语音信号处理方法、装置、可读存储介质及电子设备与流程
本公开涉及计算机,尤其是一种语音信号处理方法、装置、计算机可读存储介质及电子设备。
背景技术:
1、传统的语音识别技术仅对语音信号进行处理以得到识别结果,这种语音识别方法在语音清晰的环境下识别效果较好。然而,在一些高噪声等复杂环境下,传统的语音识别技术的识别率会迅速下降。为了提高语音识别率,目前存在借助唇部动作视频协助进行语音识别的多模态语音识别方法,在一定程度上提高了高噪声场景下语音的识别率。
2、但是,在实时语音交互系统中,在用户的脸部被遮挡、脸部图像不清晰等情况下,基于图像识别得到的视觉特征成为无效的干扰输入,多模态语音识别方法的性能会出现显著下降,因此在视觉特征无效的情况下,如何将无效特征去除,只对有效的语音信号进行识别是需要解决的问题。
技术实现思路
1、为了解决上述技术问题,提出了本公开。本公开的实施例提供了一种语音信号处理方法、装置、计算机可读存储介质及电子设备。
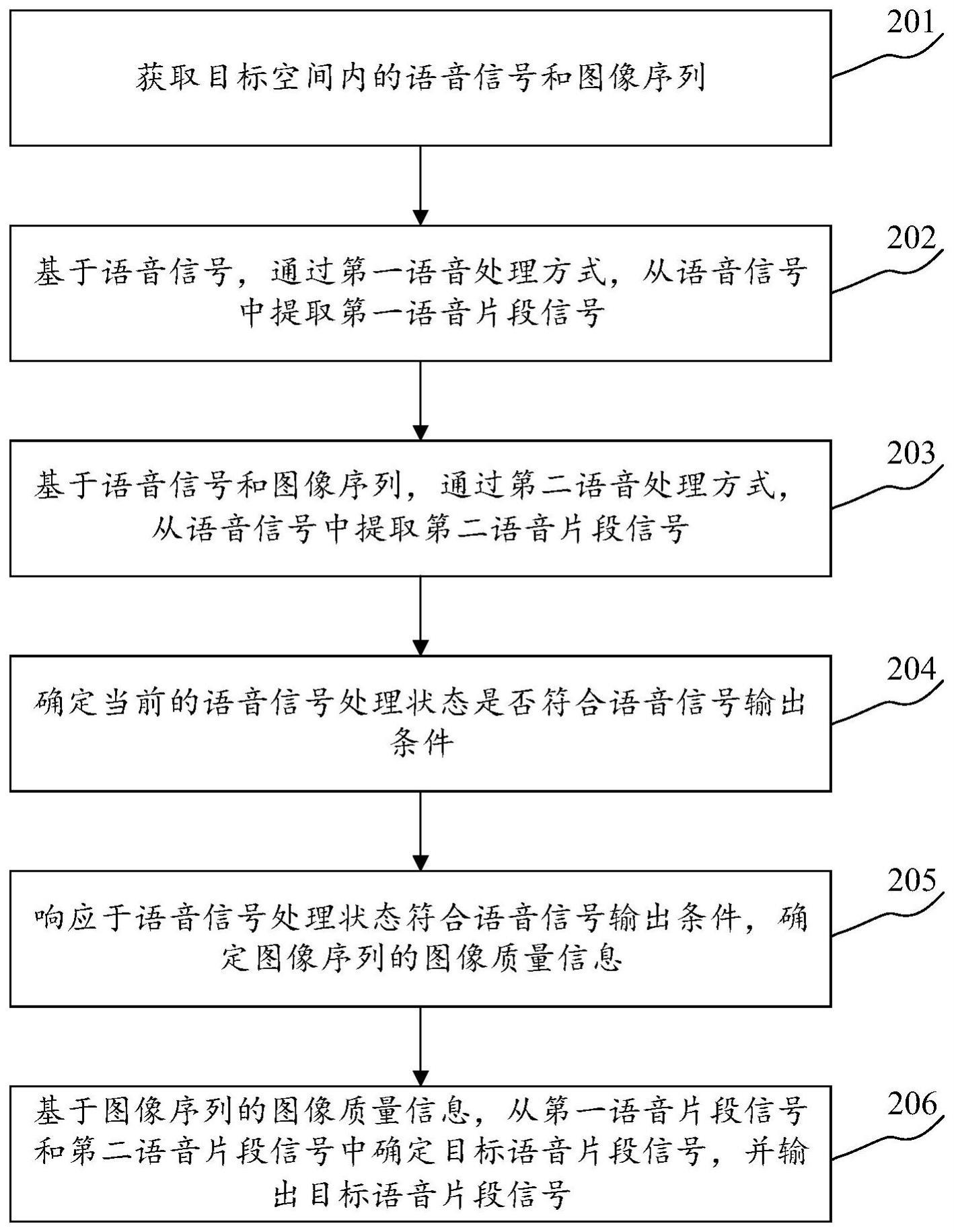
2、本公开的实施例提供了一种语音信号处理方法,该方法包括:获取目标空间内的语音信号和图像序列;基于语音信号,通过第一语音处理方式,从语音信号中提取第一语音片段信号;基于语音信号和图像序列,通过第二语音处理方式,从语音信号中提取第二语音片段信号;确定当前的语音信号处理状态是否符合语音信号输出条件;响应于语音信号处理状态符合语音信号输出条件,确定图像序列的图像质量信息;基于图像序列的图像质量信息,从第一语音片段信号和第二语音片段信号中确定目标语音片段信号,并输出目标语音片段信号。
3、根据本公开实施例的另一个方面,提供了一种语音信号处理装置,该装置包括:获取模块,用于获取目标空间内的语音信号和图像序列;第一提取模块,用于基于语音信号,通过第一语音处理方式,从语音信号中提取第一语音片段信号;第二提取模块,用于基于语音信号和图像序列,通过第二语音处理方式,从语音信号中提取第二语音片段信号;第一确定模块,用于确定当前的语音信号处理状态是否符合语音信号输出条件;第二确定模块,用于响应于语音信号处理状态符合语音信号输出条件,确定图像序列的图像质量信息;输出模块,用于基于图像序列的图像质量信息,从第一语音片段信号和第二语音片段信号中确定目标语音片段信号,并输出目标语音片段信号。
4、根据本公开实施例的另一个方面,提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序用于执行上述语音信号处理方法。
5、根据本公开实施例的另一个方面,提供了一种电子设备,电子设备包括:处理器;用于存储处理器可执行指令的存储器;处理器,用于从存储器中读取可执行指令,并执行指令以实现上述语音信号处理方法。
6、基于本公开上述实施例提供的语音信号处理方法、装置、计算机可读存储介质及电子设备,基于语音信号,通过第一语音处理方式,从语音信号中提取第一语音片段信号,基于语音信号和图像序列,通过第二语音处理方式,从语音信号中提取第二语音片段信号,然后响应于当前的语音信号处理状态符合语音信号输出条件,确定图像序列的图像质量信息,最后基于图像序列的图像质量信息,从第一语音片段信号和第二语音片段信号中确定目标语音片段信号,并输出目标语音片段信号。本公开的实施例实现了根据拍摄的图像序列的图像质量,自动选择单模语音处理方式提取的第一语音片段信号或多模语音处理方式提取的第二语音片段信号作为语音识别所需的目标语音片段信号,从而在对输出的目标语音片段信号进行识别时,根据图像质量有针对性地选择输出的语音片段信号的来源,进而有助于提高语音识别的准确性。
7、下面通过附图和实施例,对本公开的技术方案做进一步的详细描述。
技术特征:
1.一种语音信号处理方法,包括:
2.根据权利要求1所述的方法,其中,所述基于所述语音信号和所述图像序列,通过第二语音处理方式,从所述语音信号中提取第二语音片段信号,包括:
3.根据权利要求1所述的方法,其中,所述确定当前的语音信号处理状态是否符合语音信号输出条件,包括:
4.根据权利要求1所述的方法,其中,所述确定所述图像序列的图像质量信息,包括:
5.根据权利要求4所述的方法,其中,所述确定所述目标部位的可识别度,包括:
6.根据权利要求1所述的方法,其中,所述基于所述图像序列的图像质量信息,从所述第一语音片段信号和所述第二语音片段信号中确定目标语音片段信号,并输出所述目标语音片段信号,包括:
7.一种语音信号处理装置,包括:
8.根据权利要求7所述的装置,其中,所述第二提取模块包括:
9.一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序用于执行上述权利要求1-6任一所述的方法。
10.一种电子设备,所述电子设备包括:
技术总结
本公开实施例公开了一种语音信号处理方法、装置、可读存储介质及电子设备,其中,该方法包括:获取目标空间内的语音信号和图像序列;基于语音信号,通过第一语音处理方式,从语音信号中提取第一语音片段信号;基于语音信号和图像序列,通过第二语音处理方式,从语音信号中提取第二语音片段信号;确定当前的语音信号处理状态是否符合语音信号输出条件;若符合语音信号输出条件,确定图像序列的图像质量信息;基于图像序列的图像质量信息,从第一语音片段信号和第二语音片段信号中确定目标语音片段信号,并输出目标语音片段信号。本公开实施例根据图像质量有针对性地选择输出的语音片段信号的来源,进而有助于提高语音识别的准确性。
技术研发人员:李文鹏,潘复平,朱长宝
受保护的技术使用者:北京地平线机器人技术研发有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!