基于音频识别驱动数字人面部表情的方法、装置和设备与流程
背景技术:
1、首先,数字人(digital human / meta human),是运用数字技术创造出来的与人类形象接近的数字化人物形象;音频识别技术用于识别语音。
2、目前,融合音频识别技术的数字人主要是识别出的语音对数字人的面部表情进行控制,保障目标角色的面部动作特别是口型动作与音频内容保持同步。
3、但是这种方式下,仅仅是对于口型动作进行调节,会使得目标角色与音频提供者的现实表情不符,目标角色表情僵硬。
技术实现思路
1、有鉴于此,提供一种基于音频识别驱动数字人面部表情的方法、装置和设备,以解决现有技术中在目标角色上展现的面部动作与实际状态不符,面部生硬的问题。
2、本发明采用如下技术方案:
3、第一方面,本发明实施例提供了一种基于音频识别驱动数字人面部表情的方法,该方法包括:
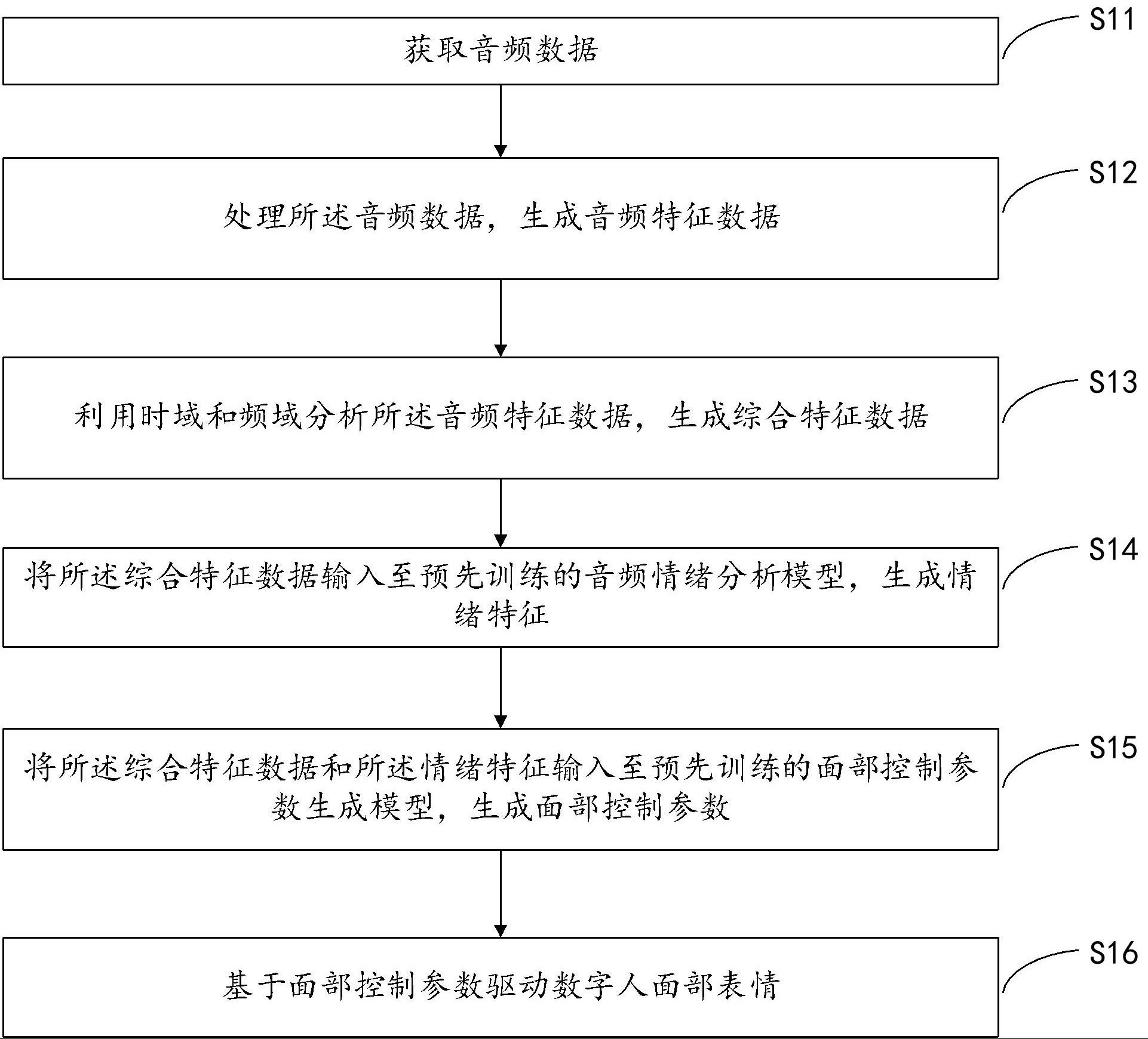
4、获取音频数据;
5、处理所述音频数据,生成音频特征数据;
6、利用时域和频域分析所述音频特征数据,生成综合特征数据;
7、将所述综合特征数据输入至预先训练的音频情绪分析模型,生成情绪特征;
8、将所述综合特征数据和所述情绪特征输入至预先训练的面部控制参数生成模型,生成面部控制参数;
9、基于面部控制参数驱动数字人面部表情。
10、进一步的,所述基于面部控制参数驱动数字人面部表情包括:
11、所述面部控制参数控制面部的眉毛、眼睛眼球、鼻子、嘴巴、脸颊以及下巴的面部肌肉,进而控制全脸面部表情动作。
12、进一步的,,还包括:
13、根据平滑滤波算法,优化所述面部控制参数;
14、传递所述面部控制参数至目标角色控制器,驱动目标角色的面部动作。
15、进一步的,所述处理所述音频数据,生成音频特征数据包括:
16、对所述音频数据进行人声分离处理和降采样操作,生成人声音频;
17、对所述人声音频进行特征提取,生成所述音频特征数据。
18、进一步的,所述降采样操作包括:
19、筛选出不符合采样频率的所述音频数据,将所述采样频率控制在预设值,从而完成降采样操作。
20、进一步的,包括:
21、判断所述音频数据中是否存在噪音干扰,若存在,进行人声分离,否则,直接提取特征,生成所述音频特征数据。
22、进一步的,所述音频特征包括:
23、能量特征、时域特征、频域特征、乐理特征和感知特征。
24、进一步的,所述情绪特征包括:
25、积极类情绪、中性类情绪、消极类情绪;
26、其中,积极类情绪包括高兴、振奋,消极类情绪包括悲伤、愤怒。
27、第二方面,本发明实施例提供了一种基于音频识别驱动数字人面部表情的装置,该装置包括:
28、获取模块,用于获取音频数据;
29、处理模块,用于处理所述音频数据,生成音频特征数据;
30、分析模块,用于利用时域和频域分析所述音频特征数据,生成综合特征数据;
31、训练模块,用于将所述综合特征数据输入至预先训练的音频情绪分析模型,生成情绪特征;
32、生成模块,用于将所述综合特征数据和所述情绪特征输入至预先训练的面部控制参数生成模型,生成面部控制参数;
33、驱动模块,用于基于面部控制参数驱动数字人面部表情。
34、第三方面,本发明实施例提供了一种智能设备,该设备包括:
35、处理器,以及与所述处理器相连接的存储器;
36、所述存储器用于存储计算机程序,所述计算机程序至少用于实现如本发明实施例第一方面所述的基于音频识别驱动数字人面部表情的方法中各个步骤;
37、所述处理器用于调用并执行所述存储器中的所述计算机程序。
38、本发明首先处理音频数据生成的音频特征数据,之后利用时域和频域分析所述音频特征数据,生成综合特征数据,结合使用预先训练的音频情绪分析模型,将综合特征数据中附带的情绪特征分析出来,将情绪特征和综合特征数据输入至预先训练的面部控制参数生成模型,生成面部控制参数,如此,在生成面部控制参数的过程中,充分考虑了情绪特征,使得基于面部控制参数驱动数字人面部表情时,数字人面部表情可以充分的体现音频数据中包含的情绪,使得面部动作更加生动形象,真实反映目标用户的真实面部表情动作。
技术特征:
1.一种基于音频识别驱动数字人面部表情的方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述基于面部控制参数驱动数字人面部表情包括:
3.根据权利要求1所述的方法,其特征在于,还包括:
4.根据权利要求1或3所述的方法,其特征在于,所述处理所述音频数据,生成音频特征数据包括:
5.根据权利要求4所述的方法,其特征在于,所述降采样操作包括:
6.根据权利要求4所述的方法,其特征在于,包括:
7.根据权利要求4所述的方法,所述音频特征包括:
8.根据权利要求1所述的方法,所述情绪特征包括:
9.一种基于音频识别驱动数字人面部表情的装置,其特征在于,包括:
10.一种智能设备,其特征在于,包括:
技术总结
本发明涉及一种基于音频识别驱动数字人面部表情的方法,该方法包括:获取音频数据;处理所述音频数据,生成音频特征数据;利用时域和频域分析所述音频特征数据,生成综合特征数据;将所述综合特征数据输入至预先训练的音频情绪分析模型,生成情绪特征;将所述综合特征数据和所述情绪特征输入至预先训练的面部控制参数生成模型,生成面部控制参数;基于面部控制参数驱动数字人面部表情。以解决现有技术中在目标角色上展现的面部动作与实际状态不符,面部生硬的问题。
技术研发人员:胡强,朱桐贤
受保护的技术使用者:北京盈锋科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!