使用反上下文示例来更新自动语音辨识系统的制作方法
本公开涉及生成和使用反上下文示例来更新自动语音辨识(asr)系统。
背景技术:
1、asr系统提供通常在移动装置和/或其他装置中使用的技术。一般来说,asr系统尝试提供用户对装置说出的内容的准确转录。然而,在一些情况下,asr系统生成可能与用户预期或实际说出的内容不匹配的转录。在这些情况下,用户可以通过提供校正转录的用户输入来校正该转录。
技术实现思路
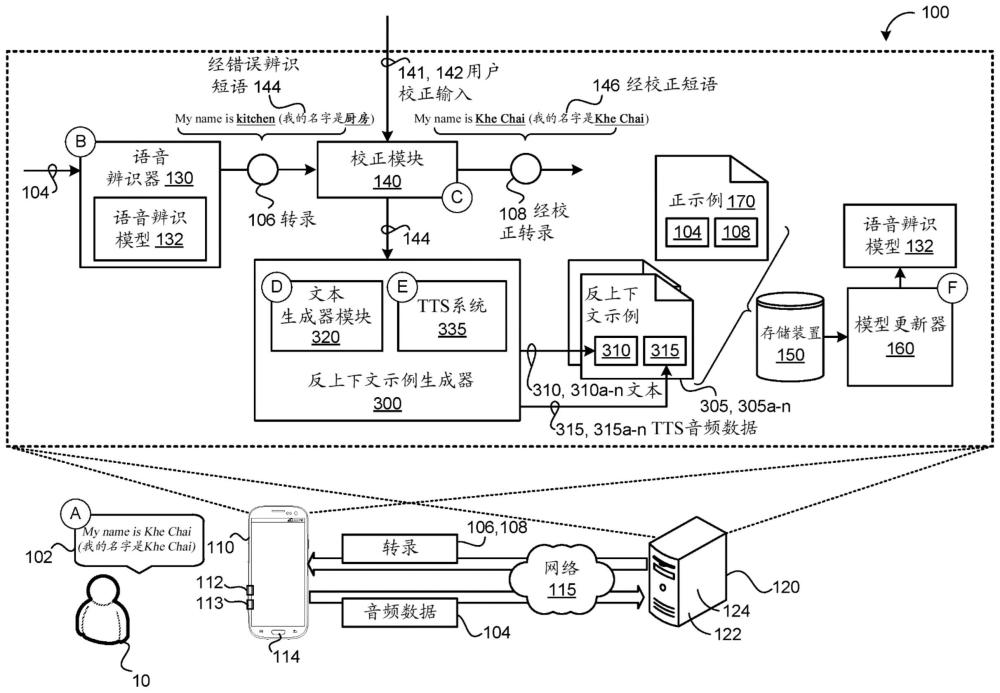
1、本公开的一个方面提供了一种用于使用反上下文示例来更新asr系统的方法,该方法当在数据处理硬件上执行时使该数据处理硬件执行操作。操作包括接收与用户所说出的话语相对应的音频数据,并且使用语音辨识模型处理该音频数据以生成该话语的转录。此处,转录包括由语音辨识模型在转录中错误辨识的经错误辨识短语。操作还包括接收经用户校正的文本,该经用户校正的文本包括替换在转录中错误辨识的经错误辨识短语的经校正短语。操作进一步包括基于经错误辨识短语,生成反上下文示例。此处,反上下文示例包括反上下文文本,该反上下文文本包含与对应于反上下文文本的合成语音表示的文本到语音(tts)音频数据配对的经错误辨识短语。操作还包括基于反上下文示例将语音辨识模型个性化。
2、本公开的实现方式可包括以下可选特征中的一个或多个特征。在一些实现方式中,操作进一步包括在用户装置的图形用户界面上显示转录。在一些示例中,接收经用户校正的文本包括:接收用户输入,该用户输入指示选择图形用户界面上显示的转录中的经错误辨识短语,以及从用户接收该经用户校正的文本的输入。在这些示例中,接收经用户校正的文本的输入包括接收由用户提供的经用户校正的文本的文本输入。替代地,接收经用户校正的文本的输入包括接收由用户装置捕获的与用户说出经校正短语的一个或多个字母相对应的流式音频。
3、在一些实现方式中,生成反上下文示例包括基于经用户校正的文本,使用语言模型确定包含经用户校正的文本的反上下文文本。在这些实现方式中,操作进一步包括将反上下文文本提供到tts系统。此处,tts系统被配置为将反上下文文本转换为包括反上下文文本的合成语音表示的tts音频数据。在一些示例中,操作还包括确定用户所说出的话语的域。此处,语言模型在与用户所说出的话语的域相关联的训练文本话语上进行训练。在这些示例中,话语的域包括长格式语音域,并且训练文本话语是从输入法编辑器(ime)文本源或听写文本源中的至少一者中采样的。替代地,话语的域包括查询域;并且训练文本话语是从查询日志中采样的。
4、在一些实现方式中,将语音辨识模型个性化包括通过教导语音辨识模型学习如何从tts音频数据中预测反上下文文本,在反上下文示例上训练语音辨识模型。在一些示例中,操作进一步包括通过在包括与音频数据配对的经用户校正的文本的正训练示例上训练语音辨识模型,以教导语音辨识模型学习如何从与用户所说出的话语相对应的音频数据中预测经用户校正的文本,来将语音辨识模型个性化。在一些实现方式中,将语音辨识模型个性化包括执行评估例程,以通过以下方式测试语音辨识模型的性能:使用语音辨识模型处理tts音频数据以生成语音辨识结果;以及基于反上下文文本来确定语音辨识结果是否满足接受标准;以及以下中的一个:当语音辨识结果满足接受标准时接受语音辨识模型,或者当语音辨识结果未能满足接受标准时拒绝语音辨识模型。
5、本公开的另一方面提供了一种用于使用反上下文示例来更新asr系统的系统。该系统包括数据处理硬件和与该数据处理硬件通信的存储器硬件。存储器硬件存储指令,所述指令在数据处理硬件上执行时使数据处理硬件执行操作,所述操作包括:接收与用户所说出的话语相对应的音频数据;以及使用语音辨识模型处理音频数据以生成话语的转录。此处,转录包括由语音辨识模型在转录中错误辨识的经错误辨识短语。操作还包括接收经用户校正的文本,该经用户校正的文本包括替换在转录中错误辨识的经错误辨识短语的经校正短语。操作进一步包括基于经错误辨识短语,生成反上下文示例。此处,反上下文示例包括反上下文文本,该反上下文文本包含与对应于反上下文文本的合成语音表示的文本到语音(tts)音频数据配对的经错误辨识短语。操作还包括基于反上下文示例将语音辨识模型个性化。
6、本公开的实现方式可包括以下可选特征中的一个或多个特征。在一些实现方式中,操作进一步包括在用户装置的图形用户界面上显示转录。在一些示例中,接收经用户校正的文本包括:接收用户输入,该用户输入指示选择图形用户界面上显示的转录中的经错误辨识短语的用户输入,以及从用户接收该经用户校正的文本的输入。在这些示例中,接收经用户校正的文本的输入包括接收由用户提供的经用户校正的文本的文本输入。替代地,接收经用户校正的文本的输入包括接收由用户装置捕获的与用户说出经校正短语的一个或多个字母相对应的流式音频。
7、在一些实现方式中,生成反上下文示例包括基于经用户校正的文本,使用语言模型确定包含经用户校正的文本的反上下文文本。在这些实现方式中,操作进一步包括将反上下文文本提供到tts系统。此处,tts系统被配置为将反上下文文本转换为包括反上下文文本的合成语音表示的tts音频数据。在一些示例中,操作还包括确定用户所说出的话语的域。此处,语言模型在与用户所说出的话语的域相关联的训练文本话语上进行训练。在这些示例中,话语的域包括长格式语音域,并且训练文本话语是从输入法编辑器(ime)文本源或听写文本源中的至少一者中采样的。替代地,话语的域包括查询域;并且训练文本话语是从查询日志中采样的。
8、在一些实现方式中,将语音辨识模型个性化包括通过教导语音辨识模型学习如何从tts音频数据中预测反上下文文本,在反上下文示例上训练语音辨识模型。在一些示例中,操作进一步包括通过在包括与音频数据配对的经用户校正的文本的正训练示例上训练语音辨识模型,以教导语音辨识模型学习如何从与用户所说出的话语相对应的音频数据中预测经用户校正的文本,来将语音辨识模型个性化。在一些实现方式中,将语音辨识模型个性化包括执行评估例程,以通过以下方式测试语音辨识模型的性能:使用语音辨识模型处理tts音频数据以生成语音辨识结果;以及基于反上下文文本来确定语音辨识结果是否满足接受标准;以及以下中的一个:当语音辨识结果满足接受标准时接受语音辨识模型,或者当语音辨识结果未能满足接受标准时拒绝语音辨识模型。
9、本公开的一个或多个实现方式的细节在附图和下面的描述中阐述。根据说明书和附图以及权利要求,其他方面、特征和优点将显而易见。
技术特征:
1.一种计算机实现的方法(400),所述计算机实现的方法在数据处理硬件(510)上执行,使所述数据处理硬件(510)执行操作,所述操作包括:
2.如权利要求1所述的计算机实现的方法(400),其中所述操作进一步包括:
3.如权利要求2所述的计算机实现的方法(400),其中接收所述经用户校正的文本(141)的所述输入包括接收由所述用户(10)提供的所述经用户校正的文本(141)的文本输入。
4.如权利要求2所述的计算机实现的方法(400),其中接收所述经用户校正的文本(141)的所述输入包括接收由所述用户装置(110)捕获的与所述用户(10)说出所述经校正短语(146)的一个或多个字母相对应的流式音频。
5.如权利要求1至4中任一项所述的计算机实现的方法(400),其中生成所述反上下文示例(305)包括:
6.如权利要求5所述的计算机实现的方法(400),其中所述操作进一步包括:
7.如权利要求6所述的计算机实现的方法(400),其中:
8.如权利要求6所述的计算机实现的方法(400),其中:
9.如权利要求1至8中任一项所述的计算机实现的方法(400),其中将所述语音辨识模型(132)个性化包括通过教导所述语音辨识模型(132)学习如何从所述tts音频数据(315)中预测所述反上下文文本(310),在所述反上下文示例(305)上训练所述语音辨识模型(132)。
10.如权利要求1至9中任一项所述的计算机实现的方法(400),其中所述操作进一步包括通过在包括与所述音频数据(104)配对的所述经用户校正的文本(141)的正训练示例(170)上训练所述语音辨识模型(132),以教导所述语音辨识模型(132)学习如何从与所述用户(10)所说出的所述话语(102)相对应的所述音频数据(104)中预测所述经用户校正的文本(141),来将所述语音辨识模型(132)个性化。
11.如权利要求1至10中任一项所述的计算机实现的方法(400),其中将所述语音辨识模型(132)个性化包括执行评估例程以通过以下方式测试所述语音辨识模型(132)的性能:
12.一种系统(100),包括:
13.如权利要求12所述的系统(100),其中所述操作进一步包括:
14.如权利要求13所述的系统(100),其中接收所述经用户校正的文本(141)的所述输入包括接收由所述用户(10)提供的所述经用户校正的文本(141)的文本输入。
15.如权利要求13所述的系统(100),其中接收所述经用户校正的文本(141)的所述输入包括接收由所述用户装置(110)捕获的与所述用户(10)说出所述经校正短语(146)的一个或多个字母相对应的流式音频。
16.如权利要求12至15中任一项所述的系统(100),其中生成所述反上下文示例包括:
17.如权利要求16所述的系统(100),其中所述操作进一步包括:
18.如权利要求17所述的系统(100),其中:
19.如权利要求17所述的系统(100),其中:
20.如权利要求12至19中任一项所述的系统(100),其中将所述语音辨识模型(132)个性化包括通过教导所述语音辨识模型(132)学习如何从所述tts音频数据(315)中预测所述反上下文文本,在所述反上下文示例上训练所述语音辨识模型(132)。
21.如权利要求12至20中任一项所述的系统(100),其中所述操作进一步包括通过在包括与所述音频数据(104)配对的所述经用户校正的文本(141)的正训练示例(170)上训练所述语音辨识模型(132),以教导所述语音辨识模型(132)学习如何从与所述用户(10)所说出的所述话语(102)相对应的所述音频数据(104)中预测所述经用户校正的文本(141),来将所述语音辨识模型(132)个性化。
22.如权利要求12至21中任一项所述的系统(100),其中将所述语音辨识模型(132)个性化包括执行评估例程以通过以下方式测试所述语音辨识模型(132)的性能:
技术总结
一种用于使用反语境示例来将语音辨识模型(132)个性化的方法(400)包括接收与用户(10)所说出的话语(102)相对应的音频数据(104),并且使用该语音辨识模型处理该音频数据以生成该话语的转录(106)。该转录包括由该语音辨识模型在该转录中错误辨识的经错误辨识短语(144)。该方法还包括接收经用户校正的文本(141),该经用户校正的文本包括替换该转录中错误辨识的该经错误辨识短语的经校正短语(146)。基于该经错误辨识短语,该方法包括生成反上下文示例(305),该反上下文示例包括反上下文文本(310),该反上下文文本包含与对应于该反上下文文本的合成语音表示的文本到语音(TTS)音频数据(315)配对的该经错误辨识短语。该方法还包括基于该反上下文示例将该语音辨识模型个性化。
技术研发人员:K·C·沈,M·V·蔡,R·马修斯,M·陈,D·齐夫科维奇
受保护的技术使用者:谷歌有限责任公司
技术研发日:
技术公布日:2025/4/10
- 还没有人留言评论。精彩留言会获得点赞!