语音拒识方法、装置及设备与流程
本申请涉及语音交互,特别涉及一种语音拒识方法、装置及设备。
背景技术:
1、语音交互在车载免唤醒的应用场景中,通常需要通过拒识将非用户指令尽可能的剔除。但是,拒识过程中由于输入到拒识算法的数据错误较多,使得拒识模型不够准确,从而导致错误数据误闯拒识模型,非用户指令不能被剔除。
技术实现思路
1、本申请提供了一种语音拒识方法、装置及设备,以提高输入到拒识算法(模型)的数据的准确性。
2、第一方面,本申请提供一种语音拒识方法,包括:
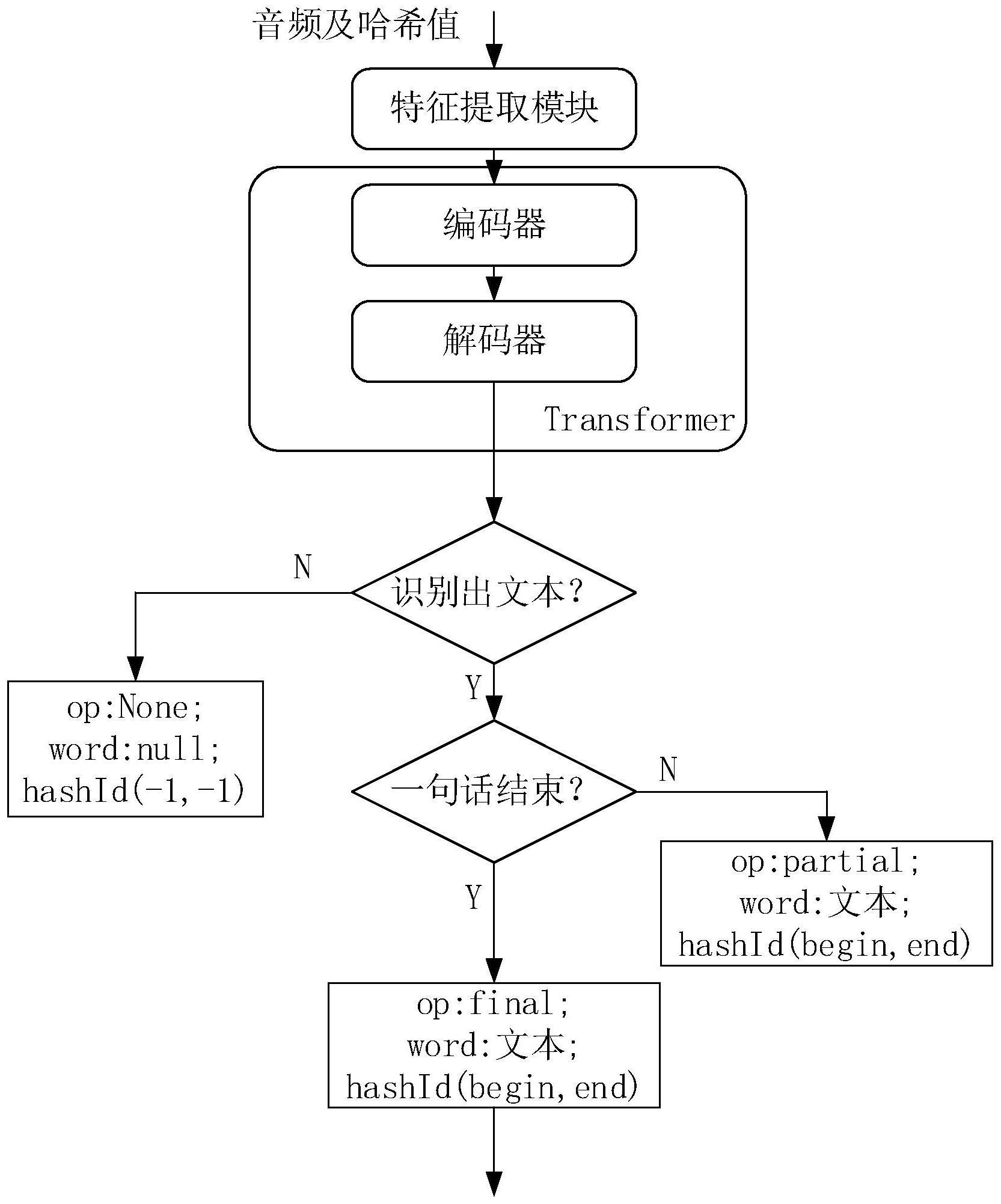
3、通过自动语音识别模型对待处理音频进行识别;其中,待处理音频为音频缓冲队列中的音频,音频缓冲队列中的音频为原始音频经语音端点检测得到的音频;当识别结果为文本,且当文本为第一句子的结尾时,确定第一句子的音频在音频缓冲队列中的起止位置,以及得到第一句子的文本;其中,起止位置用于抽取第一句子的音频;通过拒识模型对第一句子的音频及语义表示进行检测,其中,语义表示为第一句子的文本经自然语言理解的识别结果。通过确定第一句子的音频在音频缓冲队列中的起止位置,使得后续可以利用该起止位置抽取出相应的音频,从而去除噪音带来的误差,提高输入到拒识模型的数据的准确性。由于输入拒识模型的数据准确性提高,使得拒识模型更加准确,也使得拒识模型拒识的正确率有效提高。
4、在一种可能的实现方式中,当识别结果为文本时,还包括:将文本入队文本队列,以及将文本对应的起始音频哈希值索引入队起始索引队列,将文本对应的结尾音频哈希值索引入队结尾索引队列,以便于得到第一句子文本及对应的音频位置。
5、在一种可能的实现方式中,确定第一句子的音频在音频缓冲队列中的起止位置,包括:从文本队列中找到与文本的前缀相同且长度为1个文字的元素;从起始索引队列中找到该元素的起始音频哈希值索引,从结尾索引队列中找到该元素的结尾音频哈希值索引;利用元素的起始音频哈希值索引确定第一句子的起始音频哈希值,利用结尾音频哈希值索引确定第一句子的结尾音频哈希值,其中,起始音频哈希值为(或者说表示)第一句子对应的音频在音频缓冲队列中的位置,结尾音频哈希值为第一句子对应的音频在音频缓冲队列中的位置。
6、在一种可能的实现方式中,将文本入队文本队列,包括:将文本队列中的最后一个元素内容与文本合并,作为新的最后一个元素入队文本队列;最后一个元素内容与文本合并后的内容为第一句子的文本,以易于得到第一句子的文本。
7、在一种可能的实现方式中,得到第一句子的文本,包括:得到新的最后一个元素的内容。
8、在一种可能的实现方式中,确定第一句子的音频在音频缓冲队列中的起止位置之后,语音拒识方法还包括:根据起止位置抽取第一句子的音频。
9、在一种可能的实现方式中,根据起止位置抽取第一句子的音频,包括:利用第一句子的文本对应的起始音频哈希值和结尾音频哈希值,从音频缓冲队列中抽取第一句子对应的音频。
10、在一种可能的实现方式中,通过拒识模型对第一句子的音频及语义表示进行检测,包括:在语义表示的第一检测结果为有效人声时,利用语速计算模型对第一检测结果及第一句子的音频进行第二检测,其中,第一检测结果为语义表示经场景策略拒识模型检测的结果。减少了拒识的计算量,提高了语音拒识的效率。
11、在一种可能的实现方式中,利用语速计算模型对第一检测结果及第一句子的音频进行第二检测之后,包括:在第二检测的结果为有效人声时,利用语音语义多模态拒识模型对第二检测的结果及第一句子的音频进行第三检测。在减少拒识计算量的同时,进一步提高拒识的准确率。
12、第二方面,本申请提供一种语音拒识装置,包括:第一模块、第二模块和第三模块,第一模块可以是传统的自动语音识别模块,用于通过自动语音识别模型对待处理音频进行识别;其中,待处理音频为音频缓冲队列中的音频,音频缓冲队列中的音频为原始音频经语音端点检测得到的音频;第二模块用于当识别结果为文本,且当文本为第一句子的结尾时,确定第一句子的音频在音频缓冲队列中的起止位置,以及得到所述第一句子的文本;其中,起止位置用于抽取第一句子的音频;第三模块用于通过拒识模型对第一句子的音频及语义表示进行检测,其中,语义表示为第一句子的文本经自然语言理解的识别结果。
13、在一种可能的实现方式中,还包括:第四模块,用于当第一模块的识别结果为文本时,将文本入队文本队列,以及将文本对应的起始音频哈希值索引入队起始索引队列。
14、在一种可能的实现方式中,第二模块用于:从文本队列中找到与文本的前缀相同且长度为1个文字的元素;从起始索引队列中找到元素的起始音频哈希值索引和结尾音频哈希值索引;利用元素的起始音频哈希值索引确定第一句子的起始音频哈希值,利用结尾音频哈希值索引确定第一句子的结尾音频哈希值;其中,起始音频哈希值为第一句子对应的音频在音频缓冲队列中的位置,结尾音频哈希值为所述第一句子对应的音频在音频缓冲队列中的位置。
15、在一种可能的实现方式中,第三模块用于:将文本队列中的最后一个元素内容与文本合并,作为新的最后一个元素入队文本队列;最后一个元素内容与文本合并后的内容第一句子的文本。
16、在一种可能的实现方式中,第二模块用于:得到新的最后一个元素的内容。
17、在一种可能的实现方式中,语音拒识装置,还包括:第五模块;第五模块用于在第二模块确定第一句子的音频在音频缓冲队列中的起止位置之后,根据起止位置抽取第一句子的音频。
18、在一种可能的实现方式中,第五模块用于:利用第一句子的文本对应的起始音频哈希值和结尾音频哈希值,从音频缓冲队列中抽取第一句子对应的音频。
19、在一种可能的实现方式中,第三模块用于:在语义表示的第一检测结果为有效人声时,利用语速计算模型对第一检测结果及第一句子的音频进行第二检测,其中,第一检测结果为语义表示经场景策略拒识模型检测的结果。
20、在一种可能的实现方式中,第三模块用于:在利用语速计算模型对第一检测结果及第一句子的音频进行第二检测之后,在第二检测的结果为有效人声时,利用语音语义多模态拒识模型对第二检测的结果及第一句子的音频进行第三检测。
21、第三方面,本申请提供一种电子设备,如手机、平板电脑、车机、轻车机、智能家居等,包括上述第二方面任一项的装置。
22、第四方面,本申请提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行第一方面任一项的方法。
23、第五方面,本申请提供一种芯片系统,执行第一方面任一项的方法。
24、第六方面,本申请提供一种计算机程序,当计算机程序被计算机执行时,用于执行第一方面任一项的方法。
25、在一种可能的设计中,第六方面中的程序可以全部或者部分存储在与处理器封装在一起的存储介质上,也可以部分或者全部存储在不与处理器封装在一起的存储器上。
技术特征:
1.一种语音拒识方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,当识别结果为文本时,还包括:
3.根据权利要求2所述的方法,其特征在于,确定所述第一句子的音频在所述音频缓冲队列中的起止位置,包括:
4.根据权利要求2或3所述的方法,其特征在于,将所述文本入队文本队列,包括:
5.根据权利要求4所述的方法,其特征在于,得到所述第一句子的文本,包括:
6.根据权利要求1至5中任一项所述的方法,其特征在于,所述确定所述第一句子的音频在所述音频缓冲队列中的起止位置之后,所述方法还包括:
7.根据权利要求6所述的方法,其特征在于,根据所述起止位置抽取所述第一句子的音频,包括:
8.根据权利要求6或7所述的方法,其特征在于,通过拒识模型对所述第一句子的音频及语义表示进行检测,包括:
9.根据权利要求8所述的方法,其特征在于,利用语速计算模型对所述第一检测结果及所述第一句子的音频进行第二检测之后,包括:
10.一种语音拒识装置,其特征在于,包括:
11.根据权利要求10所述的装置,其特征在于,还包括:第四模块,用于当所述第一模块的识别结果为文本时,将所述文本入队文本队列,以及将所述文本对应的起始音频哈希值索引入队起始索引队列,,将所述文本对应的结尾音频哈希值索引入队结尾索引队列。
12.根据权利要求11所述的装置,其特征在于,所述第二模块用于:
13.根据权利要求11或12所述的装置,其特征在于,所述第四模块用于:将所述文本队列中的最后一个元素内容与所述文本合并,作为新的最后一个元素入队所述文本队列;所述最后一个元素内容与所述文本合并后的内容为所述第一句子的文本。
14.根据权利要求13所述的装置,其特征在于,所述第二模块用于:得到所述新的最后一个元素的内容。
15.根据权利要求10至14任一项所述的装置,其特征在于,还包括:
16.根据权利要求15所述的装置,其特征在于,所述第五模块用于:
17.根据权利要求15或16所述的装置,其特征在于,所述第三模块用于:
18.根据权利要求17所述的装置,其特征在于,所述第三模块用于:在利用语速计算模型对所述第一检测结果及所述第一句子的音频进行第二检测之后,在所述第二检测的结果为有效人声时,利用语音语义多模态拒识模型对所述第二检测的结果及所述第一句子的音频进行第三检测。
19.一种电子设备,其特征在于,包括上述权利要求10至18任一项所述的装置。
20.一种芯片系统,其特征在于,执行权利要求1至9任一项所述的方法。
21.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行权利要求1至9任一项所述的方法。
技术总结
本申请提供一种语音拒识方法、装置及设备,语音拒识方法中,通过确定第一句子的音频在音频缓冲队列中的起止位置,使得后续可以利用该起止位置抽取出相应的音频,从而去除噪音带来的误差,提高输入到拒识模型的数据的准确性。
技术研发人员:任婕,孙峰,朱希迅,许娟婷,张腾
受保护的技术使用者:华为技术有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!