噪声抑制装置、噪声抑制方法以及噪声抑制程序与流程
本公开涉及噪声抑制装置、噪声抑制方法以及噪声抑制程序。
背景技术:
1、作为从在语音(以下也称为“语音”。)中混入了噪音(以下也称为“噪声”。)的声音信号中降低噪声成分的方法,已知有weiner法。根据该方法,sn(signal-noise)比得到改善,但语音成分劣化。于是,提出了通过进行与sn比相应的降噪处理来改善sn比并且抑制语音成分的劣化的方法(例如参照非专利文献1)。
2、现有技术文献
3、非专利文献
4、非专利文献1:佐佐木润子和另一名作者著,“マスキング効果を用いた低失真雑音低減方式における効果的な原音付加率の検討”,日本声学学会研究发表会演讲论文集,pp.503-504,1998年9月
技术实现思路
1、发明要解决的问题
2、但是,在噪声下,作为识别对象的语音被噪声埋没,sn比的测定精度下降。因此,存在不能适当地进行噪声成分的抑制和语音成分的劣化的抑制这样的问题。
3、本公开是为了解决如上问题而完成的,其目的在于,提供一种能够适当地进行噪声成分的抑制和语音成分的劣化的抑制的噪声抑制装置、噪声抑制方法及噪声抑制程序。
4、用于解决问题的手段
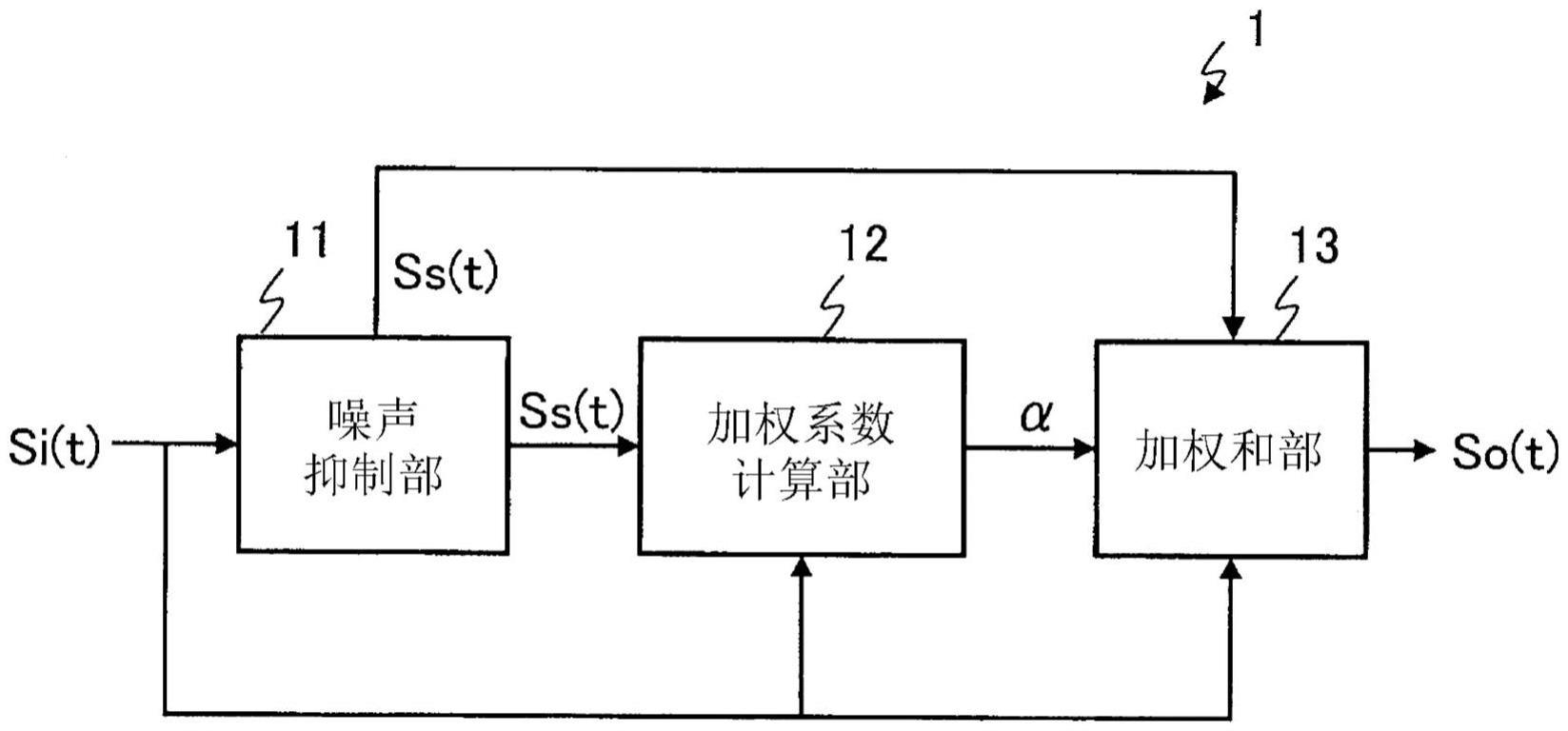
5、本公开的噪声抑制装置的特征在于,具备:噪声抑制部,其对输入数据进行噪声抑制处理而生成噪声抑制后数据;加权系数计算部,其基于时间序列上的预先决定的区间内的所述输入数据和所述预先决定的区间内的所述噪声抑制后数据,来决定加权系数;以及加权和部,其将基于所述加权系数的值用作权重,对所述输入数据与所述噪声抑制后数据进行加权相加,由此生成输出数据。
6、本公开的另一噪声抑制装置的特征在于,噪声抑制部,其对输入数据进行噪声抑制处理而生成噪声抑制后数据;加权系数计算部,其将所述输入数据的全部区间的数据划分为时间序列上的预先决定的多个短区间,基于所述多个短区间内的所述输入数据和所述多个短区间内的所述噪声抑制后数据,决定所述多个短区间各自的加权系数;以及加权和部,其分别在所述多个短区间内,将基于所述加权系数的值用作权重,对所述输入数据与所述噪声抑制后数据进行加权相加,由此生成输出数据。
7、发明的效果
8、根据本公开,能够适当地进行输入数据中的噪声成分的抑制和输入数据中的语音成分的劣化的抑制。
技术特征:
1.一种噪声抑制装置,其特征在于,具备:
2.根据权利要求1所述的噪声抑制装置,其特征在于,
3.根据权利要求1或2所述的噪声抑制装置,其特征在于,
4.根据权利要求1至3中的任意一项所述的噪声抑制装置,其特征在于,
5.一种噪声抑制装置,其特征在于,具备:
6.根据权利要求5所述的噪声抑制装置,其特征在于,
7.一种噪声抑制方法,其是由计算机执行的噪声抑制方法,其特征在于,具有以下步骤:
8.一种噪声抑制程序,其特征在于,
9.一种噪声抑制方法,其是由计算机执行的噪声抑制方法,其特征在于,具有以下步骤:
10.一种噪声抑制程序,其特征在于,
技术总结
噪声抑制装置(1)具备:噪声抑制部(11),其对输入数据(Si(t))进行噪声抑制处理而生成噪声抑制后数据(Ss(t));加权系数计算部(12),其基于时间序列上的预先决定的区间(E)内的输入数据(Si(t))和预先决定的区间(E)内的噪声抑制后数据(Ss(t))来决定加权系数(α);以及加权和部(13),其将基于加权系数(α)的值用作权重,对输入数据(Si(t))与噪声抑制后数据(Ss(t))进行加权相加,由此生成输出数据(So(t))。
技术研发人员:花泽利行
受保护的技术使用者:三菱电机株式会社
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!