拾音方法、装置、非易失性存储介质及终端设备与流程
本发明涉及声音设备领域,具体而言,涉及一种拾音方法、装置、非易失性存储介质及终端设备。
背景技术:
1、麦克风如何清晰拾音以及如何甄别麦克风采集到的声音是有价值的声音还是噪音及其他类型的需要抑制的声音是业界面临的一个问题。
2、当声音采集设备进行收音时,声音采集设备的麦克风会采集到不同类型、不同对象的声音,然而声音采集设备的使用者可能只需要麦克风采集到自己的声音即可,而将其他声音抑制掉,现有的利用麦克风拾音的方法和系统,在存在噪声和混响的情况下,算法性能下降明显而且语音的失真较大,同时当存在两个及以上说话人同时讲话时,效果也不理想。
3、针对上述的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本发明实施例提供了一种拾音方法、装置、非易失性存储介质及终端设备,以至少解决拾音设备无法准确区分需要增强的声音导致声音处理结果不理想的技术问题。
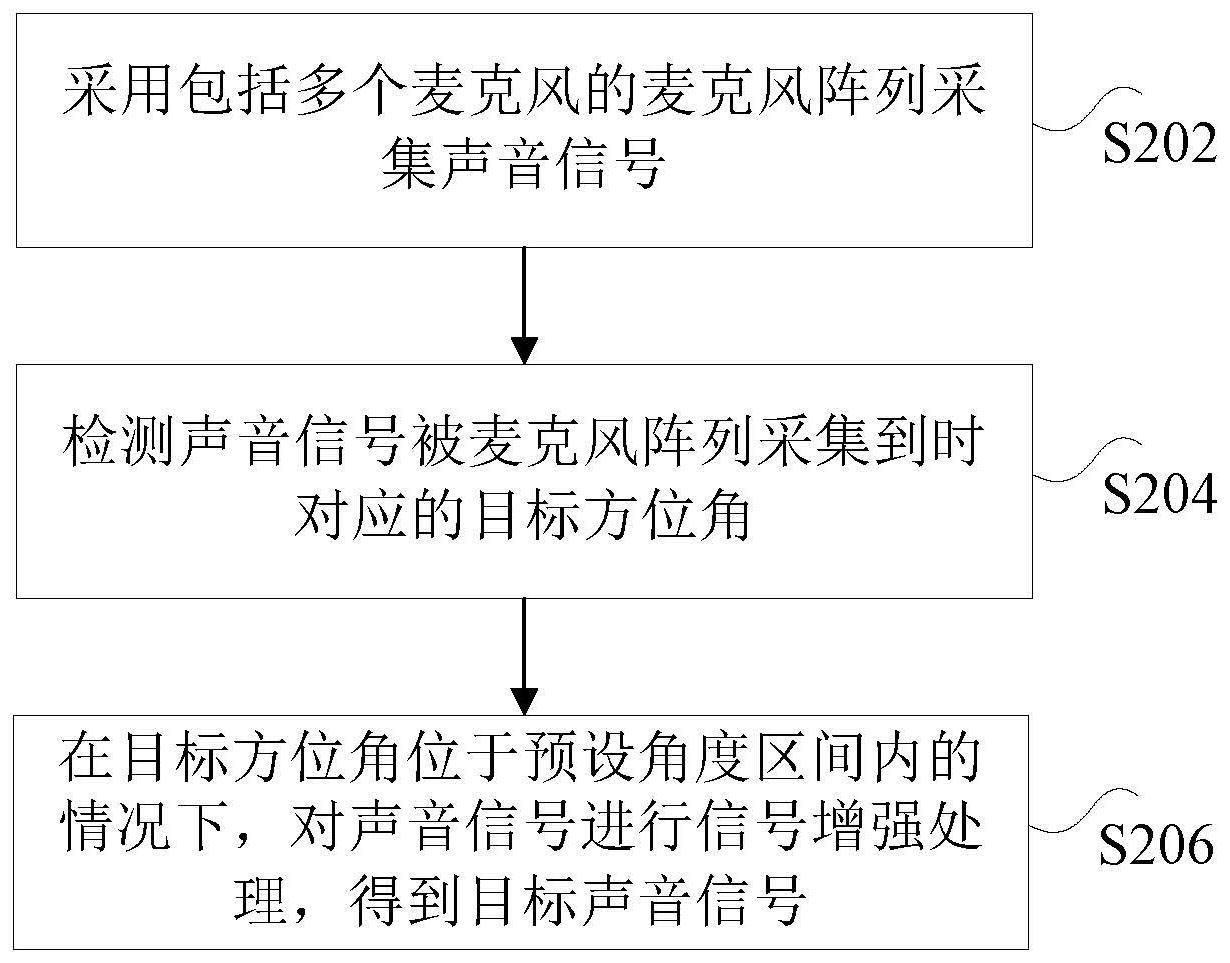
2、根据本发明实施例的一个方面,提供了一种拾音方法,包括:采用包括多个麦克风的麦克风阵列采集声音信号;检测所述声音信号被所述麦克风阵列采集到时对应的目标方位角;在所述目标方位角位于预设角度区间内的情况下,对所述声音信号进行信号增强处理,得到目标声音信号。
3、可选地,所述检测所述声音信号被所述麦克风阵列采集到时对应的目标方位角,包括:将所述声音信号转换为数字信号;将所述数字信号输入卷积神经网络cnn模型,得到所述数字信号对应的目标方位角,其中,所述cnn模型用于对声音方向进行定位。
4、可选地,所述将所述数字信号输入卷积神经网络cnn模型,得到所述数字信号对应的目标方位角,包括:采用所述cnn模型的特征提取模块,从所述数字信号中提取广义互相关性特征和滤波器组特征;采用所述cnn模型的定位模块,基于所述广义互相关性特征和所述滤波器组特征,确定所述数字信号对应的目标方位角。
5、可选地,所述采用所述cnn模型的定位模块基于所述广义互相关性特征和所述滤波器组特征,确定所述数字信号对应的目标方位角,包括:采用所述cnn模型的所述定位模块,基于所述广义互相关性特征和所述滤波器组特征,确定所述麦克风阵列从任意一个方位角采集所述声音信号的概率值;采用所述定位模块,基于所述概率值,确定所述数字信号对应的目标方位角。
6、可选地,所述麦克风阵列中包括的多个麦克风为多个指向性麦克风,多个所述指向性麦克风依次位于正多边形的多个顶点上。
7、可选地,所述方法还包括:输出所述目标声音信号至目标设备,其中,所述目标设备用于播放或者存储所述目标声音信号。
8、可选地,所述方法还包括:在所述目标方位角位于所述预设角度区间以外的情况下,对所述声音信号进行抑制,得到噪声信号;输出所述噪声信号至所述目标设备。
9、可选地,在采用包括多个麦克风的麦克风阵列采集声音信号之前,所述方法还包括:展示第一提示信息,其中,所述第一提示信息用于提示所述预设角度区间;在所述目标方位角位于所述预设角度区间内的情况下,所述方法还包括:展示第二提示信息,其中,所述第二提示信息用于提示所述声音信号对应的所述目标方位角位于所述预设角度区间内;在所述目标方位角位于所述预设角度区间以外的情况下,所述方法还包括:展示第三提示信息,其中,所述第三提示信息用于提示所述声音信号对应的所述目标方位角位于所述预设角度区间以外。
10、根据本发明实施例的另一方面,还提供了一种拾音方法,包括:接收声音信号,其中,所述声音信号由包括多个麦克风的麦克风阵列采集得到;检测所述声音信号被所述麦克风阵列采集到时对应的目标方位角;在所述目标方位角位于预设角度区间内的情况下,对所述声音信号进行信号增强处理,得到目标声音信号;输出所述目标声音信号至目标设备,其中,所述目标设备用于播放或者存储所述目标声音信号。
11、根据本发明实施例的另一方面,还提供了一种拾音装置,包括:采集模块,用于采用包括多个麦克风的麦克风阵列采集声音信号;第一检测模块,用于检测所述声音信号被所述麦克风阵列采集到时对应的目标方位角;第一增强模块,用于在所述目标方位角位于预设角度区间内的情况下,对所述声音信号进行信号增强处理,得到目标声音信号。
12、根据本发明实施例的另一方面,还提供了一种拾音装置,包括:接收模块,用于接收声音信号,其中,所述声音信号由包括多个麦克风的麦克风阵列采集得到;第二检测模块,用于检测所述声音信号被所述麦克风阵列采集到时对应的目标方位角;第二增强模块,用于在所述目标方位角位于预设角度区间内的情况下,对所述声音信号进行信号增强处理,得到目标声音信号;输出模块,用于输出所述目标声音信号至目标设备,其中,所述目标设备用于播放或者存储所述目标声音信号。
13、根据本发明实施例的又一方面,还提供了一种非易失性存储介质,所述非易失性存储介质包括存储的程序,其中,在所述程序运行时控制所述非易失性存储介质所在设备执行上述任意一项所述拾音方法。
14、根据本发明实施例的再一方面,还提供了一种终端设备,所述终端设备包括处理器,所述处理器用于运行程序,其中,所述程序运行时执行上述任意一项所述拾音方法。
15、在本发明实施例中,通过采用包括多个麦克风的麦克风阵列采集声音信号;检测声音信号被麦克风阵列采集到时对应的目标方位角;在目标方位角位于预设角度区间内的情况下,对声音信号进行信号增强处理,得到目标声音信号,达到了增强来自预设角度区间内的声音的目的,从而实现了提高拾音设备的拾音效果的技术效果,进而解决了拾音设备无法准确区分需要增强的声音导致声音处理结果不理想的技术问题。
技术特征:
1.一种拾音方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述检测所述声音信号被所述麦克风阵列采集到时对应的目标方位角,包括:
3.根据权利要求2所述的方法,其特征在于,所述将所述数字信号输入卷积神经网络cnn模型,得到所述数字信号对应的目标方位角,包括:
4.根据权利要求3所述的方法,其特征在于,所述采用所述cnn模型的定位模块基于所述广义互相关性特征和所述滤波器组特征,确定所述数字信号对应的目标方位角,包括:
5.根据权利要求1所述的方法,其特征在于,所述麦克风阵列中包括的多个麦克风为多个指向性麦克风,多个所述指向性麦克风依次位于正多边形的多个顶点上。
6.根据权利要求1所述的方法,其特征在于,所述方法还包括:
7.根据权利要求6所述的方法,其特征在于,所述方法还包括:
8.根据权利要求1所述的方法,其特征在于,
9.一种拾音方法,其特征在于,包括:
10.一种拾音装置,其特征在于,包括:
11.一种拾音装置,其特征在于,包括:
12.一种非易失性存储介质,其特征在于,所述非易失性存储介质包括存储的程序,其中,在所述程序运行时控制所述非易失性存储介质所在设备执行权利要求1至9中任意一项所述拾音方法。
13.一种终端设备,其特征在于,所述终端设备包括处理器,所述处理器用于运行程序,其中,所述程序运行时执行权利要求1至9中任意一项所述拾音方法。
技术总结
本发明公开了一种拾音方法、装置、非易失性存储介质及终端设备。其中,该方法包括:采用包括多个麦克风的麦克风阵列采集声音信号;检测声音信号被麦克风阵列采集到时对应的目标方位角;在目标方位角位于预设角度区间内的情况下,对声音信号进行信号增强处理,得到目标声音信号。本发明解决了拾音设备无法准确区分需要增强的声音导致声音处理结果不理想的技术问题。
技术研发人员:康洪涛
受保护的技术使用者:北京中创视讯科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!