数据处理方法、装置、设备及计算机可读存储介质与流程
本申请属于人工智能,尤其涉及一种数据处理方法、装置、设备及计算机可读存储介质。
背景技术:
1、相关技术中,语音到文本翻译的方法,一般基于自动语音识别模型与机器翻译模型直接组成的级联系统,即级联模型实现,模型训练过程涉及到的参数调整量较大,模型训练的速度较慢,训练效率较低。
技术实现思路
1、本申请实施例提供一种与相关技术不同的实现方案,以解决相关技术中,在训练用于根据语音确定文本翻译结果的级联模型时,模型训练过程涉及到的参数调整量较大,模型训练的速度较慢,训练效率较低的技术问题。
2、第一方面,本申请提供一种数据处理方法,包括:
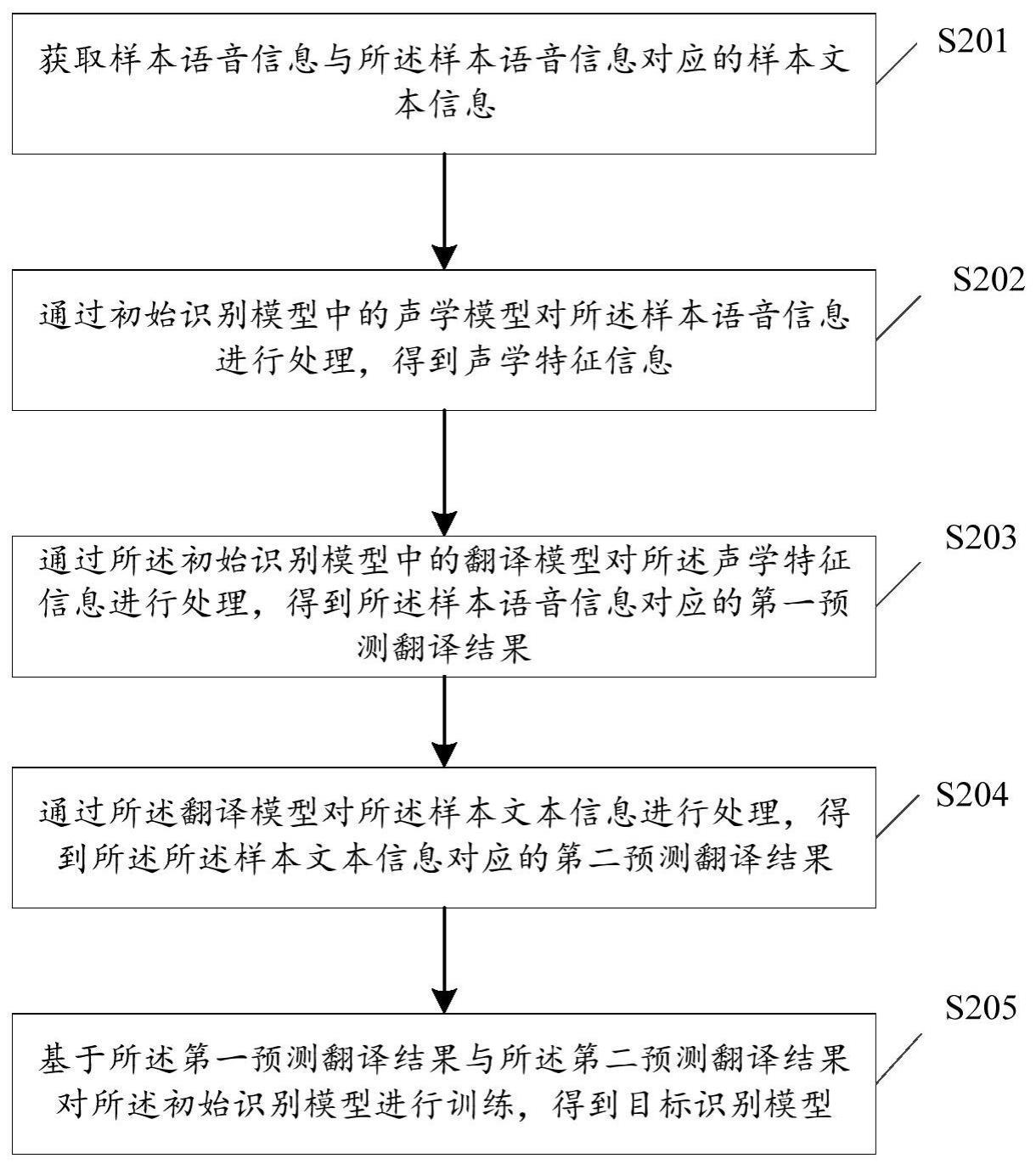
3、获取样本语音信息与所述样本语音信息对应的样本文本信息;
4、通过初始识别模型中的声学模型对所述样本语音信息进行处理,得到声学特征信息;
5、通过所述初始识别模型中的翻译模型对所述声学特征信息进行处理,得到所述样本语音信息对应的第一预测翻译结果;
6、通过所述翻译模型对所述样本文本信息进行处理,得到所述所述样本文本信息对应的第二预测翻译结果;
7、基于所述第一预测翻译结果与所述第二预测翻译结果对所述初始识别模型进行训练,得到目标识别模型,所述目标识别模型用于根据输入的待识别语音信息,识别出所述待识别语音信息的文本翻译结果;
8、其中,所述声学模型和/或所述翻译模型为预训练后的模型,且所述声学模型与所述翻译模型满足以下条件中的至少一个:
9、所述声学模型中包含的多个第一数据处理层中的至少一个第二数据处理层中的第一自注意力机制单元中的第一k向量与第一v向量分别拼接有第一前缀向量与第二前缀向量;
10、所述翻译模型中包含的多个第三数据处理层中的至少一个第四数据处理层中的第二自注意力机制单元中的第二k向量与第二v向量分别拼接有第三前缀向量与第四前缀向量。
11、第二方面,本申请提供一种数据处理装置,包括:
12、获取单元,用于获取样本语音信息与所述样本语音信息对应的样本文本信息;
13、处理单元,用于通过初始识别模型中的声学模型对所述样本语音信息进行处理,得到声学特征信息;
14、所述处理单元,还用于通过所述初始识别模型中的翻译模型对所述声学特征信息进行处理,得到所述样本语音信息对应的第一预测翻译结果;
15、所述处理单元,还用于通过所述翻译模型对所述样本文本信息进行处理,得到所述所述样本文本信息对应的第二预测翻译结果;
16、训练单元,用于基于所述第一预测翻译结果与所述第二预测翻译结果对所述初始识别模型进行训练,得到目标识别模型,所述目标识别模型用于根据输入的待识别语音信息,识别出所述待识别语音信息的文本翻译结果;
17、其中,所述声学模型和/或所述翻译模型为预训练后的模型,且所述声学模型与所述翻译模型满足以下条件中的至少一个:
18、所述声学模型中包含的多个第一数据处理层中的至少一个第二数据处理层中的第一自注意力机制单元中的第一k向量与第一v向量分别拼接有第一前缀向量与第二前缀向量;
19、所述翻译模型中包含的多个第三数据处理层中的至少一个第四数据处理层中的第二自注意力机制单元中的第二k向量与第二v向量分别拼接有第三前缀向量与第四前缀向量。
20、第三方面,本申请提供一种电子设备,包括:
21、处理器;以及
22、存储器,用于存储所述处理器的可执行指令;
23、其中,所述处理器配置为经由执行所述可执行指令来执行第一方面或第一方面各可能的实施方式中的任一方法。
24、第四方面,本申请实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面或第一方面各可能的实施方式中的任一方法。
25、第五方面,本申请实施例提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现第一方面或第一方面各可能的实施方式中的任一方法。
26、本申请提供的方案,在预训练好的模型,即声学模型与翻译模型的原本参数固定的情况下,在各自的自注意力机制单元中添加了前缀向量,并基于prefix-tuning进行训练,本申请的方案对预训练好的模型中作用比较关键的结构中添加了额外的信息,能够基于较少的参数调整,较快的训练出翻译质量较好的目标识别模型,在对较小的参数量进行调整的条件下,实现高性能的目标识别模型的训练,提高了目标识别模型的训练效率。
技术特征:
1.一种数据处理方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述声学模型与所述翻译模型还满足以下条件中的至少一个:
3.根据权利要求1所述的方法,其特征在于,通过初始识别模型中的声学模型对所述样本语音信息进行处理,得到声学特征信息,包括:
4.根据权利要求3所述的方法,其特征在于,所述第一数据处理层包含有第一自注意力机制单元、第一归一化单元、第一前馈神经网络,以及第二归一化单元;针对所述第二数据处理层,通过所述第二数据处理层对所述第二数据处理层的第二输入信息进行处理,得到所述第二数据处理层的第二输出信息,包括:
5.根据权利要求1所述的方法,其特征在于,通过初始识别模型中的翻译模型对所述声学特征信息进行处理,得到所述样本语音信息对应的第一预测翻译结果,包括:
6.根据权利要求5所述的方法,其特征在于,所述第三数据处理层包含有第二自注意力机制单元、第三归一化单元、第二前馈神经网络,以及第四归一化单元;针对所述第四数据处理层,通过所述第四数据处理层对所述第四数据处理层的第四输入信息进行处理,得到所述第四数据处理层的第四输出信息,包括:
7.根据权利要求1所述的方法,其特征在于,通过初始识别模型中的翻译模型对所述声学特征信息进行处理,得到所述样本语音信息对应的第一预测翻译结果之前,所述方法还包括:
8.根据权利要求2所述的方法,其特征在于,基于所述第一预测翻译结果与所述第二预测翻译结果对所述初始识别模型进行训练,得到目标识别模型,包括:
9.根据权利要求1所述的方法,其特征在于,所述方法还包括:
10.一种数据处理装置,其特征在于,包括:
11.一种电子设备,其特征在于,包括:
12.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1-9中任一项所述的方法。
技术总结
本申请公开了一种数据处理方法、装置、设备及计算机可读存储介质,方法包括:获取样本语音信息与样本文本信息;通过初始识别模型中的声学模型对样本语音信息进行处理得到声学特征信息;通过初始识别模型中的翻译模型对声学特征信息与样本文本信息进行处理,分别得到第一预测翻译结果与第二预测翻译结果;基于第一预测翻译结果与第二预测翻译结果对初始识别模型进行训练,得到目标识别模型;声学模型中的K向量与V向量拼接有前缀向量和/或翻译模型中的K向量与V向量拼接有前缀向量。实现了提高目标识别模型的训练效率的作用。
技术研发人员:董倩倩,赵云龙,高汝霆,王明轩
受保护的技术使用者:北京有竹居网络技术有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!