一种获取纯净语音的录音方法与流程
本发明属于语音录音技术领域,涉及一种获取纯净语音的录音方法。
背景技术:
一般录音时必然会在录取声音中加载背景杂音,这个杂音可能包含线路热噪声、或者环境声学杂音,只是视录音器材的优劣、录音环境的安静程度,背景噪音的强弱程度有所不同而已。如果为了获取纯净度较高的语音录音,可以采用搭建专门的录音室、以及采用专门的录音麦克风。录音室为了降低声音在室内的声学反射传播,所有的墙面家具表面均采用吸声材质进行装饰,麦克风采用高价格的对线路热噪声具有良好抑制性能、并且频谱响应较宽较平直的电子设备。此外,还有一种常见的获取纯净录音的技术方法,使用软件形式或者硬件形式的噪声滤波器。而这又分为两个技术路线:一、对于单麦克风处理,即获取声音后经过ad转换,变成数字域声音然后采用盲降噪技术进行噪声频谱估计从而将噪声成份滤除;二、使用多路麦克风组成的声学阵列,多路麦克风间互为参考信号,能够判定录音声源的方位、强弱,从而形成指向该音源的自适应bin丛,这样就避免了背景杂音的录取。但这些技术要么依赖特殊的录音场地或录音设备,要么依赖特殊的降噪仪器,总之迄今仍没有只依赖普通设备、甚至不需要麦克风设备的录音方法。
技术实现要素:
为了克服已有获取纯净录音方式的需要依赖特殊的录音场地或录音设备或降噪仪器、操作麻烦的不足,本发明提供一种不需要依赖任何麦克风设备即能实现高纯净的语音录音的获取纯净语音的录音方法。
本发明解决其技术问题所采用的技术方案是:
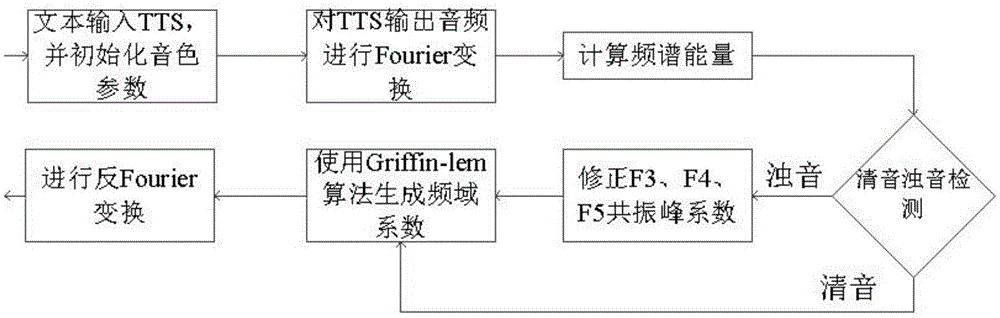
一种获取纯净语音的录音方法,包括以下步骤:
1)用户将需要录音的文本输入语音合成引擎tts,并选定一个音色参数;
2)收到语音合成tts引擎输出的合成音频,逐帧进行fourier变换,生成频域系数;
3)计算该帧频谱能量,即频域系数平方求和;
4)基于能量系数对该帧进行清音浊音检测,如果是清音,则跳到步骤6),否则进行步骤5);.
5)对浊音帧频谱能量的部分共振峰系数(f3、f4、f5)使用用户事先录制的用户自身的浊音频谱共振峰系数(f3、f4、f5)代替,得到修正的该帧频谱能量系数;
6)该帧频谱能量系数使用griffin-lem算法处理生成频域系数;
7)对该帧频域系数进行反fourier变换恢复成时域语音信号。
进一步,所述步骤1)中,选定的音色参数必须是使用录音室级的纯净采样合成语音的音色。
本发明中,采用完全不同的思路实现纯净语音的录音:采用浊音共振峰频谱搬移,再基于griffin-lem算法恢复成频域,通过反fourier变换生成时域语音信号。
原理是将需要录音的语音文本传送给语音合成引擎tts(一般tts引擎的音素库都是使用录音室级的纯净采样样本),同时选定一个待输出的合成音色(男声、女声或童声),收到语音合成引擎tts输出的音频后,对音频信号进行fourier变换,生成一帧帧频域系数,再计算每帧频谱能量系数,基于能量系数对该帧进行清音、浊音检测,对浊音段频谱能量的部分共振峰系数(f3、f4、f5)使用对应的用户事先录制的自身的浊音频谱共振峰系数(f3、f4、f5)代替,对修正后的该帧频谱系数使用griffin-lem算法处理生成频域系数,然后进行反fourier变换,生成具有用户自己音色特征的纯净语音。
本发明的有益效果主要表现在:不需要依赖任何麦克风设备即能实现录音,而且是高纯净的语音录音。
附图说明
图1是一种获取纯净语音的录音方法的流程图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1,一种获取纯净语音的录音方法,包括以下步骤:
1)用户将需要录音的文本输入语音合成引擎tts,并选定一个音色参数;
2)收到语音合成tts引擎输出的合成音频,逐帧进行fourier变换,生成频域系数;
3)计算该帧频谱能量,即频域系数平方求和;
4)基于能量系数对该帧进行清音浊音检测,如果是清音,则跳到步骤6),否则进行步骤5);.
5)对浊音帧频谱能量的部分共振峰系数(f3、f4、f5)使用用户事先录制的用户自身的浊音频谱共振峰系数(f3、f4、f5)代替,得到修正的该帧频谱能量系数;
6)该帧频谱能量系数使用griffin-lem算法处理生成频域系数;
7)对该帧频域系数进行反fourier变换恢复成时域语音信号。
进一步,所述步骤1)中,选定的音色参数必须是使用录音室级的纯净采样合成语音的音色。
技术特征:
技术总结
一种获取纯净语音的录音方法,包括以下步骤:1)用户将需要录音的文本输入语音合成引擎TTS,并选定一个音色参数;2)收到语音合成TTS引擎输出的合成音频,逐帧进行Fourier变换,生成频域系数;3)计算该帧频谱能量;4)基于能量系数对该帧进行清音浊音检测,如果是清音跳到步骤6),否则进行步骤5);5)对浊音帧频谱能量的部分共振峰系数使用用户事先录制的用户自身的浊音频谱共振峰系数代替,得到修正的该帧频谱能量系数;6)该帧频谱能量系数使用Griffin‑lem算法处理生成频域系数;7)对该帧频域系数进行反Fourier变换恢复成时域语音信号。本发明不需要依赖任何麦克风设备即能实现高纯净的语音录音。
技术研发人员:陆成刚
受保护的技术使用者:浙江工业大学
技术研发日:2019.01.09
技术公布日:2019.04.23
- 还没有人留言评论。精彩留言会获得点赞!