一种基于深度强化学习的机械臂容错避障方法
本发明属于机械臂控制,具体涉及一种基于深度强化学习的机械臂容错避障方法。
背景技术:
1、特殊环境下,如核环境,工作场景中经常会包含一些障碍物,需要机械臂在避障的前提下进行工作。由于长时间受到辐射影响,增加了机械臂出现各种故障的可能性,如果强行让故障机械臂工作,无法按照原始规定的路径进行运动,甚至可能导致灾难性的后果。因此需要智能容错控制系统,对容错性能进行评估,重新规划安全路径,并确保机械臂能够在故障后跟踪路径,安全执行未完成的任务。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的基于深度强化学习的机械臂容错避障方法解决了现有的无法在未知故障情况下进行机械臂的容错避障控制的问题。
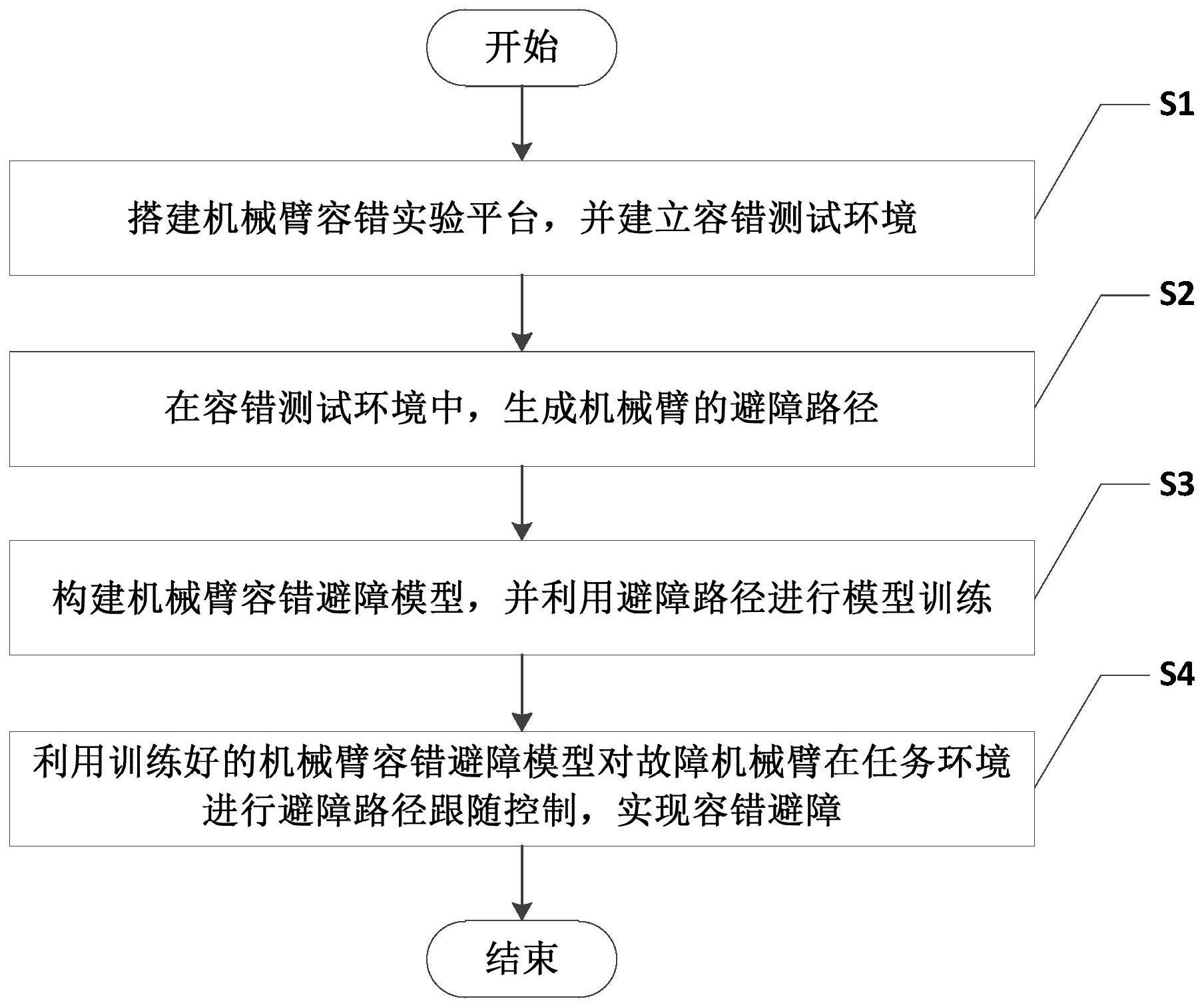
2、为了达到上述发明目的,本发明采用的技术方案为:一种基于深度强化学习的机械臂容错避障方法,包括以下步骤:
3、s1、搭建机械臂容错实验平台,并建立容错测试环境;
4、s2、在容错测试环境中,生成机械臂的避障路径;
5、s3、构建机械臂容错避障模型,并利用避障路径进行模型训练;
6、s4、利用训练好的机械臂容错避障模型对故障机械臂在任务环境进行避障路径跟随控制,实现容错避障。
7、进一步地,所述步骤s1中,在机械臂容错实验平台中,将oxyz坐标系设为机械臂所在的三维空间坐标系,其中o表示机械臂运动区域中心,x轴指向正北方向,z轴指向正东方向,y轴指向垂直向上的方向;
8、所述步骤s1中,建立容错测试环境的方法为:在机械臂所在的三维空间中,随机故障关节及其故障角度,并随机摆放障碍物及设定目标任务位置。
9、进一步地,所述步骤s2具体为:
10、s21、在容错测试环境中,利用蒙特卡洛法随机生成机械臂目标任务的n个末端可达点作为工作空间点,并记录各工作空间点的角度信息,形成初始工作空间;
11、s22、将初始工作空间栅格化为等距的网格;
12、s23、对各网格中的工作空间点位置进行加密,进而生成工作空间ftw;
13、s24、确定工作空间ftw中可达空间网格的可操作度;
14、其中,在工作空间ftw的栅格化网格中,将工作空间点数为零的网格作为不可达空间网格,剩余网格作为可达空间网格,并将包含可操作度的可达空间网格作为机械臂的容错工作空间mftw;
15、s25、遍历各可达空间网格,将当前可达空间网格的可操作度代入网格代价函数中,计算当前可达空间网格的代价值;
16、s26、确定当前可达空间网格下周围网格的代价值,将最小代价值对应的周围可达空间网格作为当前可达空间网格路径下的下一可达空间网格,进而生成机械臂的避障路径。
17、进一步地,所述步骤s23中,将工作空间点数小于设定精度阈值且不为零的网格内部工作空间点数进行加密。
18、进一步地,所述步骤s24中,可达空间网格的可操作性度sm的计算公式为:
19、
20、式中,mwi表示第m个可达空间网格中第i个点的可操作度,mji表示第m个可达空间网格当前角度下的雅克比矩阵,bcube为工作空间ftw的栅格化网格数量。
21、进一步地,所述步骤s25中,网格代价函数的表达式为:
22、fftw(m)=k1g(m)+k2h(m)+k3c(sm)
23、式中,fftw(m)为第m个可达空间网格的代价值,g(m)为从初始可达空间网格到当前可达空间网格的代价,h(m)为从当前可达空间网格到目标可达空间网格的代价,c(sm)为网格的可操作度能力,k1=1,k2=5,k3=0.2分别为g(m)、h(m)和c(sm)的系数;其中,g(m)=|xinit-xm|+|yinit-ym|+|zinit-zm|,h(m)=|xtar-xm|+|ytar-ym|+|ztar-zm|,(xm,ym,zm)为当前点的三维坐标,(xinit,yinit,zinit)为初始点的三维坐标,(xtar,ytar,ztar)为目标点的三维坐标。
24、进一步地,所述步骤s26具体为:
25、s26-1、将根据当前可达空间网格路径下的下一可达空间网格确定的路径作为机械臂的初始避障路径;
26、s26-2、通过贝塞尔曲线对生成的初始路径进行平滑处理,并将初始路径中的拐点进行多次平滑处理,进而生成机械臂的避障路径。
27、进一步地,所述步骤s3中的容错避障模型为基于深度强化学习的sac算法模型,其状态空间s为:
28、s=(p1,p2,p3)
29、式中,p1=(x1,y1,z1)为机械臂末端执行器的位置,p2=(x2,y2,z2)为操作对象的位置,p3=(x3,y3,z3)为避障路径中目标任务点的位置。
30、进一步地,所述sac算法模型的奖励函数r包括密集奖励和稀疏奖励;
31、其中,密集奖励rdense为:
32、rdense=-w1×rdist
33、式中,w1为密集奖励权重,rdist为机械臂执行器末端与目标任务位置之间的欧式距离,
34、稀疏奖励r2为:
35、r2=w2rsparce-w3rjacobi
36、式中,rsparce为判断机械臂末端与目标坐标距离产生的奖励,rjacobi为可操作椭球大小,w2和w3分别为rsparce和rjacobi的权重,j为末端姿态对应的雅克比矩阵。
37、进一步地,所述步骤s4中,在利用机械臂容错避障模型对故障机械臂在任务环境进行避障路径跟随控制时,根据机械臂当前故障状态,将机械臂执行器末端的目标点随机生成在可操作度大于0.5的位置。
38、本发明的有益效果为:
39、(1)本发明方法解决现有无法在未知故障情况下机械臂的容错控制,提高算法控制效率,增强机械臂作业的智能性,实现机械臂在出现未知故障时,自主判断任务的可行性,通过容错控制,仍能够继续完成当前任务。
40、(2)相对传统控制方法不用编写固定的执行代码,可根据实际情况灵活调整机械臂执行器的避障执行方式。
41、(3)本发明方法能够克服传统容错控制的缺点及不足,在不需要故障的准确信息的前提下能够实现机械臂的容错避障控制,并且针对不同机械臂的容错控制系统,移植性强,范用性广。
42、(4)本发明方法对研究出更智能、更高级和更符合人类需求的智能机器人具有一定现实意义。
技术特征:
1.一种基于深度强化学习的机械臂容错避障方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于深度强化学习的机械臂容错避障方法,其特征在于,所述步骤s1中,在机械臂容错实验平台中,将oxyz坐标系设为机械臂所在的三维空间坐标系,其中o表示机械臂运动区域中心,x轴指向正北方向,z轴指向正东方向,y轴指向垂直向上的方向;
3.根据权利要求2所述的基于深度强化学习的机械臂容错避障方法,其特征在于,所述步骤s2具体为:
4.根据权利要求3所述的基于深度强化学习的机械臂容错避障方法,其特征在于,所述步骤s23中,将工作空间点数小于设定精度阈值且不为零的网格内部工作空间点数进行加密。
5.根据权利要求3所述的基于深度强化学习的机械臂容错避障方法,其特征在于,所述步骤s24中,可达空间网格的可操作性度sm的计算公式为:
6.根据权利要求3所述的基于深度强化学习的机械臂容错避障方法,其特征在于,所述步骤s25中,网格代价函数的表达式为:
7.根据权利要求3所述的基于深度强化学习的机械臂容错避障方法,其特征在于,所述步骤s26具体为:
8.根据权利要求3所述的基于深度强化学习的机械臂容错避障方法,其特征在于,所述步骤s3中的容错避障模型为基于深度强化学习的sac算法模型,其状态空间s为:
9.根据权利要求8所述的基于深度强化学习的机械臂容错避障方法,其特征在于,所述sac算法模型的奖励函数r包括密集奖励和稀疏奖励;
10.根据权利要求3所述的基于深度强化学习的机械臂容错避障方法,其特征在于,所述步骤s4中,在利用机械臂容错避障模型对故障机械臂在任务环境进行避障路径跟随控制时,根据机械臂当前故障状态,将机械臂执行器末端的目标点随机生成在可操作度大于0.5的位置。
技术总结
本发明公开了一种基于深度强化学习的机械臂容错避障方法,包括:S1、搭建机械臂容错实验平台,并建立容错测试环境;S2、在容错测试环境中,生成机械臂的避障路径;S3、构建机械臂容错避障模型,并利用避障路径进行模型训练;S4、利用训练好的机械臂容错避障模型对故障机械臂在任务环境进行避障路径跟随控制,实现容错避障。本发明方法解决现有无法在未知故障情况下机械臂的容错控制,提高算法控制效率,增强机械臂作业的智能性,实现机械臂在出现未知故障时,自主判断任务的可行性,通过容错控制,仍能够继续完成当前任务。
技术研发人员:刘满禄,张兴浪,王姮,张华,周建,刘宏伟,张静,霍建文,钱卫民,张清波
受保护的技术使用者:西南科技大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!