模型训练、语音识别方法、装置、设备和存储介质与流程
本申请涉及人工智能领域,尤其涉及一种模型训练方法、语音识别方法、装置、设备与计算机可读存储介质。
背景技术:
1、深度学习(deep learning,dl),其实质是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习样本数据的内在规律和表示层次。通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,即可基于“高层”特征表示完成复杂的分类等学习任务。
2、深度学习虽然具备强大的从少数样本集中学习数据集本质特征的能力,但运用于实际场景时,可能面临一些问题。比如,基于深度学习的自动语音识别 (automatic speechrecognition,asr)模型应用于诸如语音识别等实际场景时,往往面临着模型大而冗余,识别速度难以满足实时性要求的问题。
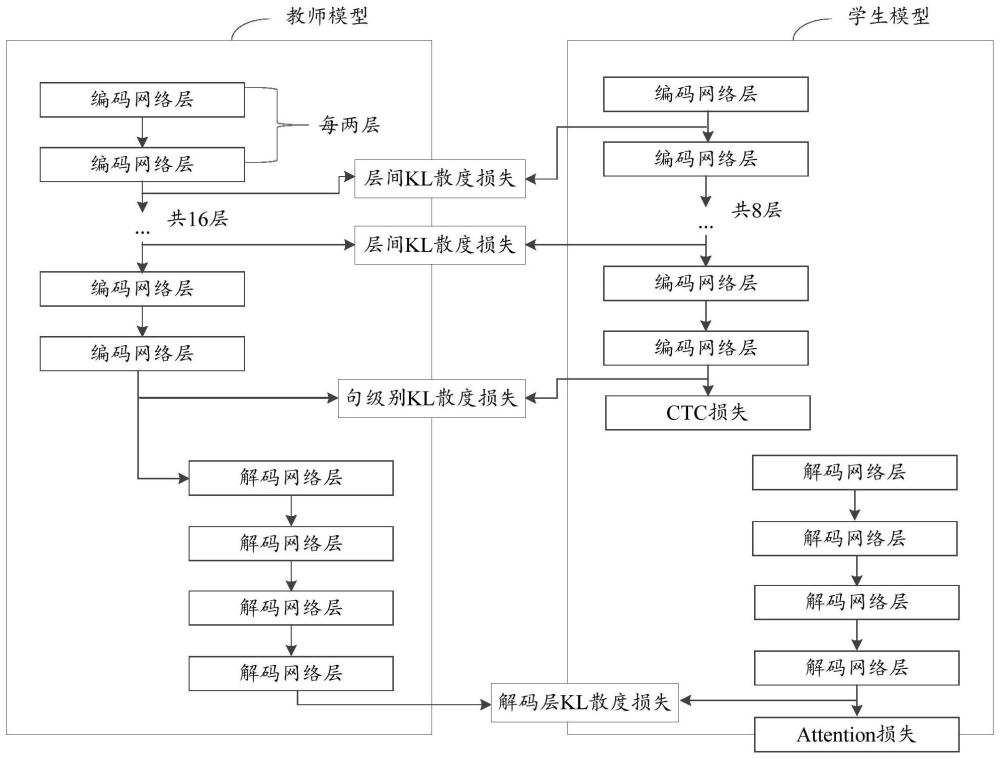
3、为解决该问题,如果仅仅考虑将较大的深度学习模型换为较小的深度学习模型进行训练(如将conformer 16层换为conformer 8层),较小的深度学习模型非常容易会因为参数量较小、特征表示能力不足,导致深度学习模型分类或预测准确性能低下,带来的问题就是虽然满足线上应用的实时性要求,但却无法满足准确性要求。
4、针对实时性和准确性难以兼顾的问题,比较好的解决办法是知识蒸馏。
5、知识蒸馏的原理,是利用训练完毕的大模型(又名教师模型)教参数量相对大模型较小的小模型(又名学生模型)——学生模型学习教师模型中的起主要正向作用的参数,这样使得学生模型在效率较高的同时,又能获得较优的拟合参数从而能保证较高的识别准确性。
6、现有技术中虽已经提出了一些通用场景下的知识蒸馏方法,但采用这样的方法训练得到的学生模型运用于前文所说的语音识别场景时,仍然存在识别准确性不够高的问题。
技术实现思路
1、本申请实施例提供一种模型训练方法,用以解决按照现有技术提供的知识蒸馏方法训练得到的学生模型运用于语音识别场景下时,所存在的识别准确性不够高的问题。
2、本申请实施例还提供一种模型训练装置、语音识别方法与装置、设备及计算机可读存储介质。
3、本申请实施例采用下述技术方案:
4、一种模型训练方法,包括:
5、获取数据样本;
6、将所述数据样本分别输入教师模型和学生模型,经所述教师模型的至少一层编码网络层对所述数据样本进行编码,得到第一编码特征集合,以及经所述学生模型的至少一层编码网络层对所述数据样本进行编码,得到第二编码特征集合;
7、根据所述第一编码特征集合和所述第二编码特征集合,确定第一kl损失;
8、根据所述第一kl损失、所述学生模型对应的分类损失,以及所述学生模型基于所述数据样本预测的类别分布相对于所述教师模型基于所述数据样本预测的类别分布的损失,调整所述学生模型的参数。
9、一种语音识别方法,包括:
10、获取待识别的语音数据;
11、将所述语音数据输入训练好的学生模型,以得到所述训练好的学生模型对所述语音数据进行识别所得到的文本序列;
12、所述训练好的学生模型,采用如上所述的模型训练方法得到。
13、一种模型训练装置,包括:
14、数据获取单元,用于获取数据样本;
15、数据输入单元,用于将所述数据样本分别输入教师模型和学生模型,经所述教师模型的至少一层编码网络层对所述数据样本进行编码,得到第一编码特征集合,以及经所述学生模型的至少一层编码网络层对所述数据样本进行编码,得到第二编码特征集合;
16、第一kl损失计算单元,用于根据所述第一编码特征集合和所述第二编码特征集合,确定第一kl损失;
17、参数调整单元,用于根据所述第一kl损失、所述学生模型对应的分类损失,以及所述学生模型基于所述数据样本预测的类别分布相对于所述教师模型基于所述数据样本预测的类别分布的损失,调整所述学生模型的参数。
18、一种语音识别装置,包括:
19、信号获取单元,用于获取待识别的语音数据;
20、识别单元,用于将所述语音数据输入训练好的学生模型,以得到所述训练好的学生模型对所述语音数据进行识别所得到的文本序列;
21、所述训练好的学生模型,采用如上所述的模型训练方法得到。
22、一种计算设备,包括:存储器及处理器,其中,所述存储器,用于存储计算机程序;所述处理器,与所述存储器耦合,用于执行所述存储器中存储的所述计算机程序,以用于执行如上所述的模型训练方法,或,用于执行如上所述的语音识别方法。
23、一种存储有计算机程序的计算机可读存储介质,所述计算机程序被计算机执行时能够实现如上所述的模型训练方法,或,能够实现如上所述的语音识别方法。
24、本申请实施例采用的上述至少一个技术方案能够达到以下有益效果:
25、现有技术在训练学生模型时所依据的总损失中,仅考虑了学生模型预测的类别分布相对于教师模型预测的类别分布的损失等,但并没有引入编码网络层对应的kl损失。而采用本申请实施例提供的方案,在总损失中,引入了根据第一编码特征集合和第二编码特征集合确定的第一kl损失,使得学生模型能够学习教师模型的编码网络层的编码输出,因此相对于现有技术,有效增加了学生模型在训练时可以获取到的信息,从而使得按照该方案训练得到的学生模型能够更好地实现对于教师模型的知识的迁移,提升了学生模型的识别准确性。
技术特征:
1.一种模型训练方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,经所述教师模型的至少一层编码网络层对所述数据样本进行编码,得到第一编码特征集合,以及经所述学生模型的至少一层编码网络层对所述数据样本进行编码,得到第二编码特征集合,包括:
3.如权利要求2所述的方法,其特征在于:
4.如权利要求3所述的方法,其特征在于:所述根据所述预设对应关系、所述第一编码特征集合、所述第二编码特征集合以及第一计算方式,计算每个目标第一kl损失,包括:
5.如权利要求3所述的方法,其特征在于:所述根据所述每个目标第一kl损失,确定第一kl损失;
6.如权利要求5所述的方法,其特征在于:
7.如权利要求1所述的方法,其特征在于:所述第一编码特征集合包括目标第一编码特征,所述第二编码特征集合包括目标第二编码特征,则,
8.如权利要求7所述的方法,其特征在于:
9.如权利要求1所述的方法,其特征在于,所述根据所述第一kl损失、所述学生模型的分类损失,以及所述学生模型针对所述数据样本预测的类别分布相对于所述教师模型针对所述数据样本预测的类别分布的损失,调整所述学生模型的参数,包括:
10.一种语音识别方法,其特征在于,包括:
11.一种模型训练装置,其特征在于,包括:
12.一种语音识别装置,其特征在于,包括:
13.一种计算设备,其特征在于,包括:存储器及处理器,其中,
14.一种存储有计算机程序的计算机可读存储介质,所述计算机程序被计算机执行时能够实现权利要求1~9任一权项所述的模型训练方法,或,能够实现权利要求10所述的语音识别方法。
技术总结
本申请公开一种模型训练方法、语音识别方法、装置、设备、计算机可读存储介质,用以解决按照现有技术训练得到的学生模型运用于语音识别等场景下时,所存在的识别准确性不够高的问题。训练方法包括:获取数据样本;经所述教师模型的至少一层编码网络层对所述数据样本进行编码,得到第一编码特征集合,以及经所述学生模型的至少一层编码网络层对所述数据样本进行编码,得到第二编码特征集合;根据所述第一编码特征集合和所述第二编码特征集合,确定第一KL损失;根据第一KL损失、学生模型对应的分类损失,以及学生模型基于数据样本预测的类别分布相对于教师模型基于数据样本预测的类别分布的损失,调整学生模型的参数。
技术研发人员:孟庆林,蒋宁,吴海英,刘敏,陈燕丽
受保护的技术使用者:马上消费金融股份有限公司
技术研发日:
技术公布日:2024/1/25
- 还没有人留言评论。精彩留言会获得点赞!