一种基于多任务预训练1D-CNN模型的语音检测方法与流程
本发明属于语音识别领域,涉及一种基于多任务预训练1d-cnn模型的语音检测技术。
背景技术:
1、随着智能化时代的到来,语音识别技术越来越受到人们的关注。传统的语音识别技术主要依靠高斯混合模型(gmm)和隐马尔可夫模型(hmm)。但是在实际应用中,这种方法存在着许多问题,例如对于噪声和语速变化的鲁棒性较差等。近年来,基于深度学习的语音识别技术逐渐兴起。其中,cnn作为一种广泛应用于图像处理的深度学习模型,也被引入到声音识别领域中。
2、目前,已有许多相关技术应用。例如,很多公司的语音助手使用了基于cnn的语音识别技术,可以通过语音控制智能设备,极大地方便了人们的生活。此外,部分大学的研究小组也开发出了一种基于cnn的声纹识别系统,可以用于身份验证等领域。然而,现有技术仍存在一些问题,例如需要大量的数据训练、对于不同说话人之间的差异鲁棒性差、需要手工提取特征、容易受到噪声干扰、模型复杂度大等问题,需要进一步提高语音识别技术的准确性和稳定性。
技术实现思路
1、1.所要解决的技术问题:
2、现有的基于cnn的语音识别技术需要大量的数据训练,容易受到噪声干扰,模型复杂度大。
3、2.技术方案:
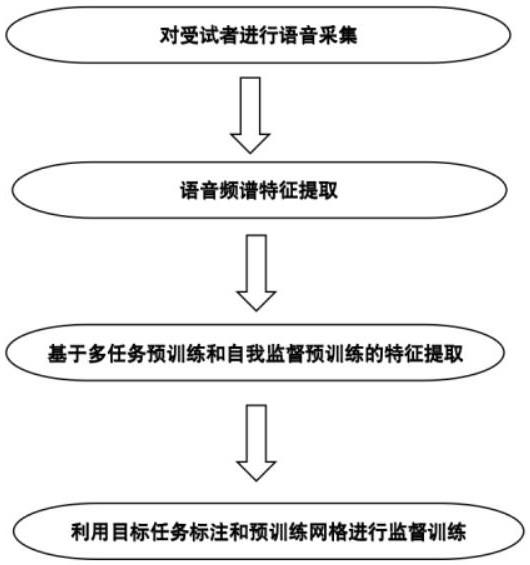
4、为了解决以上问题,本发明提供了一种基于多任务预训练1d-cnn模型的语音检测方法,包括以下步骤:
5、步骤s01:语音采集,获取受试者的数据。
6、步骤s02:语音信号预处理,具体方法为:步骤s21:从原始语音数据中提取频谱特征。步骤s22:去掉未发声部分,将音频分割成具有固定时间长度的音频帧。步骤s23:通过使用移动窗口提取了一个固定长度的特征片段作为 1d-cnn 的输入。
7、步骤s03:id-cnn模型开发,具体方法为:步骤s31:语音预处理得到的特征片段沿特征轴应用一维卷积滤波器;步骤s32:使用自注意力机制,为每一帧学习了一个加权,并将加权的帧加在一起,将所有帧直接减少到一个维度;:步骤s33:利用辅助信息进行多任务学习对1d-cnn网络进行预训练。利用辅助任务使1d-cnn输出一个低维度特征向量;步骤s34::利用自监督学习来加强训练;步骤s35:以id-cnn模型为骨干训练1d-cnn,用于通过标记数据检测对象;步骤s36:监督学习将每个人的三种不同情绪的语音分别输入到1d-cnn中,并将所得到的低维度特征向量串联起来,形成一个更高维度的特征向量;并用该特征向量和目标任务的语音分类标签通过监督学习,训练面向目标任务的分类器。
8、步骤s04:隐私保护模型的开发; 1d-cnn模型是用户仅使用自己的原始声音数据和可共享的处理数据训练用户自己的模型。
9、步骤s05: 模型性能评估。
10、步骤s01语音采集的具体方法为:
11、步骤s11:获得每个受试者的书面知情同意。
12、步骤s12:采集不同情绪下的语音。
13、步骤s13:通过对目标任务有识别能力的人,对受试者进行分类标注。
14、步骤s14:对语音文件进行筛选,以检查样本质量,录音长度小于要求,或录音时背景噪音过大,或用多个声音重新编码,被定义为有缺陷的录音。有一个是有缺陷的,这个受试者的所有录音都被排除。
15、所述情绪为:在正常情绪、积极情绪和消极情绪。
16、所述步骤21中,使用matlab工具箱 voicebox提取频谱特征,包括美尔-频谱系数(mfcc)和线性预测编码(lpc)mfcc和lpc,对说话者声音的不同特征进行建模。
17、所述步骤s22中,使用0.02*fs的滑动窗口和 0.5*0.02*fs的步长来进行mfcc和lpc提取。
18、所述移动窗口的大小设定为 1200帧,跨度值为200帧。
19、步骤s33中,所述辅助信息包括受试者的性别、年龄、身份信息。
20、步骤s34中,采用拼图技术,在1200个特征帧中随机选择两个小帧,并将其调换。通过使用对比性损失来训练1d-cnn 模型来识别应用移动窗口或拼图策略后的类别。
21、3.有益效果:
22、本发明用预训练处理小样本和隐私保护能快速将语音信号转换成时频图形式,然后将其输入到cnn网络中进行特征提取。而且擅长语音机理分析,使用自我注意力机制对提取的特征进行加权,更好地捕获关键信息并解决长序列建模问题。基于多任务预训练1d-cnn模型的语音诊断技术,将加权特征传递给输出层进行分类或序列建模,具有更强准确性。
技术特征:
1.一种基于多任务预训练1d-cnn模型的语音检测方法,包括以下步骤:
2.如权利要求1所述的检测方法,其特征在于:步骤s01语音采集的具体方法为:
3.如权利要求2所述的检测方法,其特征在于:所述情绪为:在正常情绪、积极情绪和消极情绪。
4.如权利要求1所述的检测方法,其特征碍于:所述步骤21中,使用matlab工具箱voicebox提取频谱特征,包括美尔-频谱系数(mfcc)和线性预测编码(lpc)mfcc和lpc,对说话者声音的不同特征进行建模。
5.如权利要求1所述的检测方法,其特征在于:所述步骤s22中,使用0.02*fs的滑动窗口和 0.5*0.02*fs的步长来进行mfcc和lpc提取。
6.如权利要求1所述的检测方法,其特征在于:所述移动窗口的大小设定为 1200帧,跨度值为200帧。
7.如权利要求1所述的检测方法,其特征在于:步骤s33中,所述辅助信息包括受试者的性别、年龄、身份信息。
8.如权利要求1所述的检测方法,其特征在于:步骤s34中,采用拼图技术,在1200个特征帧中随机选择两个小帧,并将其调换,通过使用对比性损失来训练1d-cnn 模型来识别应用移动窗口或拼图策略后的类别。
技术总结
本发明提供了一种基于多任务预训练1D‑CNN模型的语音检测方法,包括以下步骤:步骤S01:语音采集,获取受试者的数据。步骤S02:语音信号预处理,步骤S03:ID‑CNN模型开发,步骤S04:隐私保护模型的开发;步骤S05:模型性能评估。本发明用预训练处理小样本和隐私保护能快速将语音信号转换成时频图形式,然后将其输入到CNN网络中进行特征提取。而且擅长语音机理分析,使用自我注意力机制对提取的特征进行加权,更好地捕获关键信息并解决长序列建模问题。基于多任务预训练1D‑CNN模型的语音诊断技术,将加权特征传递给输出层进行分类或序列建模,具有更强准确性。
技术研发人员:陈静,季春霖,陈刚,鲁安东,陈皓,辛钰
受保护的技术使用者:苏州万籁文化科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!