自适应参数投票机制的语音端点检测方法及系统与流程
本发明涉及语音信号处理,具体地,涉及一种自适应参数投票机制的语音端点检测方法及系统。
背景技术:
1、实际生活工作中,存在着无所不在的噪声,如空调风扇声,人们的交谈声,街道上汽车的噪声,这些都难免会影响我们的目标语音信号;此外,录音设备和传输信道也会产生干扰,从而形成带噪语音信号,使原信号质量降低。而语音处理系统往往在强噪声存在情况下处理性能会急剧下降,影响其本身处理结果和语音质量。
2、专利文献cn115472152a一种语音端点检测方法、装置、计算机设备及可读存储介质,该方法包括:采集音频数据,并对音频数据进行音频预处理,得到目标音频数据;将目标音频数据输入至预先构建的音频场景分类模型,确定目标音频数据对应的场景类别;将目标音频数据输入至预先构建的语音端点检测模型,并基于场景类别确定目标音频数据对应的语音状态。
3、但是专利文献cn115472152a主要依托于构建的音频分类及语音端点检测模型,不仅需要事先收集大量不同场景语音数据,还需花费较长的时间去训练模型,且运算量大不易实时实现。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种自适应参数投票机制的语音端点检测方法及系统。
2、根据本发明提供的一种自适应参数投票机制的语音端点检测方法,包括:
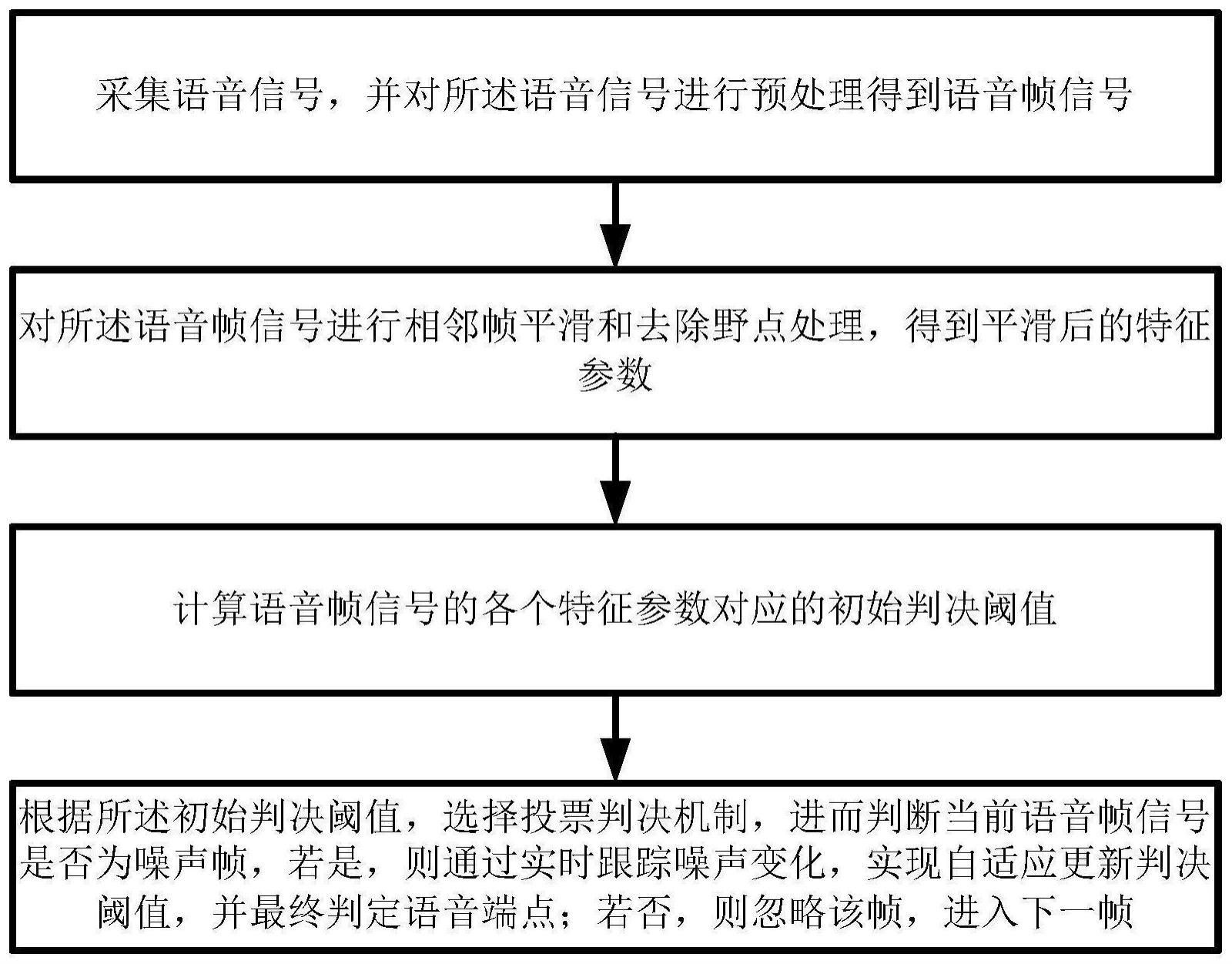
3、步骤s1:采集语音信号,并对所述语音信号进行预处理得到语音帧信号;
4、步骤s2:对所述语音帧信号进行相邻帧平滑和去除野点处理,得到平滑后的特征参数;
5、步骤s3:计算语音帧信号的各个特征参数对应的初始判决阈值;
6、步骤s4:根据所述初始判决阈值,选择投票判决机制,进而判断当前语音帧信号是否为噪声帧,若是,则触发步骤s5;若否,则忽略该帧,进入下一帧;
7、步骤s5:通过实时跟踪噪声变化,实现自适应更新判决阈值,并最终判定语音端点。
8、优选地,对所述语音信号进行预处理包括对输入语音信号进行加窗分帧的处理,并去除直流分量;
9、所述特征参数包括均匀子带谱方差、能熵比、mfcc距离和似然比。
10、优选地,所述初始判决阈值的计算公式如下:
11、
12、式中,t1、t2、t3和t4分别表示多窗谱子带谱方差阈值、能熵比阈值、mfcc距离阈值和似然比阈值,dth、ehth、dth和rth分别表示初始多窗谱子带谱方差阈值、初始能熵比阈值、初始mfcc距离阈值和初始似然比阈值,nis表示语音信号初始无声段帧数,d(i)、eh(i)、d(i)和r(i)分别表示均匀子带谱方差、能熵比、mfcc距离和似然比。
13、优选地,所述投票判决机制包括第一投票判决机制和第二投票判决机制;
14、当ehth≤β时,选择第一投票判决机制;当ehth>β时,选择第二投票判决机制,其中β表示系数;
15、所述第一投票判决机制包括任意两种及以上的特征参数小于各自对应的参数阈值,则判定为进入噪声段;
16、所述第二投票判决机制包括至少三种特征参数小于各自对应的参数阈值则判定为进入噪声段。
17、优选地,所述更新判决阈值公式如下:
18、
19、式中,α=0.99,μ=0.01;
20、所述判定语音端点包括延迟处理,所述延迟处理包括当噪声段帧数大于8时,判定为是噪声段,否则仍判定为语音段,从而完成对语音的端点检测。
21、根据本发明提供的一种自适应参数投票机制的语音端点检测系统,包括:
22、模块m1:采集语音信号,并对所述语音信号进行预处理得到语音帧信号;
23、模块m2:对所述语音帧信号进行相邻帧平滑和去除野点处理,得到平滑后的特征参数;
24、模块m3:计算语音帧信号的各个特征参数对应的初始判决阈值;
25、模块m4:根据所述初始判决阈值,选择投票判决机制,进而判断当前语音帧信号是否为噪声帧,若是,则触发模块m5;若否,则忽略该帧,进入下一帧;
26、模块m5:通过实时跟踪噪声变化,实现自适应更新判决阈值,并最终判定语音端点。
27、优选地,对所述语音信号进行预处理包括对输入语音信号进行加窗分帧的处理,并去除直流分量;
28、所述特征参数包括均匀子带谱方差、能熵比、mfcc距离和似然比。
29、优选地,所述初始判决阈值的计算公式如下:
30、
31、式中,t1、t2、t3和t4分别表示多窗谱子带谱方差阈值、能熵比阈值、mfcc距离阈值和似然比阈值,dth、ehth、dth和rth分别表示初始多窗谱子带谱方差阈值、初始能熵比阈值、初始mfcc距离阈值和初始似然比阈值,nis表示语音信号初始无声段帧数,d(i)、eh(i)、d(i)和r(i)分别表示均匀子带谱方差、能熵比、mfcc距离和似然比。
32、优选地,所述投票判决机制包括第一投票判决机制和第二投票判决机制;
33、当ehth≤β时,选择第一投票判决机制;当ehth>β时,选择第二投票判决机制,其中β表示系数;
34、所述第一投票判决机制包括任意两种及以上的特征参数小于各自对应的参数阈值,则判定为进入噪声段;
35、所述第二投票判决机制包括至少三种特征参数小于各自对应的参数阈值则判定为进入噪声段。
36、优选地,所述更新判决阈值公式如下:
37、
38、式中,α=0.99,μ=0.01;
39、所述判定语音端点包括延迟处理,所述延迟处理包括当噪声段帧数大于8时,判定为是噪声段,否则仍判定为语音段,从而完成对语音的端点检测。
40、与现有技术相比,本发明具有如下的有益效果:
41、1、本发明同时提取四种语音信号不同维度的特征参数,可以有效弥补特征阈值端点检测算法在低信噪比多种噪声环境下表现的不稳定性,由此更好的适应办公环境下噪声的多样性,提高语音端点检测的正确率。
42、2、本发明通过提取多种参数并利用一种自适应的投票机制进行语音端点检测的方法,更好的分割出低信噪比环境下的语音段和噪声段。
43、3、本发明利用可以反映当前信号能量大小以及平稳程度的实时噪声段能熵比参数来确定采用的投票判决机制,提高了检测的精准性和鲁棒性,同时提升了语音增强或语音识别的效果。
技术特征:
1.一种自适应参数投票机制的语音端点检测方法,其特征在于,包括:
2.根据权利要求1所述的自适应参数投票机制的语音端点检测方法,其特征在于,对所述语音信号进行预处理包括对输入语音信号进行加窗分帧的处理,并去除直流分量;
3.根据权利要求2所述的自适应参数投票机制的语音端点检测方法,其特征在于,所述初始判决阈值的计算公式如下:
4.根据权利要求3所述的自适应参数投票机制的语音端点检测方法,其特征在于,所述投票判决机制包括第一投票判决机制和第二投票判决机制;
5.根据权利要求3所述的自适应参数投票机制的语音端点检测方法,其特征在于,所述更新判决阈值公式如下:
6.一种自适应参数投票机制的语音端点检测系统,其特征在于,包括:
7.根据权利要求6所述的自适应参数投票机制的语音端点检测系统,其特征在于,对所述语音信号进行预处理包括对输入语音信号进行加窗分帧的处理,并去除直流分量;
8.根据权利要求7所述的自适应参数投票机制的语音端点检测系统,其特征在于,所述初始判决阈值的计算公式如下:
9.根据权利要求8所述的自适应参数投票机制的语音端点检测系统,其特征在于,所述投票判决机制包括第一投票判决机制和第二投票判决机制;
10.根据权利要求8所述的自适应参数投票机制的语音端点检测系统,其特征在于,所述更新判决阈值公式如下:
技术总结
本发明提供了一种自适应参数投票机制的语音端点检测方法及系统,包括:采集语音信号,并对语音信号进行预处理得到语音帧信号;对语音帧信号进行相邻帧平滑和去除野点处理,得到平滑后的特征参数;计算语音帧信号的各个特征参数对应的初始判决阈值;根据初始判决阈值,选择投票判决机制,进而判断当前语音帧信号是否为噪声帧,若是,则通过实时跟踪噪声变化,实现自适应更新判决阈值,并最终判定语音端点;若否,则忽略该帧,进入下一帧。本发明同时提取四种语音信号不同维度的特征参数,可以有效弥补特征阈值端点检测算法在低信噪比多种噪声环境下表现的不稳定性,由此更好的适应办公环境下噪声的多样性,提高语音端点检测的正确率。
技术研发人员:雷静,贺子宸,刘小平,陶晶,张倩
受保护的技术使用者:兴业银行股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!