一种基于深度强化学习的四足机器人运动控制方法
本发明涉及四足机器人运动控制领域,特别是涉及一种基于深度强化学习的四足机器人运动控制方法。
背景技术:
1、深度强化学习在机器人控制领域的发展现状备受关注。通过端到端学习,深度强化学习整合了感知和决策过程,简化了控制系统的复杂性,提高了整体性能。其模型无关性使得系统更具灵活性和适应性,能够实现实时决策和动态调整,以适应复杂环境。此外,深度强化学习还可以通过迁移学习加速新任务的学习过程,提高机器人的应用能力。总体而言,深度强化学习为实现智能化、自主化的机器人系统提供了强大支持,其不断创新和拓展将在未来机器人控制领域发挥重要作用。
2、专利cn 114626505 a提供了一种移动机器人深度强化学习控制方法。然而该技术采用单网络训练容易产生过估计偏差,同时没有引入噪声变量,使得应对环境变化的能力较差。基于上述问题,本发明提出了一种基于深度强化学习的四足机器人运动控制方法,以解决此类问题。
技术实现思路
1、为了克服现有技术的不足,本发明的目的是提供一种基于深度强化学习的四足机器人运动控制方法,降低过估计偏差的概率,增强四足机器人应对环境变化的能力。
2、为实现上述目的,本发明提供了如下方案:
3、一种基于深度强化学习的四足机器人运动控制方法,包括:
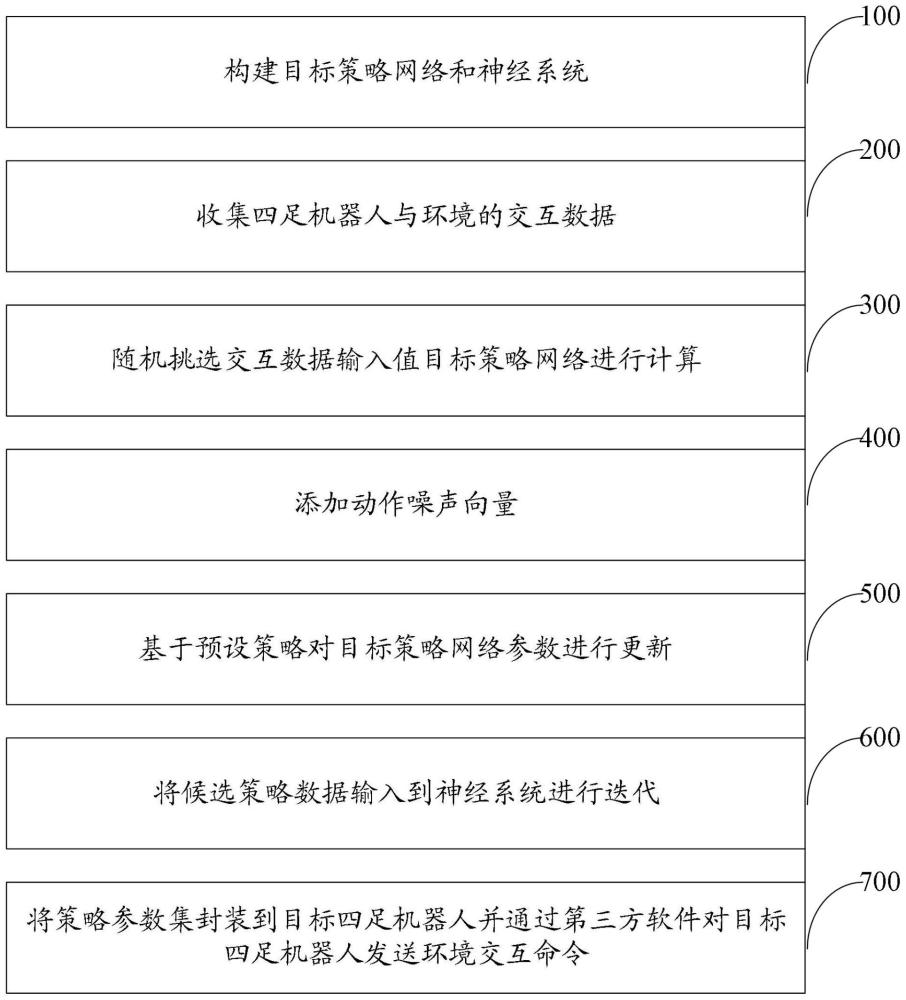
4、构建目标策略网络和神经系统;所述神经系统包括第一神经网络和第二神经网络;
5、确定目标网络值;
6、收集四足机器人与环境的交互数据,得到经验转移数据,并将所述经验转移数据保存到经验回放缓冲区;
7、在所述经验回放缓冲区中随机采样一组原始经验数据,将所述经验数据输入到所述目标策略网络中,得到预备动作数据和预备状态数据;
8、生成一个与动作维度相同的噪声向量;
9、将所述噪声向量添加到所述预备动作数据上,得到带有噪声的动作数据;
10、基于动作数据预设范围,对所述带有噪声的动作数据进行优化,得到优化的噪声动作数据;
11、将所述优化的噪声动作数据和所述预备状态数据组合,得到候选策略数据;
12、基于双重深度确定性策略梯度内置的策略网络更新策略,计算所述目标策略网络的梯度,并根据得到的梯度使用梯度下降法来更新所述目标策略网络的参数;
13、将所述候选策略数据分别输入所述第一神经网络和所述第二神经网络进行计算,分别得到第一网络值和第二网络值;
14、选择所述第一网络值和所述第二网络值的较小者,得到中间网络值;
15、计算所述目标网络值与所述中间网络值的损失函数,得到损失数据;
16、基于所述损失数据利用所述双重深度确定性策略梯度内置的奖励机制对所述第一神经网络和所述第二神经网络的参数进行更新;
17、判断所述目标策略网络的参数、所述第一神经网络的参数和所述第二神经网络的参数是否收敛,若是,则停止更新并输出策略参数集,若否,则返回所述收集四足机器人与环境的交互数据;所述策略参数集包括:更新完成的所述目标策略网络的参数、更新完成的所述第一神经网络的参数和更新完成的所述第二神经网络的参数;
18、将所述策略参数集封装到目标四足机器人,并通过第三方软件对所述目标四足机器人发送环境交互命令,以实现对四足机器人运动的控制。
19、优选地,所述基于双重深度确定性策略梯度内置的策略网络更新策略为当所述第一神经网络和所述第二神经网络的参数更新次数达到预设值时更新一次所述目标策略网络的参数。
20、优选地,所述经验转移数据包括:当前状态数据、当前动作数据、奖励数据以及下次状态数据。
21、优选地,所述损失函数为所述目标网络值与所述中间网络值的均方差。
22、优选地,所述目标策略网路为长短期记忆网络。
23、优选地,所述神经系统为双重深度确定性策略梯度网络。
24、优选地,所述奖励机制为稠密奖励。
25、根据本发明提供的具体实施例,本发明公开了以下技术效果:
26、本发明提供了一种基于深度强化学习的四足机器人运动控制方法,属于四足机器人运动控制领域;包括:构建目标策略网络和神经系统,收集四足机器人与环境的交互数据,随机挑选交互数据输入值目标策略网络进行计算,同时添加动作噪声向量,得到候选策略数据,基于预设策略对目标策略网络参数进行更新,将候选策略数据输入到神经系统进行迭代,得到策略参数集,将策略参数集封装到目标四足机器人并通过第三方软件对所述目标四足机器人发送环境交互命令实现对四足机器人运动的控制。本发明在迭代策略是采用双网络训练,降低了过估计偏差的概率,同时引入动作噪声,增强了四足机器人应对环境变化的能力。
技术特征:
1.一种基于深度强化学习的四足机器人运动控制方法,其特征在于,包括:
2.根据权利要求1所述的一种基于深度强化学习的四足机器人运动控制方法,其特征在于,所述基于双重深度确定性策略梯度内置的策略网络更新策略为当所述第一神经网络和所述第二神经网络的参数更新次数达到预设值时更新一次所述目标策略网络的参数。
3.根据权利要求1所述的一种基于深度强化学习的四足机器人运动控制方法,其特征在于,所述经验转移数据包括:当前状态数据、当前动作数据、奖励数据以及下次状态数据。
4.根据权利要求1所述的一种基于深度强化学习的四足机器人运动控制方法,其特征在于,所述损失函数为所述目标网络值与所述中间网络值的均方差。
5.根据权利要求1所述的一种基于深度强化学习的四足机器人运动控制方法,其特征在于,所述目标策略网路为长短期记忆网络。
6.根据权利要求1所述的一种基于深度强化学习的四足机器人运动控制方法,其特征在于,所述神经系统为双重深度确定性策略梯度网络。
7.根据权利要求1所述的一种基于深度强化学习的四足机器人运动控制方法,其特征在于,所述奖励机制为稠密奖励。
技术总结
本发明提供了一种基于深度强化学习的四足机器人运动控制方法,属于四足机器人运动控制领域;包括:构建目标策略网络和神经系统,收集四足机器人与环境的交互数据,随机挑选交互数据输入值目标策略网络进行计算,同时添加动作噪声向量,得到候选策略数据,基于预设策略对目标策略网络参数进行更新,将候选策略数据输入到神经系统进行迭代,得到策略参数集,将策略参数集封装到目标四足机器人并通过第三方软件对所述目标四足机器人发送环境交互命令实现对四足机器人运动的控制。本发明在迭代过程中采用双网络训练,降低了过估计偏差的概率,同时引入动作噪声,增强了四足机器人应对环境变化的能力。
技术研发人员:王骥月,张震,魏金占,杨钰娟,朱兆旻,张广平
受保护的技术使用者:桂林航天工业学院
技术研发日:
技术公布日:2024/7/18
- 还没有人留言评论。精彩留言会获得点赞!