一种基于最小p范数的宽度学习及二次相关的声源定位方法
本发明涉及声源定位,尤其涉及一种基于最小p范数的宽度学习及二次相关的声源定位方法。
背景技术:
1、近几年来,随着科学技术和智能领域的不断发展与需求增加,声源定位技术被广泛应用,例如智能机器人领域和视频会议当中声源定位技术会使其变得更加智能化和人性化。
2、传统声源定位算法大体可分3类,基于到达时延估计(time difference ofarrival,tdoa)的声源定位算法、基于最大输出功率的可控波束形成声源定位算法和基于高分辨率谱估计的声源定位算法。在声源定位的应用中,基于到达时间差的方法是比较常用的,这个方法是根据估计出两个信号源的时延进而求出声源的位置,tdoa算法的复杂度低、实时性高、精度高、硬件成本低,进而被广泛的应用。时延估计作为tdoa声源定位的第一步是至关重要的,时延微小的误差都会导致定位结果的偏离。广义互相关时延估计算法(generalized cross-correlation,gcc)是较为经典的时延估计方法gcc方法通过添加加权函数提高了语音信号中的有效成分,进而提高了时延估计精度。但是在信噪比进一步降低时,该算法的抗噪性能有限,所以选择利用二次相关算法来进一步有效抑制噪声的干扰,以提高抗噪性能。
3、科技的进步和更新,让越来越多的学者开始探索新的算法在声源定位中的应用。例如基于压缩感知的声源定位算法、基于机器学习的声源定位算法逐渐被提出,研究者将神经网络模型应用于移动机器人的声源定位,定位精度得到了一定的提高,但仍然存在计算量大、其稳定性以及抗干扰能力不足从而导致计算时间过长。
技术实现思路
1、本发明的目的在于提供一种基于最小p范数的宽度学习及二次相关的声源定位方法,旨在解决现有算法计算量大、其稳定性以及抗干扰能力不足,从而导致计算时间较长的问题。
2、为实现上述目的,本发明提供了一种基于最小p范数的宽度学习及二次相关的声源定位方法,包括以下步骤:
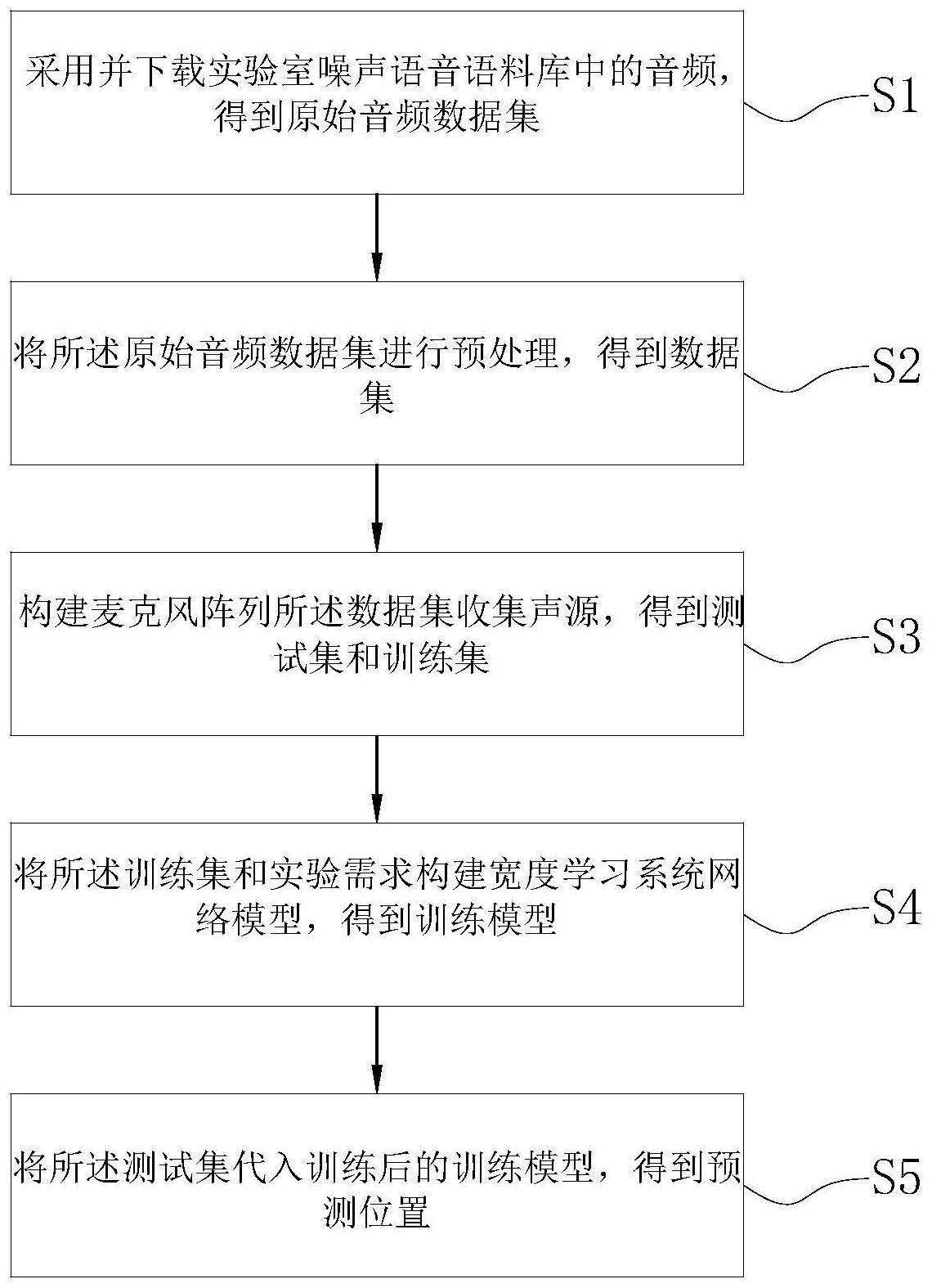
3、采用并下载实验室噪声语音语料库中的音频,得到原始音频数据集;
4、将所述原始音频数据集进行预处理,得到数据集;
5、构建麦克风阵列基于所述数据集收集声源,得到测试集和训练集;
6、将所述训练集和实验需求构建宽度学习系统网络模型,得到训练模型;
7、将所述测试集代入训练后的训练模型,得到预测位置。
8、其中,所述采用并下载实验室噪声语音语料库中的音频,得到原始音频数据集,包括:
9、通过所述实验室噪声语音语料库下载30个ieee句子,得到原始音频数据集;
10、其中,所述将所述原始音频数据集进行预处理,得到数据集,包括:
11、将所述原始音频数据集进行滤波、分帧、加窗、语音活动检测的预处理,得到数据集。
12、其中,所述构建麦克风阵列基于所述数据集收集声源,得到测试集和训练集,包括:
13、构建麦克风阵列;
14、将所述数据集的音频信号设置在指定位置,且声源与所述麦克风阵列设定为同一高度;并设定不同的信噪比,将同一信噪比下的所述音频信号分别放置于设定的位置上;
15、通过模拟所述麦克风阵列对所述音频信号进行接收和采集,得到测试集和训练集。
16、其中,所述将所述训练集和实验需求构建宽度学习系统网络模型,得到训练模型,包括:
17、将选取的基准麦克风和其余麦克风接收到的音频信号分别进行自相关和广义互相关处理,得到相关函数;
18、然后再将所述相关函数进行二次广义互相关处理,得到二次广义互相关函数;
19、提取所述二次广义互相关函数中的浅层特征和深层特征,分别映射为宽度学习的特征结点和增强结点,共同作为神经网络的输入;
20、将所述训练集和实验需求构建基于最小p范数的宽度学习系统网络结构,得到网络模型;
21、将所述训练集输入到网络模型中,此时的模型具有最优的参数权重,并对真实声源的位置进行预测。
22、本发明的一种基于最小p范数的宽度学习及二次相关的声源定位方法,通过采用并下载实验室噪声语音语料库中的音频,得到原始音频数据集;将所述原始音频数据集进行预处理,得到数据集;构建麦克风阵列基于所述数据集收集声源,得到测试集和训练集;将所述训练集和实验需求构建宽度学习系统网络模型,得到训练模型;将所述测试集代入训练后的训练模型,得到预测位置,解决了现有算法计算量大、其稳定性以及抗干扰能力不足,从而导致计算时间较长的问题。
技术特征:
1.一种基于最小p范数的宽度学习及二次相关的声源定位方法,其特征在于,
2.如权利要求1所述的基于最小p范数的宽度学习及二次相关的声源定位方法,其特征在于,
3.如权利要求2所述的基于最小p范数的宽度学习及二次相关的声源定位方法,其特征在于,
4.如权利要求3所述的基于最小p范数的宽度学习及二次相关的声源定位方法,其特征在于,
5.如权利要求所述的基于最小p范数的宽度学习及二次相关的声源定位方法,其特征在于,
技术总结
本发明涉及声源定位技术领域,具体涉及一种基于最小p范数的宽度学习及二次相关的声源定位方法,通过采用并下载实验室噪声语音语料库中的音频,得到原始音频数据集;将原始音频数据集进行预处理,得到数据集;构建麦克风阵列基于数据集收集声源,得到测试集和训练集;将训练集和实验需求构建宽度学习系统网络模型,得到训练模型;将测试集代入训练后的训练模型,得到预测位置,解决了现有算法计算量大、其稳定性以及抗干扰能力不足,从而导致计算时间较长的问题。
技术研发人员:唐荣江,张悦,陆滔琪,林波
受保护的技术使用者:桂林电子科技大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!