语音合成方法、装置、电子设备及存储介质与流程
本申请属于语音合成,具体涉及一种语音合成方法、装置、电子设备及存储介质。
背景技术:
1、如今,定制语音在不同应用场景中的应用吸引了越来越多公司的兴趣,例如个人助理、新闻广播和音频导航等应用场景,并在商业领域得到广泛支持。在定制语音中,基础从文本到语音(base text to speech,base tts)模型通常在很少的可用性自适应数据(通常数据只有几秒钟或者几分钟)上进行微调,便可得到能合成此说话人的tts模型。
2、而训练特定人音色的tts合成模型,此说话人的训练数据需要七八个小时,而每个小时语音加标注的采购费用较高,达到将近一万元,这对训练多个说话人(定制)的语音合成模型,成本较大,且在通过该模型合成语音时准确性较低。因此,在语音合成领域中,如何高效地合成特定说话人的语音成为当今研究的热点问题之一。
技术实现思路
1、本申请实施例提供一种语音合成方法、装置、电子设备及存储介质,可以节省特定说话人语音的合成时间,以及提高特定说话人语音合成的准确性。
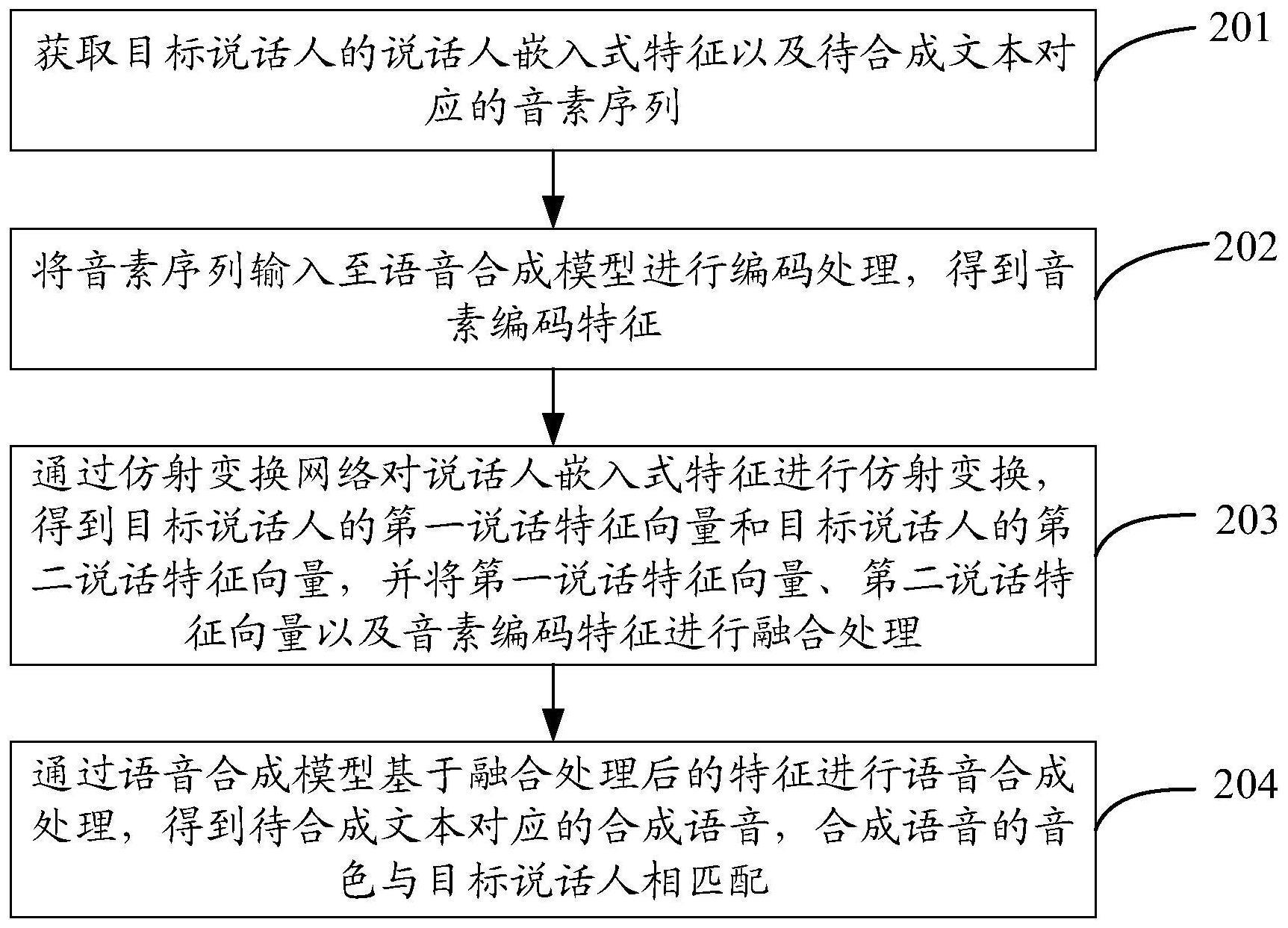
2、第一方面,本申请实施例提供了一种语音合成方法,包括:
3、获取目标说话人的说话人嵌入式特征以及待合成文本对应的音素序列;
4、将所述音素序列输入至语音合成模型进行编码处理,得到音素编码特征;
5、通过仿射变换网络对所述说话人嵌入式特征进行仿射变换,得到所述目标说话人的第一说话特征向量和所述目标说话人的第二说话特征向量,并将所述第一说话特征向量、所述第二说话特征向量以及所述音素编码特征进行融合处理;
6、通过所述语音合成模型基于所述融合处理后的特征进行语音合成处理,得到所述待合成文本对应的合成语音,所述合成语音的音色与所述目标说话人相匹配。
7、第二方面,本申请实施例另提供了一种语音合成装置,包括:
8、获取单元,用于获取目标说话人的说话人嵌入式特征以及待合成文本对应的音素序列;
9、处理单元,用于将所述音素序列输入至语音合成模型进行编码处理,得到音素编码特征;
10、所述处理单元,用于通过仿射变换网络对所述说话人嵌入式特征进行仿射变换,得到所述目标说话人的第一说话特征向量和所述目标说话人的第二说话特征向量,并将所述第一说话特征向量、所述第二说话特征向量以及所述音素编码特征进行融合处理;
11、合成单元,用于通过所述语音合成模型基于所述融合处理后的特征进行语音合成处理,得到所述待合成文本对应的合成语音,所述合成语音的音色与所述目标说话人相匹配。
12、第三方面,本申请实施例提供了一种电子设备,该电子设备包括处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如第一方面所述的方法的步骤。
13、第四方面,本申请实施例提供了一种计算机可读存储介质,该计算机可读存储介质上存储程序或指令,程序或指令被处理器执行时实现如第一方面的方法的步骤。
14、在本申请实施例中,通过获取目标说话人的说话人嵌入式特征以及待合成文本对应的音素序列;将所述音素序列输入至语音合成模型进行编码处理,得到音素编码特征;通过仿射变换网络对所述说话人嵌入式特征进行仿射变换,得到该目标说话人的第一说话特征向量和所述目标说话人的第二说话特征向量,并将第一说话特征向量、第二说话特征向量以及音素编码特征进行融合处理;通过语音合成模型基于融合处理后的特征进行语音合成处理,便可以得到与目标说话人的音素相匹配的待合成文本对应的合成语音。
15、在上述语音合成过程中,由于说话人嵌入式特征是从目标说话人的语音中得到,这使得融合第一说话人特征向量和第二说话人特征向量的融合处理后的特征更贴合目标说话人的音色,从而使得通过语音合成模型合成后的合成语音的音色与目标说话人相匹配,实现了在节省特定说话人语音的合成时间的同时,提高了合成语音的准确性,解决了现有的合成语音时准确性较低的问题。
技术特征:
1.一种语音合成方法,其特征在于,包括:
2.根据权利要求1所述的语音合成方法,其特征在于,所述仿射变换网络包括顺序连接的第一卷积层、激活层、位置编码器和第二卷积层;
3.根据权利要求2所述的语音合成方法,其特征在于,所述仿射变换网络还包括与所述第二卷积层连接的融合层;
4.根据权利要求1所述的语音合成方法,其特征在于,所述语音合成模型包括音素嵌入层和音素编码器;
5.根据权利要求1所述的语音合成方法,其特征在于,所述语音合成模型包括可变信息适配器和梅尔解码器;
6.根据权利要求1所述的语音合成方法,其特征在于,所述语音合成模型是基于训练数据集和所述仿射变换网络的输出训练得到的,所述仿射变换网络的输入包括一个说话人的说话人嵌入式特征,所述训练数据集包括多个训练样本对,一个训练样本对包括属于对应说话人的训练文本对应的音素序列和所述说话人的标准语音数据。
7.根据权利要求1所述的语音合成方法,其特征在于,所述获取目标说话人的说话人嵌入式特征,包括:
8.一种语音合成装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括处理器,存储器及存储在所述存储器上并可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如权利要求1-7任一项所述的语音合成方法的步骤。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现如权利要求1-7任一项所述的语音合成方法的步骤。
技术总结
本申请公开了一种语音合成方法、装置、电子设备及存储介质,方法包括:获取目标说话人的说话人嵌入式特征以及待合成文本对应的音素序列;将所述音素序列输入至语音合成模型进行编码处理,得到音素编码特征;通过仿射变换网络对所述说话人嵌入式特征进行仿射变换,得到所述目标说话人的第一说话特征向量和所述目标说话人的第二说话特征向量,并将所述第一说话特征向量、所述第二说话特征向量以及所述音素编码特征进行融合处理;通过所述语音合成模型基于所述融合处理后的特征进行语音合成处理,得到所述待合成文本对应的合成语音,所述合成语音的音色与所述目标说话人相匹配。
技术研发人员:刘鹏飞,蒋宁,吴海英,刘敏
受保护的技术使用者:马上消费金融股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!