一种基于树莓派的轻量级语音输入实时检测方法
本发明属于模式识别,具体涉及一种轻量级语音输入实时检测方法。
背景技术:
1、随着语音交互需求的日益增长,声纹识别技术不断发展。传统的声纹识别技术通常基于频谱图或传统特征进行,能够以较快的速度进行声音特征的提取。该技术通常应用在手机或边缘设备,用于语音唤醒,激活后续的语音交互功能。随着神经网络框架的发展,现阶段主流的声纹识别通常基于神经网络进行,最常用的lstm网络能够提取时序相关的特征,因而比较适合语音的处理,被广泛应用在主流的语音处理网络中。由于lstm网络参数较多,且运算结构比较复杂,在业界前沿有着较高的精度和效率,但在资源受限的边缘设备(如树莓派)上运行时,无法满足实时性的需求。
2、为了能基于树莓派构建语音唤醒的智能对话机器人,且能支持离线唤醒,需要在树莓派端对实时语音进行处理,并能响应用户的唤醒行为,从而提高交互体验。本发明旨在提出一种基于树莓派的轻量级语音输入实时检测方法,能在树莓派的硬件基础上,构建树莓派端离线可用的实时语音唤醒模块与语音输入提取模块,使其具有更强的实时性与更低的网络环境需求,以提供更优的交互体验。
技术实现思路
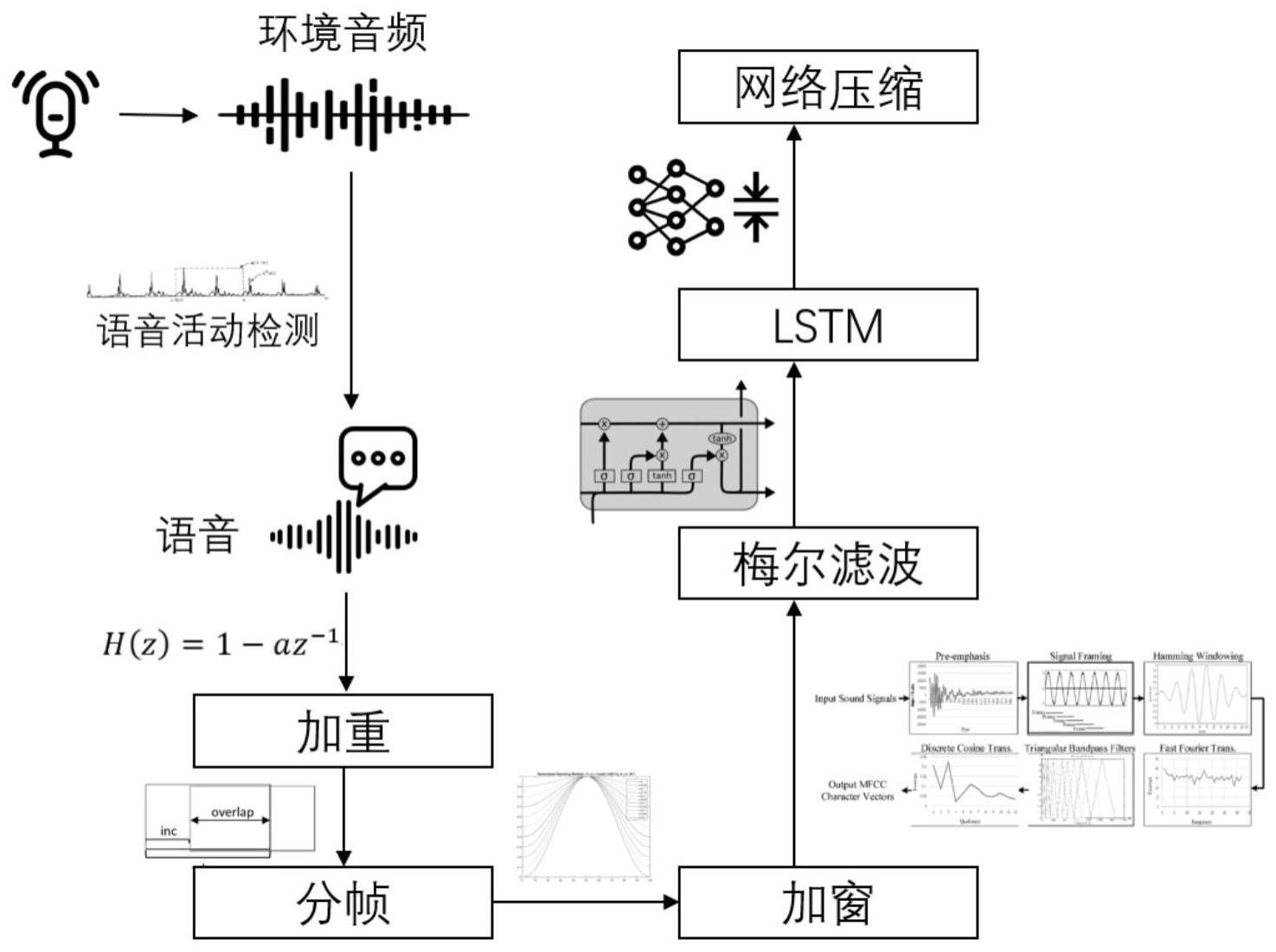
1、为了克服现有技术的不足,本发明提供了一种基于树莓派的轻量级语音输入实时检测方法,在树莓派端使用麦克风对环境音频进行录制,在用户说话时对语音声纹与预设声纹进行对比,以判断是否唤醒语音录制功能,进行后续语音交互。本发明利用以下原理:(1)基于短时能量的音频人声检测,用于低功耗从环境音频中检测是否含有人声;(2)基于lstm神经网络的人声声纹提取,将时域的音频信号转换并处理成基于频域的声纹特征;(3)适用于树莓派端的神经网络轻量化技术,优化网络体积与推理时延,提高在树莓派端运行的实时性。本发明构建树莓派端离线可用的实时语音唤醒模块与语音输入提取模块,使其具有更强的实时性与更低的网络环境需求,以提供更优的交互体验。
2、本发明解决其技术问题所采用的技术方案包括如下步骤:
3、步骤1:利用树莓派麦克风捕获环境有效音频;
4、步骤2:语音活动检测;基于librosa工具包根据短时能量区分语音信号和非语音信号,从而提取出原始语音信号中含有人类语音的部分;
5、步骤3:音频预处理;
6、首先在起始段对语音信号进行预加重操作,即将信号通过一阶有限冲击响应高通数字滤波器:
7、h(z)=1-az-1
8、步骤4:分帧加窗;
9、将信号先以一定的时间间隔进行拆分,再对信号乘以窗函数,提高变换结果的分辨率;
10、步骤5:特征提取;
11、基于语音信号进行特征提取,用来表示语音的音色特征;使用梅尔标度滤波器处理语音信号,将语音信号时频谱转换为梅尔谱,其与普通频率的对应关系为:
12、
13、步骤6:将提取得到的特征送入lstm网络中,以计算出语音嵌入矢量,即声纹ck,此后基于声纹计算相似度,判断是否匹配;
14、步骤7:对训练成功的lstm神经网络进行结构化剪枝与知识蒸馏,完成语音输入实时检测。
15、优选地,所述窗函数为汉明窗口。
16、本发明的有益效果如下:
17、本发明在树莓派的硬件基础上,构建树莓派端离线可用的实时语音唤醒模块与语音输入提取模块,使其具有更强的实时性与更低的网络环境需求,以提供更优的交互体验。
技术特征:
1.一种基于树莓派的轻量级语音输入实时检测方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于树莓派的轻量级语音输入实时检测方法,其特征在于,所述窗函数为汉明窗口。
技术总结
本发明公开了一种基于树莓派的轻量级语音输入实时检测方法,在树莓派端使用麦克风对环境音频进行录制,在用户说话时对语音声纹与预设声纹进行对比,以判断是否唤醒语音录制功能,进行后续语音交互。本发明利用以下原理:(1)基于短时能量的音频人声检测,用于低功耗从环境音频中检测是否含有人声;(2)基于LSTM神经网络的人声声纹提取,将时域的音频信号转换并处理成基于频域的声纹特征;(3)适用于树莓派端的神经网络轻量化技术,优化网络体积与推理时延,提高在树莓派端运行的实时性。本发明构建树莓派端离线可用的实时语音唤醒模块与语音输入提取模块,使其具有更强的实时性与更低的网络环境需求,以提供更优的交互体验。
技术研发人员:郭斌,刘宇博,邱晨,方禹杨,於志文,曾亚庭
受保护的技术使用者:西北工业大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!