项所述的基于子空间感知的多智能体探索方法,其特征在于,所述基于任意一组目标仿真数据中所述多智能体的输出动作分别对应不同维度的状态子空间的团队奖励,更新所述任意一组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励,包括:
5.根据权利要求4所述的基于子空间感知的多智能体探索方法,其特征在于,所述基于所述任意一组目标仿真数据中所述多智能体的输出动作分别对应各个维度的状态子空间的团队奖励之和,更新所述任意一组目标仿真数据中所述多智能体的输出动作对应的初始团队奖励,包括:
6.根据权利要求5所述的基于子空间感知的多智能体探索方法,其特征在于,所述任意一组目标仿真数据中所述第t时刻所述多智能体的输出动作对应的全空间的团队奖励,基于所述任意一组目标仿真数据中所述第t+1时刻所述游戏仿真环境的状态确定。
7.根据权利要求1所述的基于子空间感知的多智能体探索方法,其特征在于,所述基于更新后的所述至少一组目标仿真数据,更新所述多智能体的参数,包括:
8.一种基于子空间感知的多智能体探索装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在所述存储器上并在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7任一项所述基于子空间感知的多智能体探索方法。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述基于子空间感知的多智能体探索方法。
技术总结
本发明提供一种基于子空间感知的多智能体探索方法和设备,该方法包括:获取多智能体与游戏仿真环境交互得到的多组仿真数据;从多组仿真数据中选取至少一组目标仿真数据,并确定每一组目标仿真数据中多智能体的输出动作分别对应不同维度的状态子空间的团队奖励;基于任意一组目标仿真数据中多智能体的输出动作分别对应不同维度的状态子空间的团队奖励,更新任意一组目标仿真数据中多智能体的输出动作对应的初始团队奖励;在各组目标仿真数据中多智能体的输出动作对应的初始团队奖励更新完成后,基于更新后的至少一组目标仿真数据,更新多智能体的参数,使得智能体的探索方向可以被控制,提高了多智能体的探索效率。
技术研发人员:张俊格,黄凯奇,徐沛
受保护的技术使用者:中国科学院自动化研究所
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!