视频生成方法及装置与流程
本发明涉及计算机,具体涉及一种视频生成方法及装置。
背景技术:
1、随着人工智能技术的发展,说话人(speaker)生成展现出了广泛的应用前景。说话人生成是指由语音或视频驱动的人物虚拟说话视频生成,视频中的人物可能是真实存在的,也可以由模型生成。
2、现有的说话人视频生成技术不能很好的表示不同说话人的风格特点。同时,脸部的运动受到了人脸形状的影响,例如嘴部的运动应该与嘴部的形状有关,现有的技术无法表达人脸形状对运动状态的影响。另一方面,当前的渲染算法得到的人脸真实感较差,需要采集特定模特的视频进行训练,这增加了说话人生成的成本,限制了说话人生成技术的广泛应用。
技术实现思路
1、有鉴于此,本发明实施例提供了一种视频生成方法及装置,以体现出说话人的风格特点并提升说话人人脸的真实感。
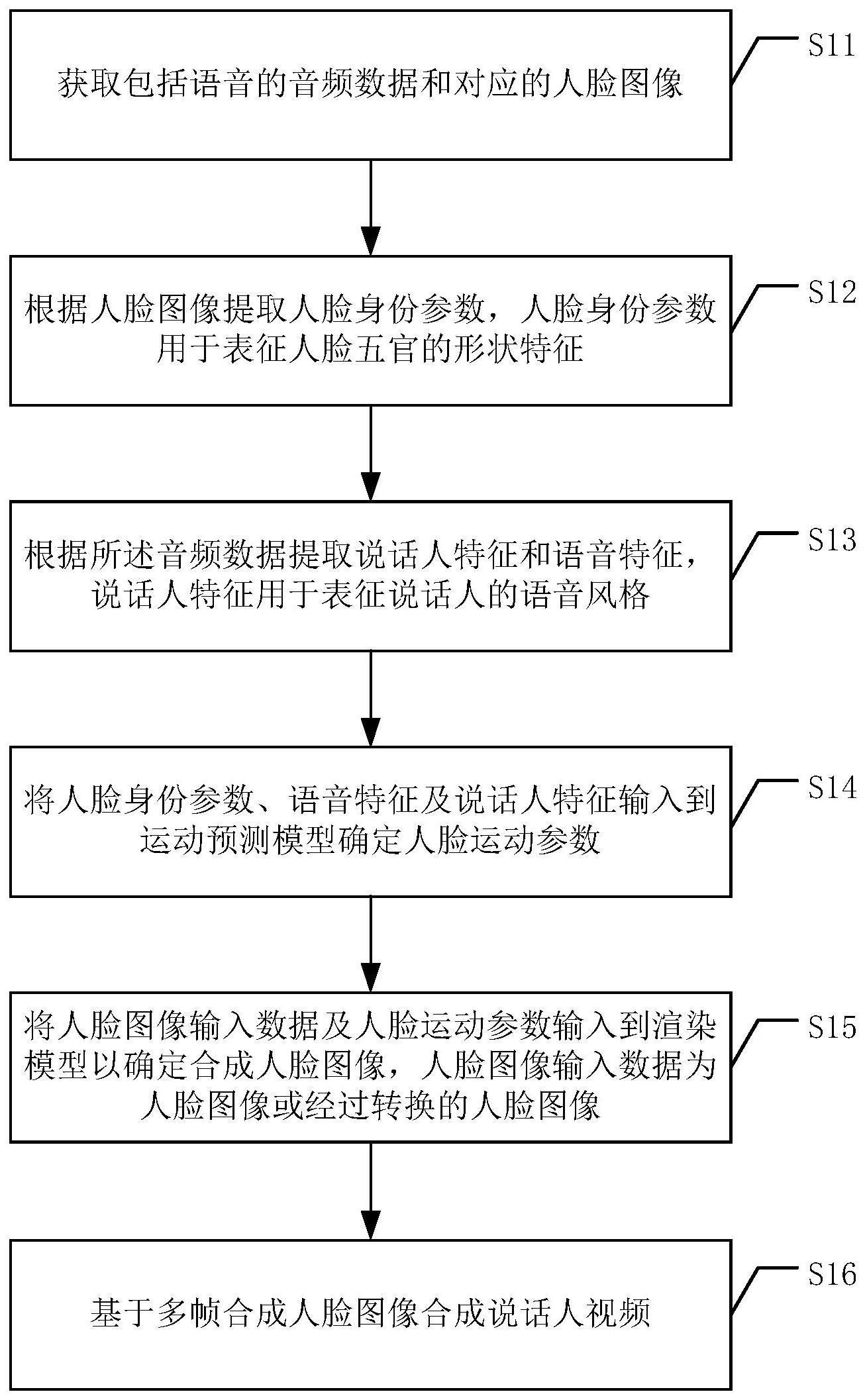
2、第一方面,本发明实施例提供一种视频生成方法,所述方法包括:
3、获取包括语音的音频数据和对应的人脸图像;
4、根据人脸图像提取人脸身份参数,所述人脸身份参数用于表征人脸五官的形状特征;
5、根据所述音频数据提取说话人特征和语音特征,所述说话人特征用于表征说话人的语音风格;
6、将所述人脸身份参数、语音特征及说话人特征输入到运动预测模型确定人脸运动参数;
7、将人脸图像输入数据及人脸运动参数输入到渲染模型以确定合成人脸图像,其中,所述人脸图像输入数据为所述人脸图像或经过转换的人脸图像;
8、基于多帧所述合成人脸图像合成说话人视频。
9、可选的,根据人脸图像提取人脸身份参数具体为:
10、通过预先训练人脸3d重建模型从所述人脸图像提取人脸身份参数、纹理信息以及光照姿态信息。
11、可选的,所述方法还包括:
12、根据图像到图像翻译模型优化人脸图像的纹理信息,确定所述人脸图像输入数据。
13、可选地,所述根据所述音频数据提取说话人特征具体为:
14、获取多段音频数据并输入到预先训练的说话人识别模型中以提取说话人特征,提取的说话人特征为语音特征向量,包括说话人声门特性参数和声道特性参数。
15、可选的,所述人脸身份参数包括人脸轮廓、额头形状、眼睛形状、鼻子形状及嘴部形状参数,所述人脸图像输入数据包括高频纹理信息、人脸身份参数及光照姿态信息,所述高频纹理信息包括毛发和斑点。
16、可选的,将人脸图像输入数据及人脸运动参数输入到渲染模型以确定合成人脸图像包括:
17、将人脸图像输入数据及人脸运动参数输入到渲染模型以确定渲染后的人脸图像;以及
18、将所述渲染后的人脸图像与图片背景融合以确定合成人脸图像,所述图片背景为原始图片背景或特定图片背景。
19、第二方面,本发明实施例提供一种视频生成装置,所述装置包括:
20、获取单元,被配置为获取包括语音的音频数据和对应的人脸图像;
21、第一提取单元,被配置为根据人脸图像提取人脸身份参数,所述人脸身份参数用于表征人脸五官的形状特征;
22、第二提取单元,被配置为根据所述音频数据提取说话人特征和语音特征,所述说话人特征用于表征说话人的语音风格;
23、人脸运动生成单元,被配置将所述人脸身份参数、语音特征及说话人特征输入到运动预测模型确定人脸运动参数;
24、图像生成单元,被配置为将人脸图像输入数据及人脸运动参数输入到渲染模型以确定合成人脸图像,其中,所述人脸图像输入数据为人脸图像本身或经过转换的人脸图像;
25、视频生成单元,被配置为基于多帧所述合成人脸图像合成说话人视频。
26、第三方面,本发明实施例提供一种电子设备,包括存储器和处理器,所述存储器用于存储一条或多条计算机程序指令,其中,所述一条或多条计算机程序指令被所述处理器执行以实现如第一方面所述的装置。
27、第四方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的装置。
28、本发明实施例通过在渲染说话人人脸图像的过程中,加入对于表征人脸形状的人脸身份信息以及表征说话人语音风格的说话人特征,基于多维度的信息利用运动预测模型来生成人脸运动参数,进而基于生成的人脸运动参数合成说话人的人脸图像的帧,并基于多帧图像生成说话人视频。由此,使得生成的说话人视频能够体现出说话人的风格特点,同时提升了说话人人脸的真实感。
技术特征:
1.一种视频生成方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,根据人脸图像提取人脸身份参数具体为:
3.根据权利要求2所述的方法,其特征在于,所述方法还包括:
4.根据权利要求1所述的方法,其特征在于,所述根据所述音频数据提取说话人特征具体为:
5.根据权利要求1所述的方法,其特征在于,所述人脸身份参数包括人脸轮廓、额头形状、眼睛形状、鼻子形状及嘴部形状参数,所述人脸图像输入数据包括高频纹理信息、人脸身份参数及光照姿态信息,所述高频纹理信息包括毛发和斑点。
6.根据权利要求1所述的方法,其特征在于,将人脸图像输入数据及人脸运动参数输入到渲染模型以确定合成人脸图像包括:
7.一种视频生成装置,其特征在于,所述装置包括:
8.一种电子设备,包括存储器和处理器,其特征在于,所述存储器用于存储一条或多条计算机程序指令,其中,所述一条或多条计算机程序指令被所述处理器执行以实现如权利要求1-6中任一项所述的方法。
9.一种计算机可读存储介质,其上存储计算机程序指令,其特征在于,所述计算机程序指令在被处理器执行时实现如权利要求1-6中任一项所述的方法。
技术总结
本发明实施例公开了一种视频生成方法及装置,通过在渲染说话人人脸图像的过程中,加入对于表征人脸形状的人脸身份信息以及表征说话人语音风格的说话人特征,基于多维度的信息利用运动预测模型来生成人脸运动参数,进而基于生成的人脸运动参数合成说话人的人脸图像的帧,并基于多帧图像生成说话人视频。由此,使得生成的说话人视频能够体现出说话人的风格特点,同时提升了说话人人脸的真实感。
技术研发人员:候学东,李梅,孙瑜博,吕达,李永源,陈云琳
受保护的技术使用者:上海墨百意信息科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!