用于口语对话的实时语义理解方法、系统和电子设备与流程
本发明涉及智能语音领域,尤其涉及一种用于口语对话的实时语义理解方法、系统和电子设备。
背景技术:
1、为了提升用户的语音交互体验,不但需要提升语音识别的准确度,而且还要能够对识别结果进行准确、高效的进行语义理解。现有的语义理解技术需要输入完整的全量文本,然后解析出该全量文本对应的解析结果。例如,在与用户的口语对话中,检测到用户说完一句话之后得到对应的语音识别结果,再将语音识别结果输入至语义理解引擎中得到对应的语义解析结果。这就导致了,在口语对话中,语音识别和语义理解模块是串行的:用户说完一句话之后,将整句话的语音数据送入语音识别模块进行语音识别,在整句话全部识别后,才会将该整句的识别结果送入语义理解模块进行语义理解,得到整句话的解析结果。
2、在实现本发明过程中,发明人发现相关技术中至少存在如下问题:
3、在与用户的口语对话过程中,需要等待用户说完一句完整的话,经过语音识别引擎识别解码出完整的文本后,再进行语义理解,整个过程包括了整句话的语音识别耗时加上整句话的语义理解耗时。也就是说,要想得到用户输入的正确语义解析结果,需要等待用户说完后将用户完整的语句输入语义解析引擎。因此必须等待语音识别引擎输出完整的解码结果后才能进行语义解析,因而会增加链路的耗时,整体耗时比较长,用户需要一定的等待时间才能得到交互系统的反馈结果,导致用户体验较差。
技术实现思路
1、为了至少解决现有技术中语义解析需要等待用户说完整句话,整体耗时较长,用户体验较差的问题。第一方面,本发明实施例提供一种用于口语对话的实时语义理解方法,包括:
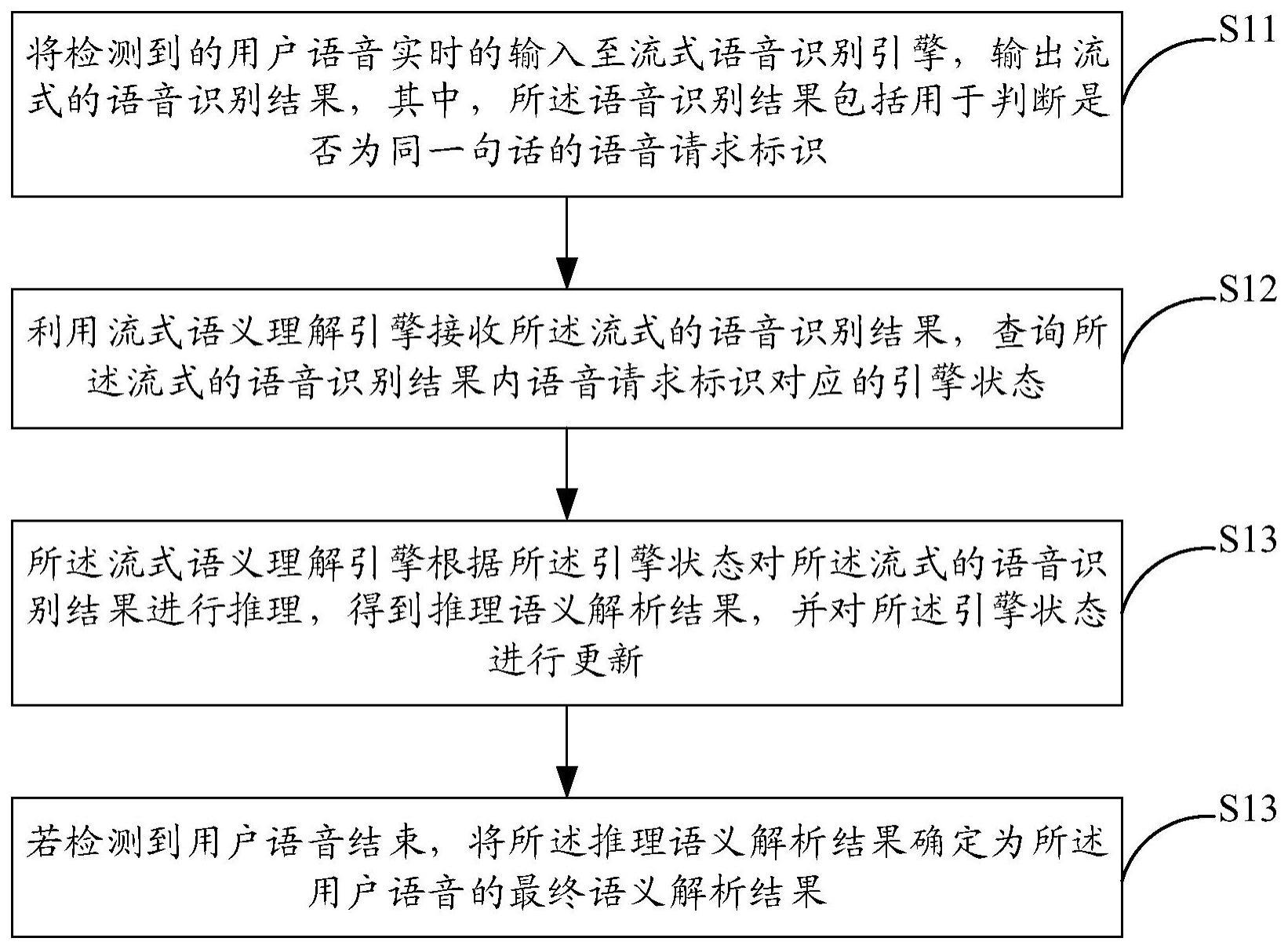
2、将检测到的用户语音实时的输入至流式语音识别引擎,输出流式的语音识别结果,其中,所述语音识别结果包括用于判断是否为同一句话的语音请求标识;
3、利用流式语义理解引擎接收所述流式的语音识别结果,查询所述流式的语音识别结果内语音请求标识对应的引擎状态;
4、所述流式语义理解引擎根据所述引擎状态对所述流式的语音识别结果进行推理,得到推理语义解析结果,并对所述引擎状态进行更新;
5、若检测到用户语音结束,将所述推理语义解析结果确定为所述用户语音的最终语义解析结果。
6、第二方面,本发明实施例提供一种用于口语对话的实时语义理解系统,包括:
7、语音识别程序模块,用于将检测到的用户语音实时的输入至流式语音识别引擎,输出流式的语音识别结果,其中,所述语音识别结果包括用于判断是否为同一句话的语音请求标识;
8、引擎状态确定程序模块,用于利用流式语义理解引擎接收所述流式的语音识别结果,查询所述流式的语音识别结果内语音请求标识对应的引擎状态;
9、语义推理程序模块,用于所述流式语义理解引擎根据所述引擎状态对所述流式的语音识别结果进行推理,得到推理语义解析结果,并对所述引擎状态进行更新;
10、语义理解程序模块,用于若检测到用户语音结束,将所述推理语义解析结果确定为所述用户语音的最终语义解析结果。
11、第三方面,提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的用于口语对话的实时语义理解方法的步骤。
12、第四方面,本发明实施例提供一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现本发明任一实施例的用于口语对话的实时语义理解方法的步骤。
13、本发明实施例的有益效果在于:利用流式语音解析引擎,不需要等用户说完整句话之后再进行语音识别,也避免了实时语义理解所需的成倍增长的计算量。本方法语义解析的耗时为末帧延迟(指从有效音频检测模块检测到人说完话,到出最终识别结果的时间),当识别模块实时输出识别结果时,将该识别结果实时输入流式语义解析引擎,那么会实时输出语义解析结果,那么此时语义解析引擎的耗时仅仅是最后一个字的解析时间,该耗时被大大缩减了,在不增加计算量的基础上,减少了用户的等待时间,提升了用户体验。
技术特征:
1.一种用于口语对话的实时语义理解方法,包括:
2.根据权利要求1所述的方法,其中,若检测到用户语音没有结束,所述方法还包括:
3.根据权利要求1所述的方法,其中,所述利用流式语义理解引擎接收所述流式的语音识别结果,查询所述流式的语音识别结果内语音请求标识对应的引擎状态包括:
4.根据权利要求1所述的方法,其中,在所述将所述推理语义解析结果确定为所述用户语音的最终语义解析结果之后,所述方法还包括:
5.一种用于口语对话的实时语义理解系统,包括:
6.根据权利要求5所述的系统,其中,所述语义理解程序模块用于:
7.根据权利要求5所述的系统,其中,所述引擎状态确定程序模块用于:
8.根据权利要求5所述的系统,其中,所述系统还包括交互程序模块,用于:
9.一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1-4中任一项所述方法的步骤。
10.一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现权利要求1-4中任一项所述方法的步骤。
技术总结
本发明实施例提供一种用于口语对话的实时语义理解方法、系统和电子设备。该方法包括:将检测到的用户语音实时的输入至流式语音识别引擎,输出流式的语音识别结果;利用流式语义理解引擎接收流式的语音识别结果,查询流式的语音识别结果内语音请求标识对应的引擎状态;流式语义理解引擎根据引擎状态对流式的语音识别结果进行推理,得到推理语义解析结果,并对引擎状态进行更新;若检测到用户语音结束,将推理语义解析结果确定为用户语音的最终语义解析结果。本发明实施例利用流式语音解析引擎,无需等待用户说完整句话之后再进行语音识别,也避免了实时语义理解所需的计算量。在不增加计算量的基础上,减少了用户的等待时间,提升了用户体验。
技术研发人员:樊帅,朱成亚,甘津瑞
受保护的技术使用者:思必驰科技股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!