一种基于多任务学习和子域自适应的跨库语音情感识别方法
discrepancy, lmmd)分别将子域特征空间划分为情感子域特征空间和性别子域特征空间。情感子域特征分布对齐算法表达为:
[0015][0016]
其中为深度自编码器编码输出的源域低维特征中每个特征属于情感类别c的权重,为深度自编码器编码输出的目标域低维特征中每个特征属于情感类别c的权重。同时对齐情感的属性特征即性别,性别子域特征分布对齐为:
[0017][0018]
其中为源域低维特征中每个特征属于性别类别a的权重,为目标域样本中每个特征属于性别类别a的权重;
[0019]
(4)训练模型:整个网络训练是通过adam优化器不断优化训练的,由源域的情感标签和性别标签分别计算交叉熵来优化步骤(3)子域空间的准确划分。整个网络的损失函数表示为:
[0020][0021]
其中和分别是深度自编码器的重构损失,和分别是源域特征的情感信息交叉熵损失和性别信息交叉熵损失,和分别是基于lmmd的情感子域特征分布距离以及性别子域特征分布距离;
[0022]
(6)重复步骤(2)、(3),通过梯度下降法迭代训练网络模型,不断减小步骤(5)的损失函数,直至模型最优;
[0023]
(7)利用步骤(6)训练好的网络模型,使用sofmatx分类器识别步骤(1)中未加噪的目标域特征,最终实现语音情感在跨语料库条件下的情感识别。
附图说明
[0024]
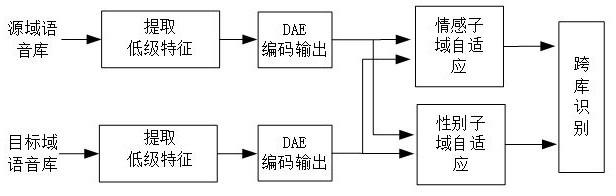
如附图所示,图1为一种基于多任务学习和子域自适应的跨库语音情感识别方法流程图。
具体实施方式
[0025]
下面结合具体实施方式对本发明做更进一步的说明。
[0026]
(1)选择emo
‑
db和casia两个语音情感语料库,分别作为源域数据库和目标域数据库;
[0027]
(2)选择上述两个语料库共同的情感语音作为数据集。具体而言,选用emo
‑
db数据库的4类情感语音(anger,fear,happiness,sadness)共有327条语音;casia汉语语音情感数据库的4类情感语音(anger,fear,happiness,sadness)共计800条语音数据。使用开源工具包opensmile提取2010年国际语音情感识别挑战赛的标准特征集,每条语音提取出的特征都为1582维;
[0028]
(3)制作源域语音信号的情感标签及性别标签,标签表示为one
‑
hot向量;
[0029]
(4)基于深度自编码器的隐层数量为3,隐层神经元节点分别设置为1200、500、1200,其中编码阶段的激活函数使用leakyrelu函数,解码阶段的激活函数使用relu函数;
[0030]
(5)将(2)得到的源域和目标域数据集特征作特征预处理之后,分别输入深度动编码器提取低维情感特征;
[0031]
(6)在低维情感空间中,同时基于lmmd的情感子域自适应算法和性别子域自适应算法来度量源域和目标域的低维情感特征分布距离。其中计算基于lmmd的子域自适应损失函数时,需要使用源域的低维情感特征,以及源域的低维性别特征及对应的真实标签;但是目标域的情感标签和性别标签需要使用softmax计算的概率分布产生伪标签;
[0032]
(7)整个网络的损失函数表示为:
[0033][0034]
其中和分别是深度自编码器的重构损失,和分别是源域特征的情感信息交叉熵损失和性别信息交叉熵损失,和分别是基于lmmd的情感子域特征分布距离以及性别子域特征分布距离;
[0035]
(8)模型的学习率和批处理大小都设置为0.00001和100,使用adam梯度下降法训练网络模型,模型迭代训练800次,分类器使用softmax。在情感子域自适应和性别子域自适应中,lmmd的特征映射函数均使用多核高斯函数,而高斯核数量分别设置为5和2;
[0036]
(9)将待识别的目标域语音信号进行归一化处理,并输入步骤(8)中训练好的深度自编码器,使用softmax分类器输出概率最大的类别即为识别的目标域情感类别;
[0037]
本发明请求保护的范围并不仅仅局限于本具体实施方式的描述。
技术特征:
1.一种基于多任务学习和子域自适应的跨库语音情感识别方法,其特征在于,包括以下步骤:(1)特征预处理:首先选取源域语料库和目标域语料库具有相同情感类别的数据分别作为训练集和测试集,然后提取他们的声学特征,对其进行归一化处理;(2)特征处理:将步骤(1)归一化之后得到的源域和目标域特征分别输入深度自编码器,压缩特征冗余信息,得到表征力强的低维情感特征;假设深度自编码的输入为x,解码输出为则深度自编码器的重构损失如下:则深度自编码器的重构损失如下:从而获取源域和目标域在低维空间中的情感表示;同时使用源域真实的情感标签和性别标签作交叉熵来优化子域空间的划分;交叉熵计算如下:其中为预测概率;(3)子域特征分布对齐:采用局部最大均值误差(local maximum mean discrepancy,lmmd)分别将子域特征空间划分为情感子域特征空间和性别子域特征空间;情感子域特征分布对齐算法表达为:其中为深度自编码器编码输出的源域低维特征中每个特征属于情感类别c的权重,为深度自编码器编码输出的目标域低维特征中每个特征属于情感类别c的权重;同时对齐情感的属性特征即性别,性别子域特征分布对齐为:其中为源域低维特征中每个特征属于性别类别a的权重,为目标域样本中每个特征属于性别类别a的权重;(4)训练模型:整个网络训练是通过adam优化器不断优化训练的,由源域的情感标签和性别标签分别计算交叉熵来优化步骤(3)子域空间的准确划分;整个网络的损失函数表示为:其中和分别是深度自编码器的重构损失,和分别是源域特征的情感信息交叉熵损失和性别信息交叉熵损失,和分别是基于lmmd的情感子域特征分布距离以及性别子域特征分布距离;(6)重复步骤(2)、(3),通过梯度下降法迭代训练网络模型,不断减小步骤(5)的损失函数,直至模型最优;
(7)利用步骤(6)训练好的网络模型,使用sofmatx分类器识别步骤(1)中未加噪的目标域特征,最终实现语音情感在跨语料库条件下的情感识别。
技术总结
本发明提出了一种基于多任务学习和子域自适应的跨库语音情感识别方法,本发明包括以下步骤:首先,源域和目标域提取的高维语音特征分别输入深度自编码网络,压缩特征冗余信息,获取低维情感特征;然后,采用子域自适应算法将低维特征空间分别划分成情感子域特征空间和性别子域特征空间,以此来减小特征分布距离;最后,将情感识别作为主任务,性别识别作为辅助任务,学习更多共性情感信息。本发明提出的方法可以有效提升跨库语音情感识别性能。的方法可以有效提升跨库语音情感识别性能。
技术研发人员:庄志豪 刘曼 白雪杰 单帅 陶华伟 傅洪亮
受保护的技术使用者:河南工业大学
技术研发日:2021.09.25
技术公布日:2021/12/30
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1