一种仿生音频拾音器及基于其的语音会议音频分离方法与流程
1.本发明涉及音频分离技术领域,尤其是一种仿生音频拾音器及基于其的语音会议音频分离方法。
背景技术:
2.随着语音识别技术的不断发展,会议速记机已经得到广泛应用,对会议中的语音信息进行识别与记录。由于会议中往往存在不同的发言人,不同发言人的音频虽然在音色、音调、音频上都存在差异,但是发言人的音频受到会议现场的串音、混响、回音、叠音等杂音的影响,大大提升了音频分离的难度。
3.针对不同角色音频分离难的问题,研发人员不断探索,提出了不同的解决方案。
4.1、通过麦克风传输地址编码实现角色分离,缺点是无法避免串音问题。例如,当2个麦克风距离较近,容易通过近距离传播发生串音;当2个麦克风距离较远,也会通过声波反射形成串音现象。串音导致音频同质化,影响角色分离效果。
5.2、通过声纹识别实现角色分离,缺点是角色分离误差太大,当出现音频短、音量小、音质相似或多人说话的情况时,基本达不到角色分离效果。
技术实现要素:
6.针对现有会议场景下,不同角色音频分离难的问题,本发明提出一种仿生音频拾音器及基于其的语音会议音频分离方法。
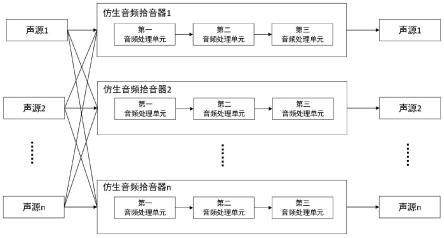
7.本发明保护一种仿生音频拾音器,依次包括第一音频处理单元、第二音频处理单元和第三音频处理单元。
8.所述第一音频处理单元用于采集会议音频并传输至所述第二音频处理单元;
9.所述第二音频处理单元用于会议音频的吸收低频白噪音和高频白噪音并传输至所述第三音频处理单元;
10.所述第三音频处理单元由gammatone滤波器组构成,用于从会议音频的混合信号中提取出不同角色的音频分量。
11.本发明还保护一种语音会议音频分离方法,为每位发言人配备一台仿生音频拾音器,并将该仿生音频拾音器提取出不同角色的音频分量输入音频分离网络,音频分离网络输出当前发言人的音频分量,并基于耳间延时差滤除噪音和串音。
12.音频分离网络为深度学习网络,通过大量标记过的会议音频数据训练得到,标记信息包括但不限于基音、节首音位置、相位、声压级。
13.本发明提供的仿生音频拾音器及基于其的语音会议音频分离方法,通过gammatone滤波器组实现仿生音频拾音技术,从会议音频的混合信号中提取出不同角色的音频分量;再基于深度学习网络筛选出当前发言人的音频分量,实现语音会议音频分离,音频分离效果良好。
附图说明
14.图1为人耳结构示意图;
15.图2为第三音频处理单元不同角色的音频分量提取结果示意图;
16.图3为语音会议音频分离方法流程示意图;
17.图4为深度学习网络示意图。
具体实施方式
18.下面结合附图和具体实施方式对本发明作进一步详细的说明。本发明的实施例是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显而易见的。选择和描述实施例是为了更好说明本发明的原理和实际应用,并且使本领域的普通技术人员能够理解本发明从而设计适于特定用途的带有各种修改的各种实施例。
19.实施例1
20.人耳(结构如图1所示)能够从纷繁复杂的声音中分辨出自己想要获取的声源信号,这是由于人耳具有非均匀的频谱分辨率、双耳定位和掩蔽等功能,能够区分不同声源的基音、节首音位置、相位和声压级等声音特征的差异,从而能够区分出不同声源。
21.本发明公开一种仿生音频拾音器,模拟人耳构造,依次包括第一音频处理单元、第二音频处理单元和第三音频处理单元。
22.所述第一音频处理单元相当于图1中的外耳,用于采集会议音频并传输至所述第二音频处理单元。
23.所述第二音频处理单元相当于图1中的中耳,用于会议音频的吸收低频白噪音和高频白噪音并传输至所述第三音频处理单元。
24.所述第三音频处理单元相当于图1中的内耳,用于从会议音频的混合信号中提取出不同角色的音频分量,提取结果如图2所示。
25.所述第三音频处理单元由16-128个gammatone滤波器组组成。以单通道gammatone滤波器为基础,构建多通道gammatone滤波器组,对输入的混合信号进行多频率子带滤波,得到信号的时间频率数据表现形式,用于特征提取与分析加工。
26.与仿生音频拾音相关的主要参数包括频率分析范围、通道数量、耳间延时差、通道中心频率及带宽。本实施例根据人耳的听感知特性,结合音频通用采样频率,将音频信号在频域分析的频率范围确定在50~8000hz,在该频带范围内,采用64通道gammatone滤波器组。gammatone滤波器组带来的全频域增益在8~15db之间,低频部分增益较低,高频部分增益较高,幅值增益在整个频率区间上变化比较一致平滑。与此同时,这种增益的不一致与人耳听感知特性及声音分析处理前端的经验相一致,即人耳对高频能量有一定程度的加强。
27.实施例2
28.一种语音会议音频分离方法,为每位发言人配备一台实施例1所述的仿生音频拾音器,并将该仿生音频拾音器提取出不同角色的音频分量输入音频分离网络,音频分离网络输出当前发言人的音频分量,流程如图3所示,并基于耳间延时差滤除噪音和串音。
29.耳间延时差是指多路麦克风的声音信号间的延时差值,由于多路麦克风采集到的是带噪声音,这个延时差是各种环境噪声源发出的噪声与目标音混合作用的结果。当噪声
强度不大时,在目标声源发声的时候,它主要体现于目标声源的延时值;当与目标音相比,噪声强度很大或是目标音没有出现的时候,它主要体现于背景噪声的混合延时。由于不同频带的声音信号的延时会有微小的差异,对于同一时间帧,需要计算不同频带的延时差,前端的gammatone滤波器组已为这一过程做好了准备。
30.通过求互相关的最大值即可求得延时差值。由下列公式计算出第c个频率通道、第m帧、延时为τ时的互相关以及第c个频率通道、第m时间帧的多路麦克信号的延时差值。
[0031][0032][0033]
音频分离网络为深度学习网络(参照图4所示),通过大量标记过的会议音频数据训练得到,标记信息包括但不限于基音、节首音位置、相位、声压级。
[0034]
显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域及相关领域的普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
技术特征:
1.一种仿生音频拾音器,其特征在于,依次包括第一音频处理单元、第二音频处理单元和第三音频处理单元;所述第一音频处理单元用于采集会议音频并传输至所述第二音频处理单元,所述第二音频处理单元用于会议音频的吸收低频白噪音和高频白噪音并传输至所述第三音频处理单元,所述第三音频处理单元用于从会议音频的混合信号中提取出不同角色的音频分量。2.根据权利要求2所述的仿生音频拾音器,其特征在于,所述第三音频处理单元由gammatone滤波器组构成。3.一种语音会议音频分离方法,其特征在于,为每位发言人配备一台权利要求2所述的仿生音频拾音器,并将该仿生音频拾音器提取出不同角色的音频分量输入音频分离网络,音频分离网络输出当前发言人的音频分量。4.根据权利要求3所述的语音会议音频分离方法,其特征在于,音频分离网络为深度学习网络,通过大量标记过的会议音频数据训练得到,标记信息包括但不限于基音、节首音位置、相位、声压级。5.根据权利要求3或4所述的语音会议音频分离方法,其特征在于,基于耳间延时差滤除噪音和串音。
技术总结
本发明公开了一种仿生音频拾音器及基于其的语音会议音频分离方法,仿生音频拾音器依次包括第一音频处理单元、第二音频处理单元和第三音频处理单元;所述第一音频处理单元用于采集会议音频并传输至所述第二音频处理单元,所述第二音频处理单元用于会议音频的吸收低频白噪音和高频白噪音并传输至所述第三音频处理单元,所述第三音频处理单元用于从会议音频的混合信号中提取出不同角色的音频分量。本发明Gammatone滤波器组实现仿生音频拾音技术,从会议音频的混合信号中提取出不同角色的音频分量;再基于深度学习网络筛选出当前发言人的音频分量,实现语音会议音频分离,音频分离效果良好。离效果良好。离效果良好。
技术研发人员:虞焰兴 徐勇
受保护的技术使用者:安徽声讯信息技术有限公司
技术研发日:2022.05.31
技术公布日:2022/9/2
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1