预测用于训练语音合成神经网络的频谱表示的制作方法
本说明书涉及使用神经网络生成音频数据。
背景技术:
1、神经网络是机器学习模型,它采用非线性单元的一个或多个层来针对接收到的输入预测输出。一些神经网络除了输出层之外还包括一个或多个隐藏层。每个隐藏层的输出用作网络中一个或多个其他层(即,一个或多个其他隐藏层、输出层或两者)的输入。网络的每一层根据相应参数集的当前值从接收到的输入生成输出。
技术实现思路
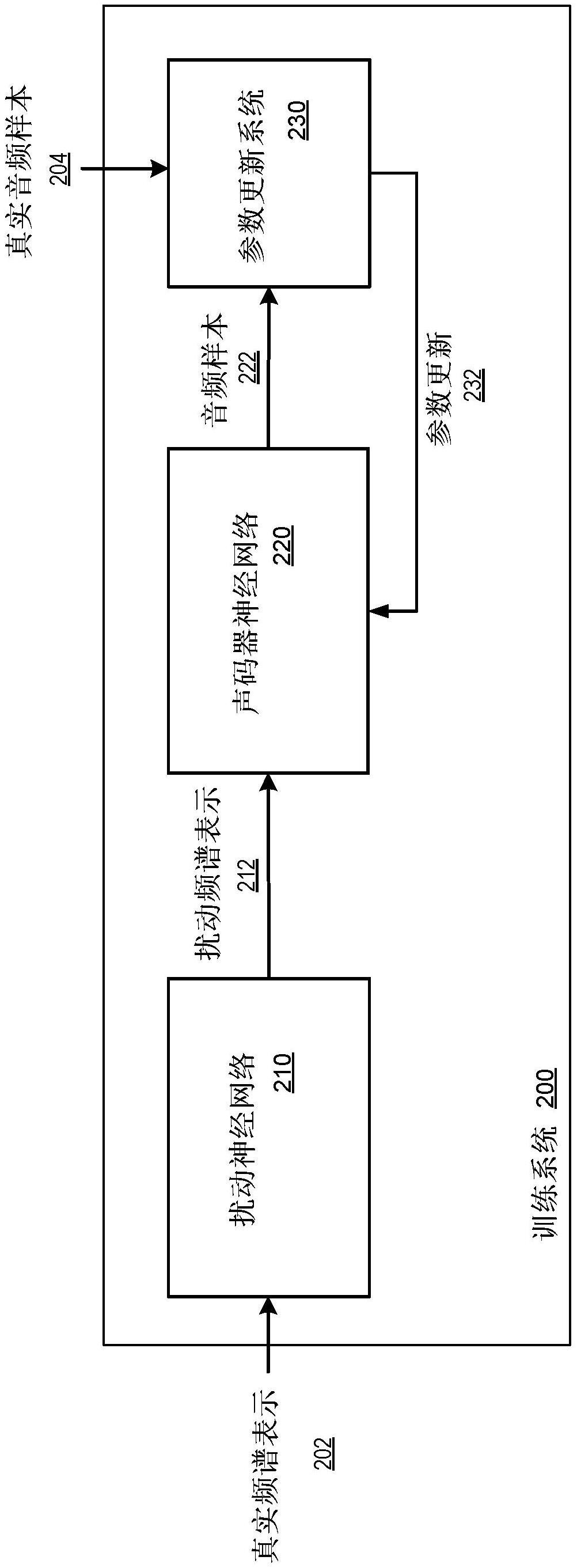
1、本说明书描述了一种在一个或多个位置中的一个或多个计算机上实现为计算机程序的系统,该系统被配置为训练神经网络以使用音频样本的预测频谱表示来生成音频样本。
2、在本说明书中,音频样本的频谱表示是频率谱随时间变化时的音频样本的频率谱的表示。例如,在音频样本中的多个时间点中的每一个处,频谱表示可以包括预定频率集中的每个频率的相应幅度值。在本说明书中,频谱图是音频样本的频谱表示的视觉表示。例如,频谱图可以是二维图像,其中时间沿一个轴变化而频率沿另一轴变化;对于图像中的每个元素(例如,像素),频谱图可以包括对应时间处对应频率的幅度值的视觉表示,例如,来自表示一系列对应的可能的幅度值的一系列颜色的表示幅度值的颜色。
3、在神经网络(本文有时称为“声码器”神经网络)被训练之后,可以将声码器神经网络部署在包括第二神经网络(本文有时称为“频谱表示”神经网络)的语音合成系统中,该第二神经网络被配置为处理文本输入并生成文本输入的言语表达(或发声)的预测频谱表示。声码器神经网络然后可以获取由频谱表示神经网络生成的预测频谱表示,并且处理预测频谱表示以生成文本输入的言语表达的音频样本。因此,语音合成系统被配置为接收系统输入,该系统输入包括表征文本序列的条件文本输入。语音合成系统可以处理条件文本输入以生成与输入文本相对应的音频数据,即,表征说出输入文本的说话者的音频数据。
4、在一些实施方式中,频谱表示神经网络可能需要大量的时间和计算资源来被训练以生成特定声音或声音类型的预测频谱表示。也就是说,在这些实施方式中,为了生成其中特定声音用言语表达文本输入的音频样本的预测频谱表示,必须针对特定声音专门训练频谱表示神经网络。该训练过程通常还需要与特定声音相对应的大量训练数据,即用言语表达不同文本输入的特定声音的真实(ground truth)音频样本。然而,大量的训练数据往往不能用于除少数声音以外的任何声音。因此,在一些这样的实施方式中,频谱表示神经网络仅在少数声音(例如,3、5、10、20、50或100个声音)上进行训练,即,仅能够生成由那些声音用言语表达的音频样本的预测频谱表示。
5、另一方面,声码器神经网络可以跨声音进行通用训练。也就是说,训练系统不需要分别为每个不同的声音训练声码器神经网络,而是可以使用包括对应于多个声音的训练示例(例如,真实音频样本和对应的频谱表示输入的对)的训练集来同时针对多个声音训练声码器神经网络。因此,训练集可以包括与相对罕见的声音相对应的训练示例,即使训练系统只能访问少数这样的训练示例。事实上,在一些实施方式中,例如,如果在足够广泛的声音上训练声码器神经网络,则声码器神经网络可以被配置为能够在训练完成之后接收与不在训练数据集中的新声音相对应的频谱表示,并为新声音生成准确的音频样本。
6、给定大量音频样本,训练系统可以例如通过使用带通滤波器或傅立叶变换处理音频样本来生成音频样本的真实频谱表示。然而,在训练期间提供真实频谱表示作为声码器神经网络的训练输入可能会在部署声码器神经网络后产生次优结果,因为声码器神经网络在推理时间不接收真实频谱表示。相反,声码器神经网络接收由频谱表示神经网络生成的预测频谱表示。尽管可以训练频谱表示神经网络来生成高度准确的预测频谱表示,但是这些预测频谱表示并不完美,并且可能与对应的真实频谱表示有细微的差异。在训练神经网络时,提供与神经网络在推理时间接收的内容相匹配的训练输入非常重要。
7、因此,声码器神经网络的训练系统有两个相互冲突的要求。首先,声码器神经网络必须接收与部署后接收的输入相匹配的训练输入;也就是说,声码器神经网络必须接收由频谱表示神经网络生成的频谱表示或者接收与由频谱表示神经网络生成的预测频谱表示非常相似的频谱表示。其次,声码器神经网络必须接收与各种不同声音相对应的训练输入,而频谱表示神经网络可能由于上述限制而无法生成这些训练输入。
8、使用本说明书中描述的技术,训练系统可以通过使用第三神经网络(本文有时称为“扰动”神经网络)处理音频样本的真实频谱表示以生成音频样本的更新频谱表示(本文有时称为“扰动”频谱表示),来生成声码器神经网络的训练输入。扰动频谱表示与由频谱表示神经网络生成的预测频谱表示类似,因此是声码器神经网络的适当训练输入。换言之,扰动神经网络可以被配置为处理真实频谱表示并生成具有与由频谱表示神经网络生成的频谱表示的特性相同的特性的扰动频谱表示。然后,训练系统可以使用扰动频谱表示以及对应的真实音频样本来执行声码器神经网络的监督训练。训练完成后,声码器神经网络可以与如上所述的频谱表示神经网络一起部署;也就是说,通常在推理时间不会在语音合成系统中部署扰动神经网络。
9、在一些实施方式中,扰动神经网络被显式训练以生成模拟由频谱表示神经网络生成的预测频谱表示的扰动频谱表示。在一些其他实施方式中,扰动神经网络没有被显式训练来以这种方式生成扰动频谱表示。例如,扰动神经网络可以是自动编码器神经网络,其被配置为处理真实频谱表示并生成真实频谱表示的嵌入,然后使用该嵌入来重构频谱表示。由频谱表示神经网络生成的预测频谱表示可以比对应的真实频谱表示更接近地相似于由扰动神经网络生成的重构频谱表示,因此重构频谱表示可以在声码器神经网络的训练期间用作扰动频谱表示。
10、本说明书中描述的主题可以在特定实施例中实现,以实现以下一个或多个优点。许多现有的语音合成系统仅限于生成表征一个或少数预定声音的音频样本。使用本说明书中描述的技术,训练系统可以将声码器神经网络训练为真正通用的,即能够生成表征任何声音的音频样本,甚至是声码器神经网络的训练数据集中未表示的声音。在一些实施方式中,经过训练的声码器神经网络可以与多种不同频谱表示神经网络中的任意一种一起部署(例如,甚至是在声码器神经网络的训练和部署之后训练的频谱表示神经网络),并且从其中任何一个接收频谱表示时生成高质量音频样本。
11、本说明书的主题的一个或多个实施例的细节在附图和下面的描述中阐述。本主题的其他特征、方面和优点将从描述、附图和权利要求中变得显而易见。
技术特征:
1.一种训练第一神经网络以处理音频样本的频谱表示并生成音频样本的预测的方法,
2.根据权利要求1所述的方法,其中,所述第三神经网络是预训练的自动编码器神经网络,其已被训练以执行包括以下的操作:
3.根据权利要求1或2中任一项所述的方法,其中,所述第三神经网络已被使用训练示例来训练,每个训练示例包括i)表示特定文本输入的发声的输入音频样本的真实频谱表示,以及ii)由所述第二神经网络响应于处理所述特定文本输入而生成的预测频谱表示。
4.根据权利要求1-3中任一项所述的方法,其中,所述第一神经网络被配置为生成表征任何声音的音频样本。
5.根据权利要求4所述的方法,其中,所述第二神经网络仅被配置为生成对应于预定声音集的预测频谱表示。
6.根据权利要求1-5中任一项所述的方法,其中,所述第三神经网络已被通过执行包括以下的操作来训练:
7.根据权利要求1-6中任一项所述的方法,其中,使用所述更新频谱表示来训练所述第一神经网络包括:
8.一种用于使用第一神经网络生成音频样本的方法,所述第一神经网络已经使用前述权利要求中任一项所述的方法进行训练。
9.根据权利要求8所述的方法,还包括:
10.根据权利要求8或9中任一项所述的方法,还包括:
11.一种系统,包括一个或多个计算机和一个或多个存储指令的存储设备,所述指令在由所述一个或多个计算机执行时使得所述一个或多个计算机施行根据权利要求1-10中任一项所述的方法。
12.一个或多个存储指令的非暂时性计算机存储介质,所述指令在由一个或多个计算机执行时,使所述一个或多个计算机施行权利要求1-10中任一项所述的操作。
技术总结
用于训练神经网络执行语音合成的方法、系统和装置,包括编码在计算机存储介质上的计算机程序。该方法之一包括:获取用于训练第一神经网络以处理音频样本的频谱表示并生成音频样本的预测的训练数据集,其中,在训练之后,第一神经网络从第二神经网络获取音频样本的频谱表示;对于训练数据集中的多个音频样本:生成音频样本的真实频谱表示;以及,使用第三神经网络处理真实频谱表示以生成音频样本的更新频谱表示;以及,使用更新频谱表示来训练第一神经网络,其中,第三神经网络被配置为生成与第二神经网络生成的频谱表示相似的更新频谱表示。
技术研发人员:诺曼·卡萨格兰德
受保护的技术使用者:渊慧科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!