语音情感转换的方法、装置、设备和存储介质与流程
本申请涉及人工智能,尤其涉及一种语音情感转换的方法、装置、设备和存储介质。
背景技术:
1、情感与韵律是语音中许多因素的融合,例如副语言信息、语调、重音和风格。语音转换中为情感韵律建模,其目的是为模型赋予选择适合给定上下文的说话风格的能力。韵律风格很难准确定义,但风格包含丰富的信息,例如意图和情感,并影响说话者对语调和语气的选择。
2、现有的情感生成或情感转换技术很难产生令人信服的结果,因为它们只能处理这些问题的一个子集或某一方面。基于信号的情感转换方法主要集中在操纵语音信号的参数上,只能解决语音和韵律层面的变化。而目前的建模方法难以对情感语音中的语气停顿、笑声、抿嘴声等非文本相关的信号建模,使得难以捕捉到文本之外富有表现力的语音信号,使得语音情感转换效果不理想。
技术实现思路
1、为了解决现有技术中语音情感转换的解决方案考虑层面单一片面或部分信号无法捕捉丢失导致情感转换效果不理想的技术问题。本申请提供了一种语音情感转换的方法、装置、设备和存储介质,其主要目的在于提升语音情感转换效果。
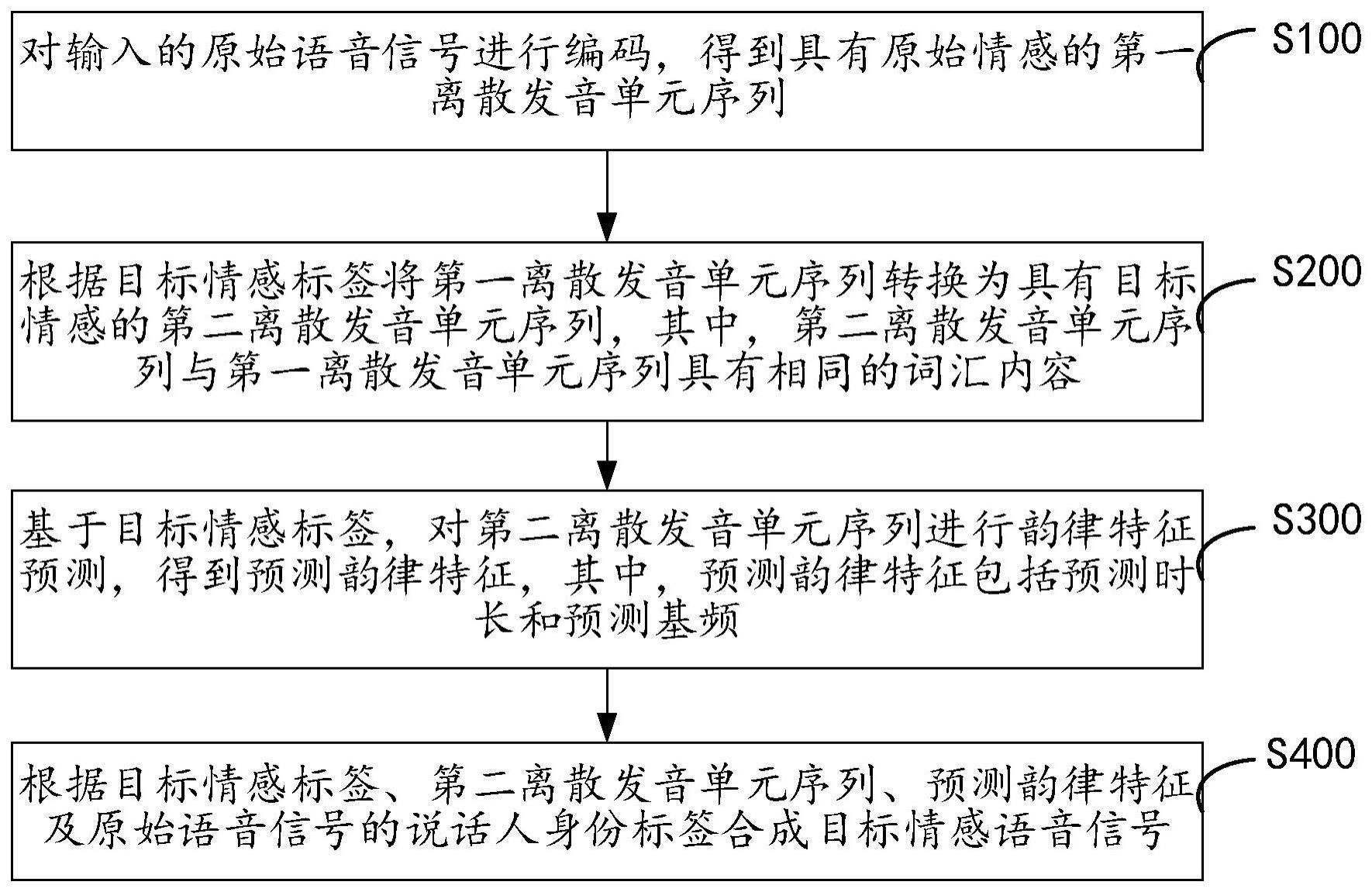
2、为实现上述目的,本申请提供了一种语音情感转换的方法,应用于语音情感转换系统,该方法包括:
3、对输入的原始语音信号进行编码,得到具有原始情感的第一离散发音单元序列;
4、根据目标情感标签将第一离散发音单元序列转换为具有目标情感的第二离散发音单元序列,其中,第二离散发音单元序列与第一离散发音单元序列具有相同的词汇内容;
5、基于目标情感标签,对第二离散发音单元序列进行韵律特征预测,得到预测韵律特征,其中,预测韵律特征包括预测时长和预测基频;
6、根据目标情感标签、第二离散发音单元序列、预测韵律特征及原始语音信号的说话人身份标签合成目标情感语音信号。
7、此外,为实现上述目的,本申请还提供了一种语音情感转换的装置,该装置包括:
8、编码模块,用于对输入的原始语音信号进行编码,得到具有原始情感的第一离散发音单元序列;
9、情感转换模块,用于根据目标情感标签将第一离散发音单元序列转换为具有目标情感的第二离散发音单元序列,其中,第二离散发音单元序列与第一离散发音单元序列具有相同的词汇内容;
10、预测模块,用于基于目标情感标签,对第二离散发音单元序列进行韵律特征预测,得到预测韵律特征,其中,预测韵律特征包括预测时长和预测基频;
11、合成模块,用于根据目标情感标签、第二离散发音单元序列、预测韵律特征及原始语音信号的说话人身份标签合成目标情感语音信号。
12、为实现上述目的,本申请还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机可读指令,处理器执行计算机可读指令时执行如前面任一项的语音情感转换的方法的步骤。
13、为实现上述目的,本申请还提供了一种计算机可读存储介质,计算机可读存储介质上存储有计算机可读指令,计算机可读指令被处理器执行时,使得处理器执行如前面任一项的语音情感转换的方法的步骤。
14、本申请提出的语音情感转换的方法、装置、设备和存储介质,打破传统对文本的依赖,不局限以书面文本来学习说话内容,而是以离散发音单元来学习原始音频信号中的说话内容、情感韵律,捕捉文本之外富有表现力的语音信号,并将原始情感的离散发音单元转换为具有目标情感的离散发音单元,最后根据预测韵律特征对具有目标情感的离散发音单元序列进行拼接合成为具有目标情感的语音信号。实现了通过无文本方式对口语音频进行离散化,捕捉文本之外富有表现力的语音信号,使得语音情感转换效果更加丰富逼真。
技术特征:
1.一种语音情感转换的方法,应用于语音情感转换系统,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述语音情感转换系统包括语音预训练模型;
3.根据权利要求1所述的方法,其特征在于,所述第一离散发音单元序列包含语言发音单元和第一非语言发音单元,所述语音情感转换系统包括情感转换模型;
4.根据权利要求3所述的方法,其特征在于,所述转换处理包括插入、替换和删除;
5.根据权利要求1所述的方法,其特征在于,所述语音情感转换系统包括时长预测模型,所述第二离散发音单元序列包括多个第二离散发音单元;
6.根据权利要求5所述的方法,其特征在于,所述语音情感转换系统还包括基频预估模型,
7.根据权利要求1所述的方法,其特征在于,所述语音情感转换系统包括声码器;
8.一种语音情感转换的装置,其特征在于,所述装置包括:
9.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机可读指令,其特征在于,所述处理器执行所述计算机可读指令时执行如权利要求1-7任一项所述的语音情感转换的方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机可读指令,其特征在于,所述计算机可读指令被处理器执行时,使得所述处理器执行如权利要求1-7任一项所述的语音情感转换的方法的步骤。
技术总结
本申请涉及人工智能技术,提出一种语音情感转换的方法、装置、设备和存储介质,该方法包括:将输入的原始语音信号编码为具有原始情感的第一离散发音单元序列;根据目标情感标签将第一离散发音单元序列转换为具有目标情感的第二离散发音单元序列;基于目标情感标签,对第二离散发音单元序列进行韵律特征预测,得到预测韵律特征,其中,预测韵律特征包括预测时长和预测基频;根据目标情感标签、第二离散发音单元序列、预测韵律特征及原始语音信号的说话人身份标签合成目标情感语音信号。本申请通过无文本方式对口语音频进行离散化,捕捉文本之外富有表现力的语音信号,使得语音情感转换效果更加丰富真实。
技术研发人员:陈闽川,马骏,王少军
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!