一种基于音源分离的歌声优化方法、装置、设备及介质与流程
本发明涉及人工智能,尤其涉及一种基于音源分离的歌声优化方法、装置、设备及介质。
背景技术:
1、在医疗领域,音乐疗法是一种无创伤性的治疗方法,对治疗睡眠障碍、焦虑、注意力不集中由于没有副作用,因此深受广大患者欢迎。通过获取不同人的歌声,并对获取到的歌声进行优化,得到多样化的歌声音乐,其中,歌声优化是指能够将非专业歌唱者唱出的非专业歌声进行优化,这个优化具体是指修正歌声的调性,即将歌声中跑调的部分调整至正确的音调上,同时提升歌唱者的情感表达力度,增加歌声的感染力。随着深度学习技术的发展,ai驱动的歌声优化方法已逐渐成为一个新的研究方向,吸引了大量来自学术界和工业界的目光。
2、现有技术中,解决歌声优化的方法大致分成两种,第一种由专业的音频工程师使用昂贵的商业调音软件进行歌声的调整;第二种预先设定好当前歌曲的音调的模版,然后歌唱时,将歌声的音调直接调整为模版音调。第一种方法,专业的音频工程师非常稀少,而且很难做到实时性,第二种方法很容易造成歌曲的歌唱风格同质化严重,不利于歌曲的多样化演奏。所以现有技术中的歌声优化方法存在优化效果较差的问题,因此,如何提高歌声优化中的优化效果成为亟待解决的问题。
技术实现思路
1、有鉴于此,本申请实施例提供了一种基于音源分离的歌声优化方法、装置、终端设备及介质,以解决现有技术中的歌声优化方法存在优化效果较差的问题。
2、第一方面,本申请实施例提供一种基于音源分离的歌声优化方法,所述歌声优化方法包括:
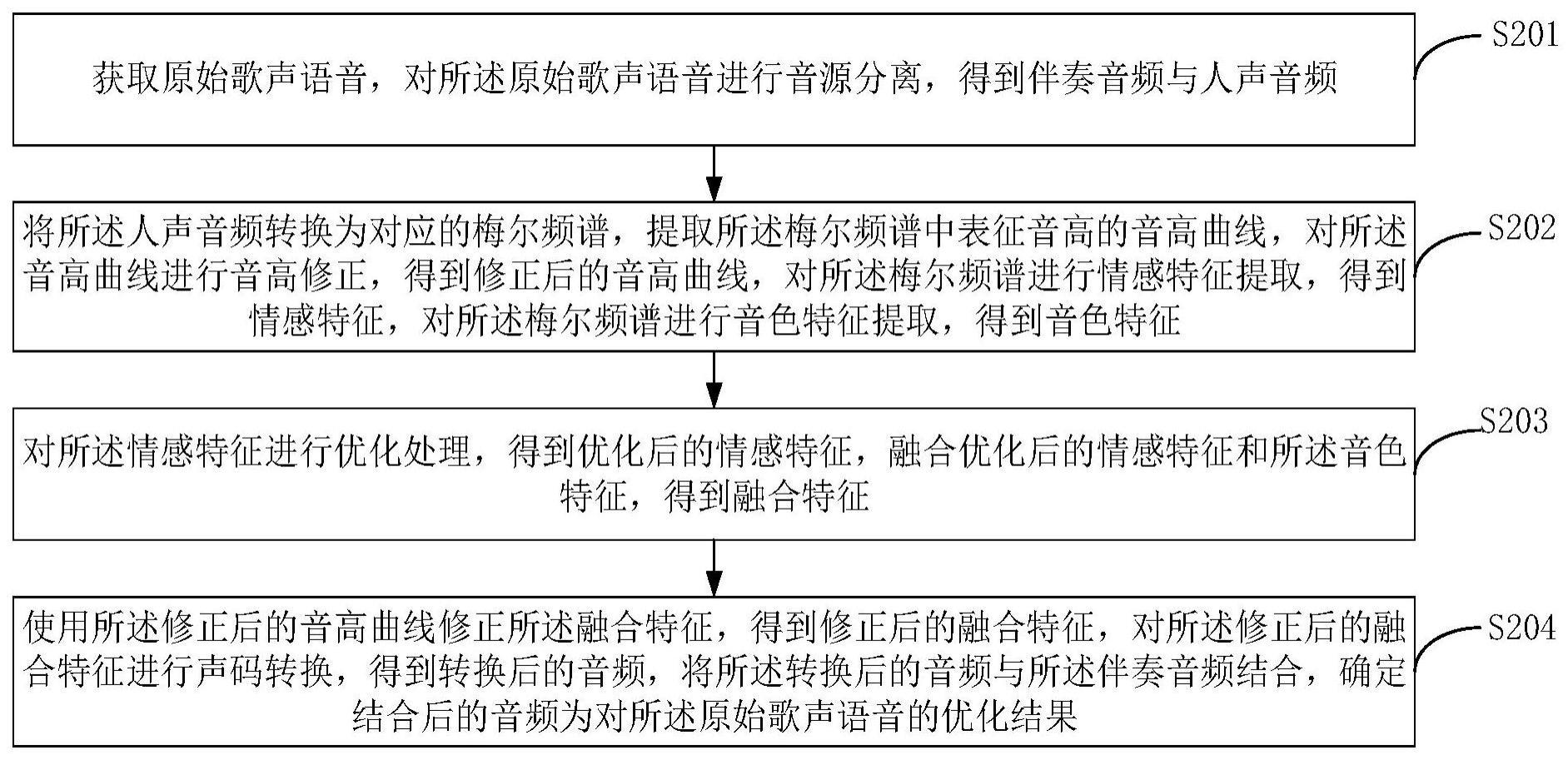
3、获取原始歌声语音,对所述原始歌声语音进行音源分离,得到伴奏音频与人声音频;
4、将所述人声音频转换为对应的梅尔频谱,提取所述梅尔频谱中表征音高的音高曲线,对所述音高曲线进行音高修正,得到修正后的音高曲线,对所述梅尔频谱进行情感特征提取,得到情感特征,对所述梅尔频谱进行音色特征提取,得到音色特征;
5、对所述情感特征进行优化处理,得到优化后的情感特征,融合优化后的情感特征和所述音色特征,得到融合特征;
6、使用所述修正后的音高曲线修正所述融合特征,得到修正后的融合特征,对所述修正后的融合特征进行声码转换,得到转换后的音频,将所述转换后的音频与所述伴奏音频结合,确定结合后的音频为对所述原始歌声语音的优化结果。
7、第二方面,本申请实施例提供一种基于音源分离的歌声优化装置,所述歌声优化装置包括:
8、获取模块,用于获取原始歌声语音,对所述原始歌声语音进行音源分离,得到伴奏音频与人声音频;
9、提取模块,用于将所述人声音频转换为对应的梅尔频谱,提取所述梅尔频谱中表征音高的音高曲线,对所述音高曲线进行音高修正,得到修正后的音高曲线;对所述梅尔频谱进行情感特征提取,得到情感特征,对所述梅尔频谱进行音色特征提取,得到音色特征;
10、优化模块,用于对所述情感特征进行优化处理,得到优化后的情感特征,融合优化后的情感特征和所述音色特征,得到融合特征;
11、结合模块,用于使用所述修正后的音高曲线修正所述融合特征,得到修正后的融合特征,对所述修正后的融合特征进行声码转换,得到转换后的音频,将所述转换后的音频与所述伴奏音频结合,确定结合后的音频为对所述原始歌声语音的优化结果。
12、第三方面,本申请实施例提供一种终端设备,所述终端设备包括处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如第一方面所述的基于音源分离的歌声优化方法。
13、第四方面,本申请实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的基于音源分离的歌声优化方法。
14、本发明与现有技术相比存在的有益效果是:
15、获取原始歌声语音,对原始歌声语音进行音源分离,得到伴奏音频与人声音频,将人声音频转换为对应的梅尔频谱,提取梅尔频谱中表征音高的音高曲线,对音高曲线进行音高修正,得到修正后的音高曲线,对梅尔频谱进行情感特征提取,得到情感特征,对梅尔频谱进行音色特征提取,得到音色特征,对情感特征进行优化处理,得到优化后的情感特征,融合优化后的情感特征和音色特征,得到融合特征,使用修正后的音高曲线修正融合特征,得到修正后的融合特征,对修正后的融合特征进行声码转换,得到转换后的音频,将转换后的音频与伴奏音频结合,确定结合后的音频为对原始歌声语音的优化结果。本发明中,将对应的歌声语音进行音源分离,将伴奏音频与人声音频分离出来,分别提取人声音频中的音高曲线,情感特征以及音色特征,进行修正与优化,提高了歌声优化的合理性,对音高特征进行修正,对情感特征进行优化,提高了歌声的优化程度,所以使用本发明中的歌声优化方法可以提高歌声优化的优化效果。在医疗领域中音乐疗法中,优化后的音乐情感更准确,更助于患者的治疗。
技术特征:
1.一种基于音源分离的歌声优化方法,其特征在于,所述歌声优化方法包括:
2.如权利要求1所述的歌声优化方法,其特征在于,所述获取原始歌声语音,对所述原始歌声语音进行音源分离,得到伴奏音频与人声音频,包括:
3.如权利要求1所述的歌声优化方法,其特征在于,所述将所述人声音频转换为对应的梅尔频谱,包括:
4.如权利要求1所述的歌声优化方法,其特征在于,所述对所述音高曲线进行音高修正,得到修正后的音高曲线,包括:
5.如权利要求1所述的歌声优化方法,其特征在于,所述对所述情感特征进行优化处理,得到优化后的情感特征,包括:
6.如权利要求1所述的歌声优化方法,其特征在于,所述对所述修正后的融合特征进行声码转换,得到转换后的音频,包括:
7.如权利要求1所述的歌声优化方法,其特征在于,所述将所述转换后的音频与所述伴奏音频结合,确定结合后的音频为对所述原始歌声语音的优化结果,包括:
8.一种基于音源分离的歌声优化装置,其特征在于,所述歌声优化装置包括:
9.一种终端设备,其特征在于,所述终端设备包括处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至7任一项所述的歌声优化方法。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述的歌声优化方法。
技术总结
本发明涉及人工智能技术领域,尤其涉及一种基于音源分离的歌声优化方法、装置、设备及介质。上述方法应用于医疗领域,提取原始歌声语音中的人声音频中表征音高的音高曲线,情感特征与音色特征,对音高曲线进行音高修正,对情感特征进行优化处理,融合优化后的情感特征和音色特征,得到融合特征,使用修正后的音高曲线修正融合特征,对修正后的融合特征进行声码转换,将转换后的音频与伴奏音频结合,本发明中,分别提取人声音频中的音高曲线,情感特征以及音色特征,进行修正与优化,提高了歌声优化的合理性,对音高特征进行修正,对情感特征进行优化,提高了歌声的优化程度,所以使用本发明中的歌声优化方法可以提高歌声优化的优化效果。
技术研发人员:张旭龙,王健宗,程宁,茹港徽
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!