语音情绪模型的训练方法、表情驱动方法、电子设备及介质与流程
本发明涉及人工智能领域,特别涉及一种语音情绪模型的训练方法、表情驱动方法、电子设备及介质。
背景技术:
1、在面部表情情绪识别以及唇音识别中,语音情绪模型在接收音频数据后输出面部表情,输出的面部表情可以和音频数据实现唇音同步。
2、在相关技术中,对于语音情绪模型的训练,通常采用单特征输入的方式进行训练。例如,在网络端采用全连接或者vgg结构的单一音频特征输入的卷积神经网络的深度学习模型系统。通过提取单一音频的特征,在特征提取网络中训练,将训练好的语音情绪模型结合输入的面部表情表情点位,来驱动生成面部表情以及实现唇音同步。在上述方法中,语音情绪模型会过于依赖单一的特征,容易造成过拟合。
技术实现思路
1、本申请提供了一种语音情绪模型的训练方法、表情驱动方法、电子设备及介质,可以减少模型训练中的过拟合问题。
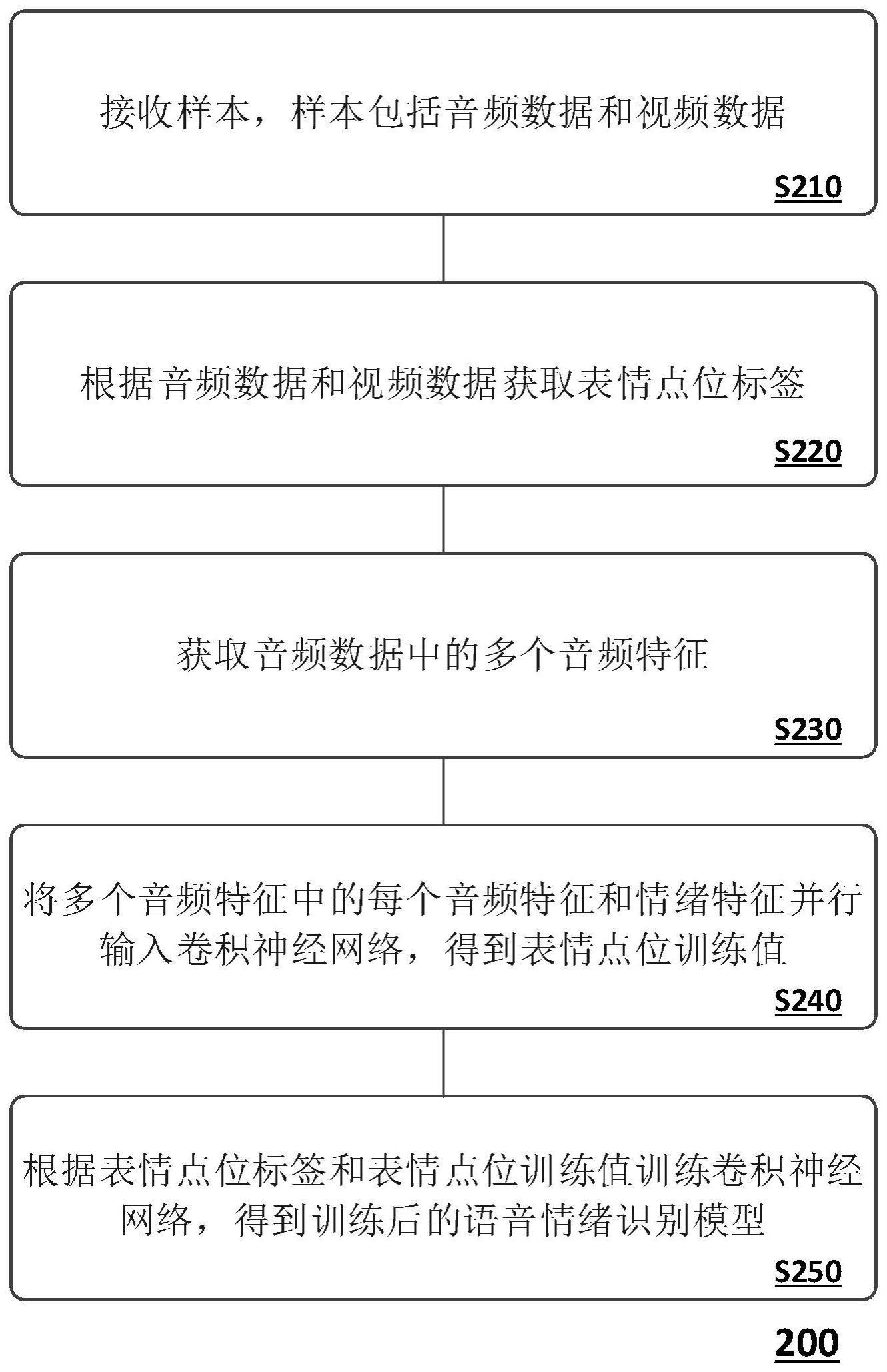
2、本申请的第一方面公开了音情绪识别模型的训练方法,应用于电子设备,所述方法包括,接收样本,所述样本包括音频数据和视频数据;根据所述音频数据和所述视频数据获取表情点位标签;获取所述音频数据中的多个音频特征;将所述多个音频特征中的每个音频特征和情绪特征并行输入卷积神经网络,得到表情点位训练值;根据所述表情点位标签和所述表情点位训练值训练所述卷积神经网络,得到训练后的语音情绪识别模型。
3、在上述第一方面的一种可能的实现中,所述方法还包括,将所述多个音频特征中的每个音频特征输入至包括至少三层结构的二维卷积层,其中,所述至少三层结构的每一层的第二维和第三维相等,并且从所述至少三层结构中的第三层开始,每层的通道数为前二层的通道数之和。
4、在上述第一方面的一种可能的实现中,将所述多个音频特征中的每个音频特征和情绪特征并行输入卷积神经网络训练包括,将与所述每个音频特征对应的卷积层的通道数和所述情绪特征的通道数进行合并级联,得到级联后的卷积层。
5、在上述第一方面的一种可能的实现中,所述方法还包括,对所述级联后的卷积层进行降维处理。
6、在上述第一方面的一种可能的实现中,所述方法还包括,将所述级联后的卷积层的输出输入至池化层和全连接层。
7、在上述第一方面的一种可能的实现中,所述多个音频特征包括梅尔频率倒谱系数、gammatone滤波器倒谱系数、线性判别倒谱系数中的至少两种。
8、在上述第一方面的一种可能的实现中,所述方法还包括,将所述多个音频特征中的一个音频特征和所述情绪特征并行输入第二卷积神经网络训练;设置所述卷积神经网络和所述第二卷积神经网络的权重,并根据所述权重的自适应训练得到所述训练后的语音情绪识别模型。
9、本申请的第二方面公开了一种表情驱动方法,所述方法包括,获取虚拟数字人的音频数据;提取所述音频数据中的多个音频特征;将所述多个音频特征输入至语音情绪识别模型进行识别,得到识别结果;根据所述识别结果,驱动所述虚拟数字人做出相应的表情,其中所述语音情绪识别模型是根据本申请第一方面所述的训练方法训练得到。
10、本申请的第三方面公开了一种语音情绪识别模型的训练装置,所述装置包括,接收模块,用于接收样本,所述样本包括音频数据和视频数据;采集模块,用于根据所述音频数据和所述视频数据获取表情点位标签,以及获取所述音频数据中的多个音频特征;训练模块,用于将所述多个音频特征中的每个音频特征和情绪特征并行输入卷积神经网络,得到表情点位训练值,以及根据所述表情点位标签和所述表情点位训练值训练所述卷积神经网络,得到训练后的语音情绪识别模型。
11、在上述第三方面的一种可能的实现中,所述装置还包括,级联模块,用于将与所述每个音频特征对应的卷积层的通道数和所述情绪特征的通道数进行合并级联,得到级联后的卷积层。
12、本申请的第四方面公开了一种电子设备,所述设备包括存储有计算机可执行指令的存储器和处理器;当所述指令被所述处理器执行时,使得所述设备实施根据本申请第一和第二方面的方法。
13、本申请的第五方面公开了一种计算机可读介质,所述存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现本申请第一方面和第二方面的方法。
14、本申请的第六方面公开了一种计算机程序产品,所述计算机程序被处理器执行时实现本申请第一方面和第二方面的方法。
15、本申请提供的语音情绪模型的训练方法、表情驱动方法、电子设备及介质,根据样本获取表情点位标签,并获取样本中的多个音频特征,通过将多个音频特征和情绪特征并行地输入至卷积神经网络进行训练。通过将训练值和表情点位标签的差异来训练卷积神经网络,得到训练后的语音情绪识别模型。通过多个特征并行输入模型以训练的方法可以在网络模型的输入端尽可能获取多的特征信息,以解决单特征输入造成过的拟合问题。
技术特征:
1.一种语音情绪识别模型的训练方法,应用于电子设备,其特征在于,所述方法包括,接收样本,所述样本包括音频数据和视频数据;
2.根据权利要求1所述的方法,其特征在于,所述方法还包括,将所述多个音频特征中的每个音频特征输入至包括至少三层结构的二维卷积层,其中,所述至少三层结构的每一层的第二维和第三维相等,并且从所述至少三层结构中的第三层开始,每层的通道数为前二层的通道数之和。
3.根据权利要求1所述的方法,其特征在于,将所述多个音频特征中的每个音频特征和情绪特征并行输入卷积神经网络训练包括,将与所述每个音频特征对应的卷积层的通道数和所述情绪特征的通道数进行合并级联,得到级联后的卷积层。
4.根据权利要求3所述的方法,其特征在于,所述方法还包括,对所述级联后的卷积层进行降维处理。
5.根据权利要求3所述的方法,其特征在于,所述方法还包括,将所述级联后的卷积层的输出输入至池化层和全连接层。
6.根据权利要求1所述的方法,其特征在于,所述多个音频特征包括梅尔频率倒谱系数、gammatone滤波器倒谱系数、线性判别倒谱系数中的至少两种。
7.根据权利要求1所述的方法,其特征在于,所述方法还包括,
8.一种表情驱动方法,其特征在于,所述方法包括:
9.一种语音情绪识别模型的训练装置,其特征在于,所述装置包括,
10.根据权利要求9所述的训练装置,其特征在于,所述装置还包括,
11.一种电子设备,其特征在于,所述设备包括存储有计算机可执行指令的存储器和处理器;当所述指令被所述处理器执行时,使得所述设备实施根据权利要求1至8中任一项所述的方法。
12.一种计算机可读介质,其特征在于,所述存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现权利要求1至8中任一项所述的方法。
13.一种计算机程序产品,包括计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至8中任一项所述的方法。
技术总结
本申请公开了一种语音情绪模型的训练方法、表情驱动方法、电子设备及介质,涉及人工智能技术领域。模型训练方法包括,接收样本,所述样本包括音频数据和视频数据;根据所述音频数据和所述视频数据获取表情点位标签;获取所述音频数据中的多个音频特征;将所述多个音频特征中的每个音频特征和情绪特征并行输入卷积神经网络,得到表情点位训练值;根据所述表情点位标签和所述表情点位训练值训练所述卷积神经网络,得到训练后的语音情绪识别模型。本申请的方法可以减少模型训练中的过拟合问题。
技术研发人员:黄子龙,范会善,王炼,余学武,周永吉,章铃娜,姜京京,赵新阳,贺文明
受保护的技术使用者:中国建设银行股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!